- The paper presents a rigorous resource analysis showing that amplitude encoding incurs exponential initialization and measurement overhead compared to more scalable quasi-classical methods.
- It derives closed-form expressions for circuit depth and empirically validates that measurement scaling for amplitude encoding follows a 2^n log(2^n) pattern via Qiskit simulations.
- The study highlights that hybrid encoding—combining bitstring for local nonlinear operations and amplitude methods for parallelization—is essential for efficient quantum Lattice Boltzmann simulations.
Resource Analysis and Encoding Strategies for Quantum Computational Fluid Dynamics
Introduction
The paper "Resource Implications of Different Encodings for Quantum Computational Fluid Dynamics" (2604.05577) systematically examines how encoding choices for quantum representations—specifically, amplitude encoding, 1-qubit amplitude encoding, and bitstring encoding—critically influence both initialization and read-out resource requirements in quantum algorithms for CFD. While the compactness of amplitude encoding is often emphasized, the operational overhead, particularly for unstructured quantum states, has not been quantified with sufficient detail. This work rigorously derives new bounds for circuit depth and sampling complexity associated with amplitude encoding, conducts empirical calibration via Qiskit simulations, and examines scalability and practicality of each scheme for time-resolved CFD workflows, notably in the context of the lattice Boltzmann method (LBM).
Encoding Schemes: Structural and Resource Considerations
The analysis begins with a formal taxonomy of quantum encoding schemes:
- General amplitude encoding: encodes 2n reals (or complex values) in the amplitudes of n qubits, fully leveraging quantum superposition and entanglement. Read-out requires stochastic projective measurements.
- 1-qubit amplitude encoding: each qubit individually encodes a two-level scalar, yielding separable product states (no entanglement).
- Bitstring encoding: fully classical data mapping, each basis state encodes a single number in binary representation, matching the conventions of classical digital hardware.
While amplitude encoding is viewed as information-theoretically optimal in terms of logical data density, the paper identifies that for most CFD scenarios—where entire fields must be re-encoded and re-extracted over sequential timesteps—the cost of both preparation and measurement can dominate algorithm runtime.
Circuit Depth and Initialization Complexity
A tight analysis of the amplitude encoding initialization procedure, following the construction of Shende et al., is carried out. The authors provide exact gate counts and circuit depths in terms of qubit number n, decomposed into Ry, Rz, and CX-gate layers. The circuit depth for initializing an arbitrary state scales exponentially in n: the Rj-rotation (1-qubit) gates and CX-gates contributions are
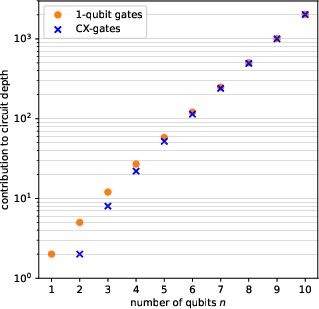
Figure 2: Circuit depth contributions due to Rj-rotation gates and CX-gates for general amplitude encoding initialization.
The explicit closed-form expressions derived are:
- Depth from 1-qubit rotations: 2n+1−(n+1)
- Depth from CX-gates: 2n+1−2(n+1)
Empirical Qiskit-based simulations on the IBM Sherbrooke backend are compared to these analytical predictions, confirming exponential scaling and minor deviations attributable to backend-specific optimizations.
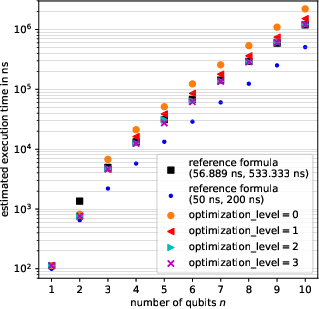
Figure 4: Empirical execution time estimates for initialization routines compared to the analytical reference formula over increasing n0.
For quasi-classical encodings (1-qubit amplitude and bitstring), initialization depth is constant and independent of system size due to full separability.
Measurement and Read-Out Scaling
The work advances a theoretical upper bound for the number of quantum circuit executions (shots) required to estimate all probability amplitudes to additive or relative error n1 with high probability (n2). For amplitude encoding over n3 qubits, the union bound combined with Hoeffding's inequality gives:
n4
for inferring each element of the n5 distribution up to relative error n6, with probability at least n7. Empirical studies reveal that this is a pessimistic (loose) upper bound; actual instance-wise sampling requirements in the reference case (uniform distribution across outcomes) scale closer to n8, in line with coupon collector heuristics (see Figure 5).
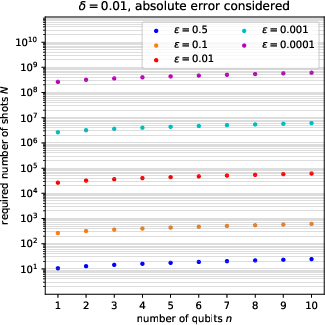
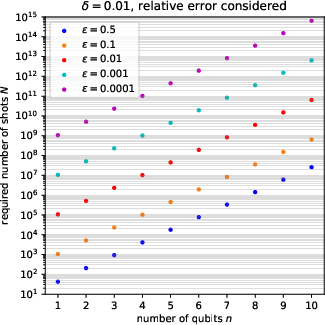
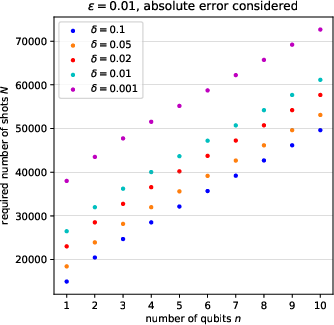
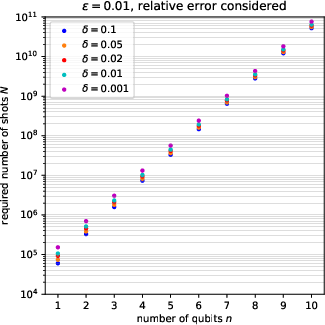
Figure 7: Required number of shots n9 for a range of error and confidence parameters; empirical results confirm significant slack in the union-bound-derived upper bound.
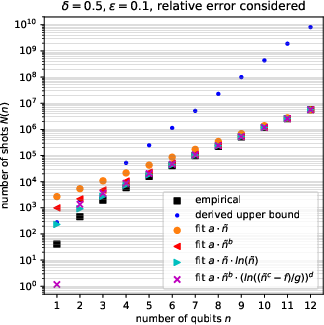
Figure 8: Empirical measurement shows n0 more closely fits the required shots for bounded relative error, much better than the pessimistic n1 scaling.
The implication is that for amplitude-encoded representations, read-out cost can quickly outpace any polynomial quantum speedup unless only a small number of derived observables are to be measured, or postselection/amplitude amplification is employed.
Bitstring Encoding and Nonlinear Operation Realization
Amplitude encoding fundamentally restricts transformation to linear, unitary processes. However, for LBM and other nonlinear PDE solvers, implementing local nonlinear collision rules efficiently is critical. The appendix demonstrates that, via bitstring encoding, arbitrary classical functions (including nonlinear mappings) can be implemented with quantum circuits using ancilla registers, multi-controlled X/CX gates, and SWAP/reset operations. Minimal examples (e.g., bitwise mapping to approximate n2) illustrate this approach, showing full compatibility with classical dataflow and functional manipulation.
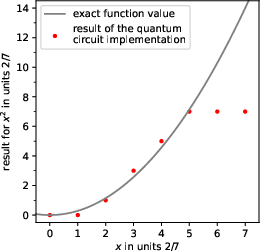
Figure 10: Statevector simulation results for a quantum circuit mapping input bitstrings to approximate n3 nonlinearity, demonstrating classical function realization in a quantum context.
Implications for the Lattice Boltzmann Method: Hybrid Encoding
A new encoding architecture is detailed for LBM: the 'bottom level' (collision/local states) uses bitstring representation, enabling arbitrary (including nonlinear) logic for local updates, while the 'top level' employs a structure akin to amplitude encoding for indexing grid points and managing communication (streaming). The streaming operation is shown to be non-unitary (even non-linear) if formulated as in a naïve entangled state model; this motivates the use of augmented bitstring ensembles, as in Schalkers and Möller [23], to ensure validity under quantum evolution and efficient transfer between local states.
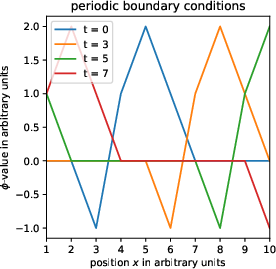
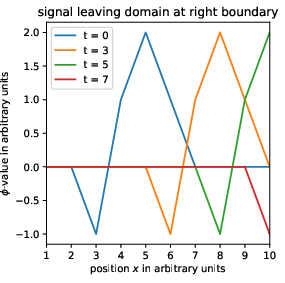
Figure 12: Simulation of Bernstein-Vazirani-like quantum circuits, supporting direct bitstring encoding for grid-point-wise updates and communication.
This layered approach naturally matches the structure of LBM, where local nonlinear updates and nonlocal linear streaming can be decoupled in encoding, supporting more efficient quantum-classical algorithm hybrids.
Practical and Theoretical Implications
- Initialization and read-out overheads: Amplitude encoding exponentially increases preparation and measurement requirements with the field size, eroding any computational advantage in scenarios requiring full-field extraction at every time step (as in transient CFD or aeroacoustics).
- Attainable speedup: Stand-alone amplitude-encoded quantum algorithms may only yield practical advantages when only a small set of global observables are needed, or as subroutines in hybrid quantum-classical solvers where re-initialization and full read-out are unnecessary.
- Hybrid encoding recommendation: For general nonlinear PDEs (e.g., LBM for turbulent flows), schemes leveraging bitstring encoding for local physics and structured amplitude encoding for parallelization/indexing are favored. Local nonlinear operations are implementable with polynomial-depth quantum circuits enabled by ancilla qubit resources and classical logic.
- Initialization remains a bottleneck: While the proposed schemes reduce measurement penalty, efficient initialization of highly structured entangled states matching CFD field data remains an unresolved challenge.
- Scalability and fault tolerance: The hardware coherence times of current superconducting qubits (tens of microseconds) and two-qubit gate durations will limit the maximal realizable field size before decoherence unless resource-efficient, low-depth encodings and parallelization are achieved.
Conclusion
This study provides the most detailed resource analysis to date regarding the initialization and measurement costs of quantum data encodings relevant to CFD, showing that resource-optimal amplitude encoding is operationally prohibitive for large-scale direct field simulation. Empirically validated bounds for measurement accuracy, and rigorous gate count/circuit depth analysis, clarify the conditions under which quantum CFD algorithms may be competitive with classical approaches.
Hybrid encoding schemes, in which bitstring encoding is used for local nonlinear physics and a structured amplitude index register is used for moderate parallelization, are identified as the best path forward for quantum LBM. This work forms a blueprint for realistic expectations and future developments in the engineering of quantum CFD solvers, highlighting the necessity of co-designing quantum algorithms and data encodings to match hardware and physical model constraints.
References
All statements, figures, and derivations are based on or directly referenced from "Resource Implications of Different Encodings for Quantum Computational Fluid Dynamics" (2604.05577).

