- The paper introduces HCL, a contrastive framework that decomposes multimodal data into globally shared, partially shared, and modality-specific latent components.
- It employs a hierarchical contrastive loss to align structure-specific representations across modalities while enforcing robust disentanglement and sparsity.
- Empirical validations on synthetic and EHR datasets, along with theoretical guarantees, demonstrate improved recovery and superior downstream prediction performance.
Hierarchical Contrastive Learning for Multimodal Data: A Technical Overview
Introduction and Motivation
The traditional paradigm in multimodal representation learning relies on a shared-private decomposition, where features are either shared by all modalities or exclusive to one. However, this binary framework fails to capture the nuanced dependencies frequently observed in real-world multimodal data, where particular latent factors are shared across subsets of modalities (partial sharing). The paper "Hierarchical Contrastive Learning for Multimodal Data" (2604.05462) introduces a principled framework—Hierarchical Contrastive Learning (HCL)—that systematically models globally shared, partially shared, and modality-specific latent structures within a unified contrastive learning architecture. This approach provides identifiable decompositions, explicit alignment objectives, and strong statistical guarantees for both representation learning and downstream prediction tasks.
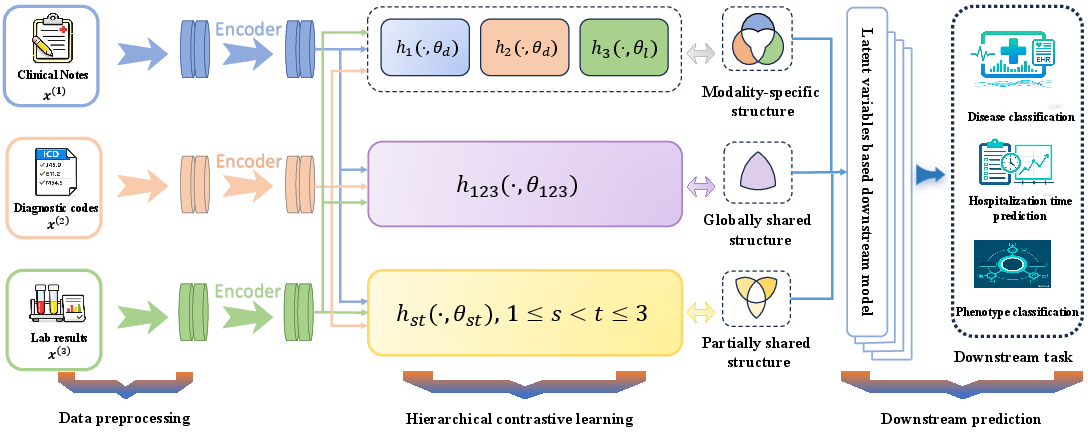
Figure 1: Overall framework of Hierarchical Contrastive Learning. Each encoder recovers a specific latent structure, illustrated using EHR data.
Hierarchical Latent Structure and Decomposition
The core modeling innovation is the hierarchical decomposition of the latent space. Given M modalities, the set of latent structures is organized into three levels:
- Level 1: Globally shared components (S1), present in all modalities.
- Level 2: Partially shared components (S2), present in strict subsets of modalities.
- Level 3: Modality-specific components (S3), unique to one modality.
For illustration, with three modalities, the full hierarchical structure includes one global ({1,2,3}), three pairwise shared ({1,2},{1,3},{2,3}), and three private ({1},{2},{3}) components. Each modality's observation is modeled as a sum of contributions from the relevant latent factors, transformed by modality-specific loading matrices and passed through (possibly nonlinear) link functions.
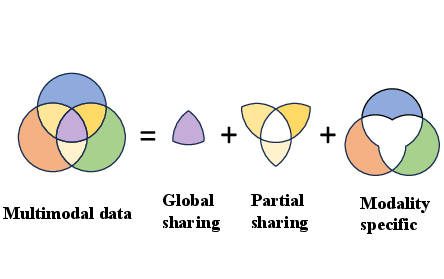
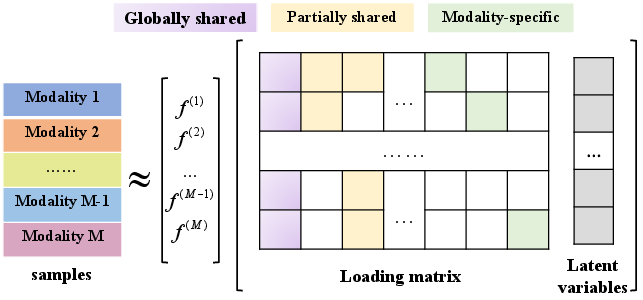
Figure 2: Hierarchical decomposition for multimodal data, separating globally shared, partially shared, and modality-specific components.
This model generalizes deterministic matrix decomposition methods to a more flexible latent variable framework, allowing extension to nonlinear settings and substantially weaker assumptions (notably, only uncorrelated rather than orthogonal latent variables are required).
Hierarchical Contrastive Objective
The representational goal is to learn encoders hs(m) that extract structure-specific representations from each modality, mapped into a common, interpretable latent space. The hierarchical contrastive loss explicitly aligns representations belonging to the same structure and sample across modalities (positive pairs), while suppressing similarity between different samples (negative pairs), enforcing disentanglement among latent structures.
The loss function consists of:
- Contrastive alignment between representations for each structure, aggregating only those modality pairs that truly share the structure.
- Structural regularization to enforce sparsity and disentanglement, penalizing cross-structure similarity within each modality.
This mechanism is compatible with nonlinear parametrization of encoders and similarity metrics, permitting direct application to high-capacity neural architectures.
Theoretical Properties
Identifiability and Recovery Guarantees
The paper provides rigorous identifiability results for the hierarchical model, establishing that, under invertible link functions and mild assumptions (uncorrelated zero-mean, unit-covariance latent factors), all model parameters are identifiable up to arbitrary structure-wise orthogonal transformations. Recovery guarantees for both the global and block-wise loading matrices are derived, providing non-asymptotic error bounds in spectral, Frobenius, and two-infinity norms. Notably, these results are obtained under broad conditions, e.g., only requiring μ-incoherence of the loadings and sub-Gaussian noise, and are aligned with rates known for unstructured low-rank recovery.
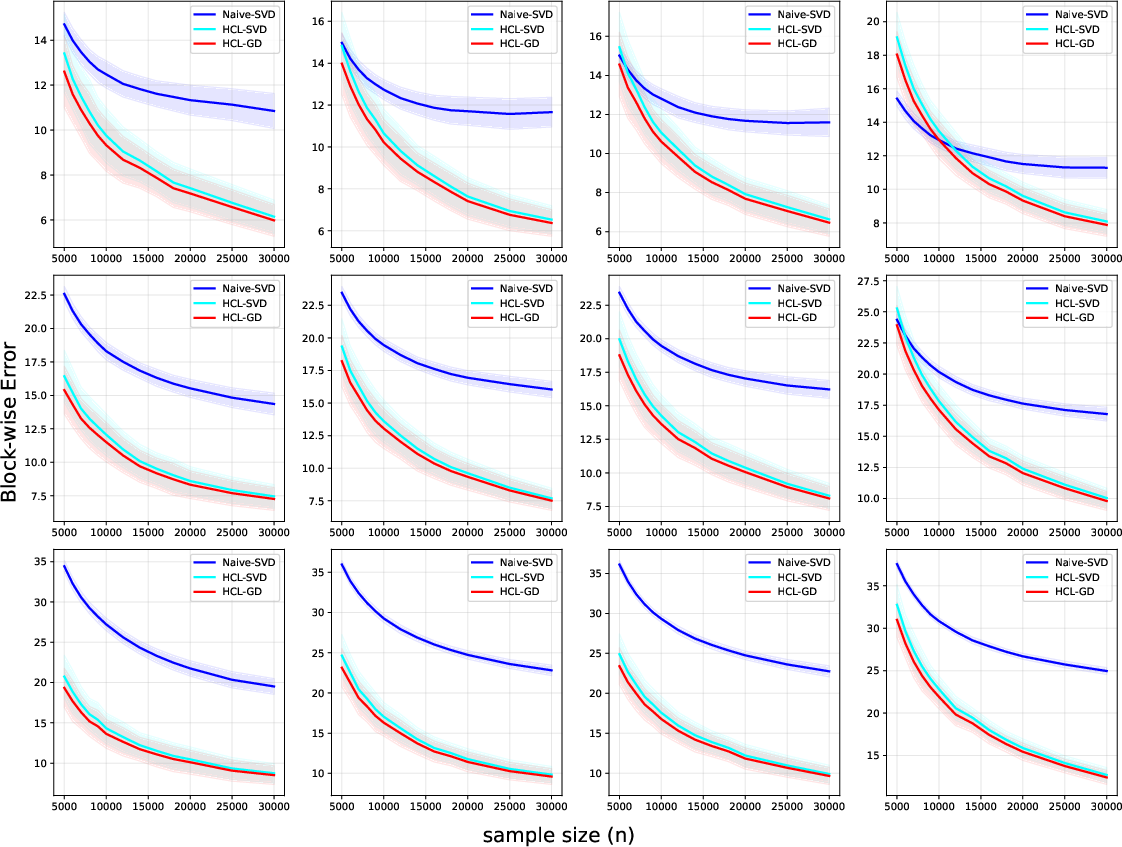
Figure 3: Block matrices error of the HCL framework as a function of unlabeled sample size for different modality dimensions.
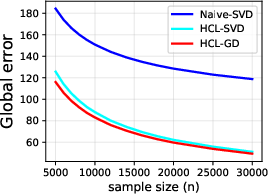
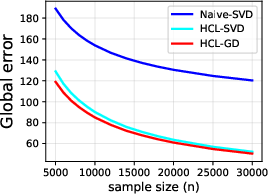
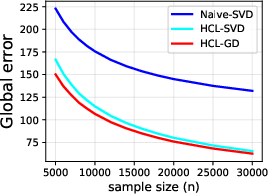
Figure 4: Global matrix error of the HCL framework versus unlabeled sample size, demonstrating consistent error decay.
Downstream Estimation and Prediction Bounds
The framework connects the learned latent representations to linear regression downstream tasks, incorporating a group Lasso penalty to promote block-level sparsity (identifying relevant latent structures). Theoretical analysis establishes tight non-asymptotic bounds for both parameter estimation and excess prediction risk, reflecting contributions from both representation learning and downstream sample variability. The group-sparse estimator admits block-wise error control, facilitating interpretability and efficient structure selection.
Experimental Results
Simulation Studies
Empirical validation on synthetic data shows that the gradient-based HCL optimizer achieves lower recovery errors for both global and block-wise loadings than naive SVD or prior structured SVD methods. As sample size increases, error diminishes rapidly, paralleling the predicted theoretical rates. In downstream regression, HCL consistently yields lower RMSE, better SMAPE, and higher R2 across all tested regimes, outperforming both deterministic matrix decomposition and prior deep multimodal baselines.
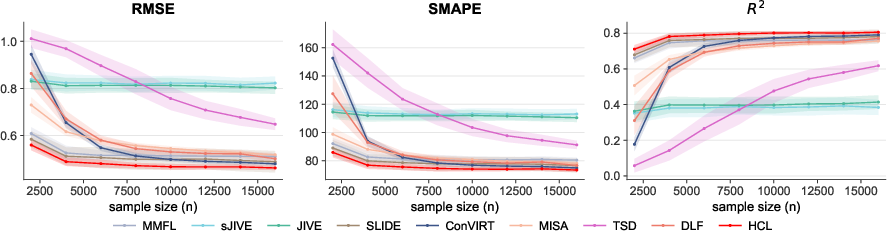
Figure 5: Downstream prediction performance (RMSE, SMAPE, S10) as a function of sample size for multiple methods and noise levels.
Electronic Health Record Application
Applied to a large EHR dataset (MIMIC-IV), HCL demonstrates systematic gains in three distinct clinical prediction tasks:
- 30-day readmission: HCL produces superior AUC, AUPRC, accuracy, and F1, under both joint and pretrain-finetune training strategies.
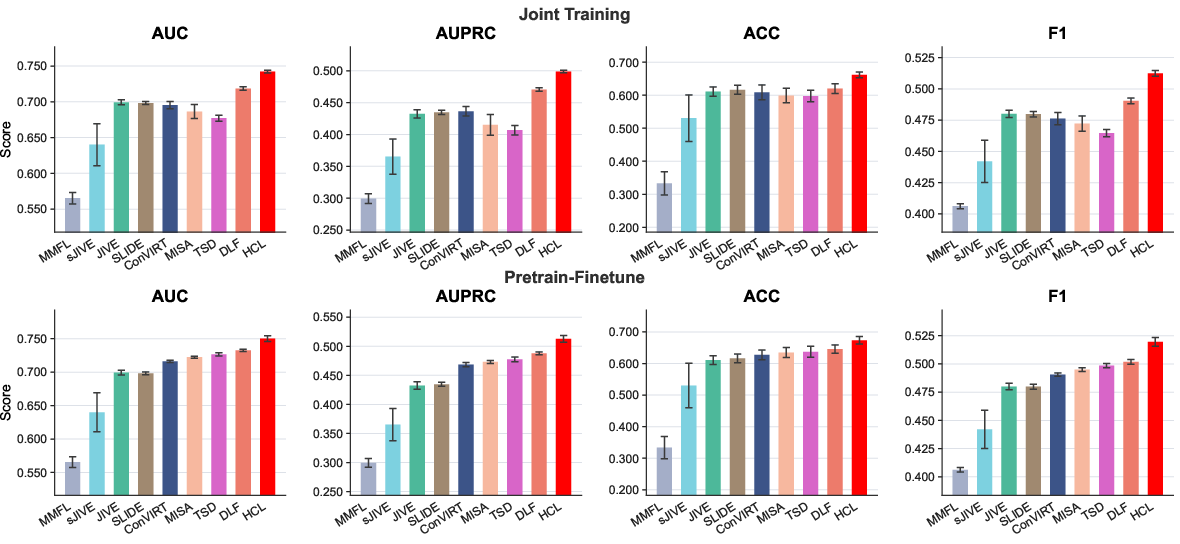
Figure 6: Comparison of methods for 30-day readmission prediction; HCL dominates all baselines across metrics.
- Next-visit length-of-stay: HCL achieves optimal performance in S11 and competitive error metrics.
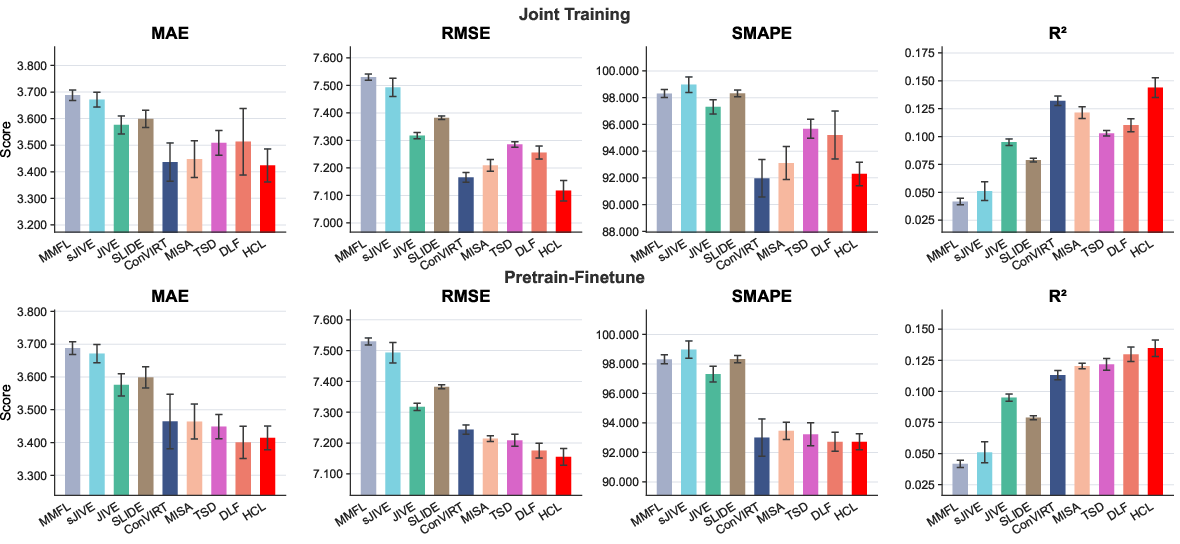
Figure 7: Downstream regression (length-of-stay) performance under both joint and pretrain-finetune schemes.
- One-year mortality: HCL attains the highest AUPRC and F1, indicating robustness in settings sensitive to false positives.
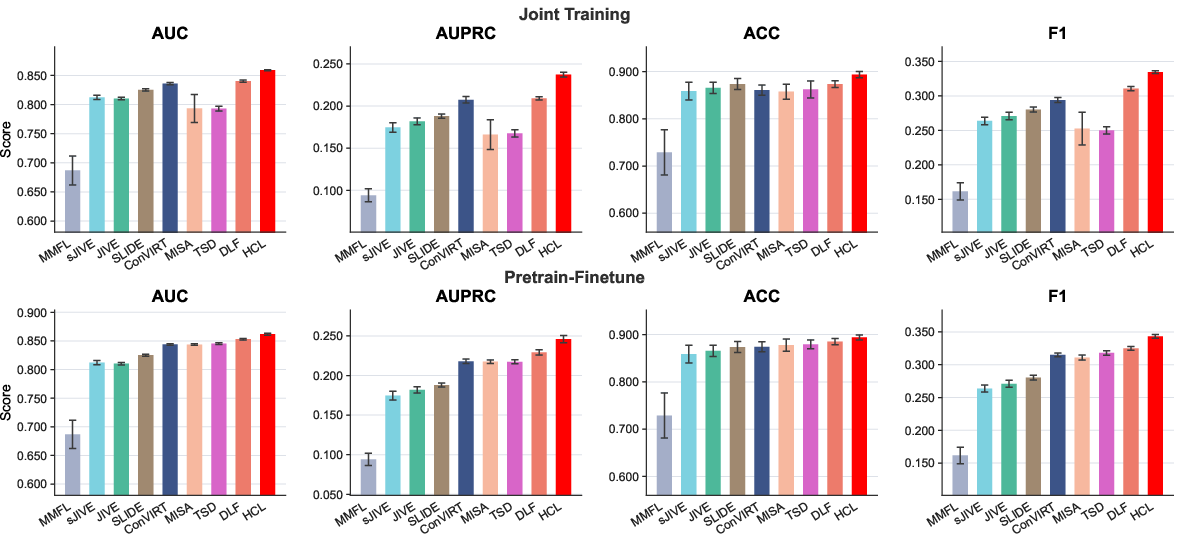
Figure 8: One-year mortality prediction results: HCL outperforms alternatives under all evaluation measures.
Structure ablation experiments quantify the predictive importances of globally shared, partially shared, and modality-specific representations, revealing that the contribution of each structural component varies by task—for instance, global sharing dominates in mortality prediction, whereas readmission depends more on modality-specific signals.
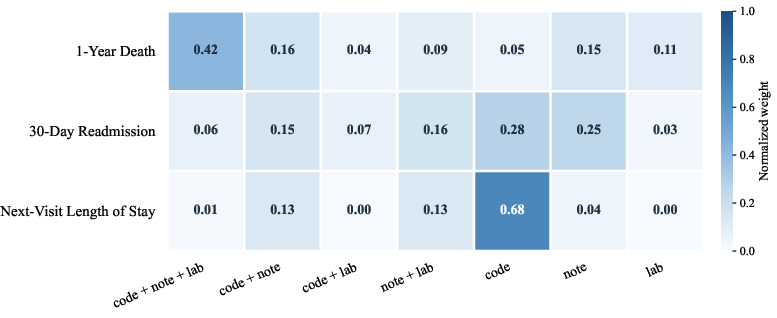
Figure 9: Normalized importance weights of latent structures across the three downstream EHR tasks, highlighting the role of each sharing level.
Implications and Future Directions
Practical Implications
HCL resolves a key representational limitation by natively modeling partial sharing in multimodal data. This enhances interpretability (identifying the specific modality combinations critical for prediction or explanation), improves robustness to missing modalities, and supports principled structure-level ablation and downstream feature selection. The unified loss design enables seamless integration with modern neural architectures and scales favorably with modality count.
Theoretical Significance
The statistical guarantees provided are the first to cover the full hierarchy of shared, partially shared, and modality-specific structures under a probabilistic generative model, extending previous work limited to shared-private decompositions. The framework sets a new benchmark for theoretical rigor in multimodal contrastive representation learning.
Limitations and Future Work
Potential extensions include relaxing the assumption of known invertible link functions (to accommodate unknown or noninvertible transformations and model misspecification), automated selection of structural hierarchy and latent dimensions, application in missing modality or asynchronous data scenarios, and extension to broader classes of downstream outcomes beyond supervised regression/classification (e.g., survival analysis, time-to-event tasks).
Conclusion
Hierarchical Contrastive Learning provides an integrated, theoretically sound, and empirically validated framework for multimodal representation learning that captures the full spectrum of cross-modal sharing. It delivers interpretable, statistically efficient latent representations and yields superior downstream predictive performance, outperforming methods limited to simple shared-private structure. This framework establishes a solid foundation for principled multimodal learning and opens several avenues for further methodological and theoretical advancement.