- The paper introduces a new paradigm (ACG) that cyclically re-anchors generated content to significantly reduce error accumulation in long sequences.
- It employs a novel piano token representation that maps music linearly, mitigating sequence bloat and ensuring spatiotemporal precision.
- The hierarchical Hi-ACG framework achieves superior global coherence and local detail, outperforming conventional AR models in objective and subjective evaluations.
Anchored Cyclic Generation: A Paradigm Shift for Long-Sequence Symbolic Music Generation
Introduction
Long-sequence symbolic music generation remains fundamentally limited by the error accumulation of autoregressive (AR) models, which manifests as degraded structural integrity and musical fluency over time. Despite the widespread adoption of AR methods (RNN/LSTM, Transformer, and diffusion-based architectures), none have effectively tackled the compounding effect of generation errors for extended musical works. The "Anchored Cyclic Generation: A Novel Paradigm for Long-Sequence Symbolic Music Generation" (2604.05343) introduces a robust paradigm, Anchored Cyclic Generation (ACG), and a hierarchical instantiation (Hi-ACG), which together achieve substantial improvements in long-range musical structure, precision, and efficiency.
Piano Token Representation: Efficient Symbolic Compression
The paper departs from standard event-based or ABC symbolic encodings by introducing a "piano token" representation. Piano tokens are constructed by segmenting the piano roll into fixed-sized patches and tokenizing each patch (see Figure 1). This operation achieves a direct, linear mapping between sequence length and musical duration, which is not typically the case with MIDI or event-based vocabularies. Consequently, it significantly mitigates sequence bloat and helps control the accumulation of generation errors while maintaining essential spatiotemporal structure.
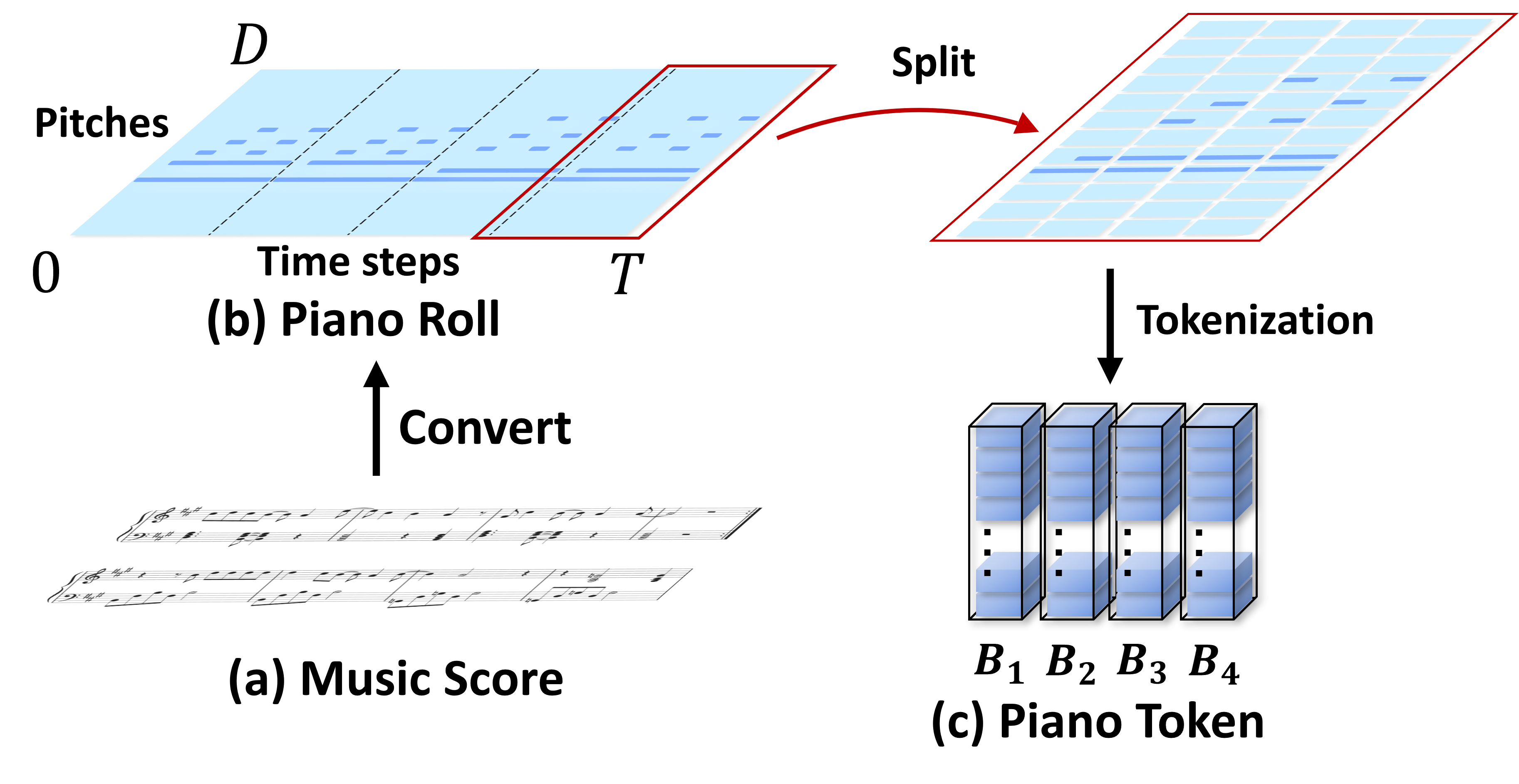
Figure 1: Schematic showing the conversion from musical score through piano roll and into a compact piano token representation suitable for blockwise processing.
Blocks, defined as columns in the token matrix, encapsulate temporally contiguous, harmonically coherent fragments, ensuring that semantic modeling can occur at musically meaningful time scales.
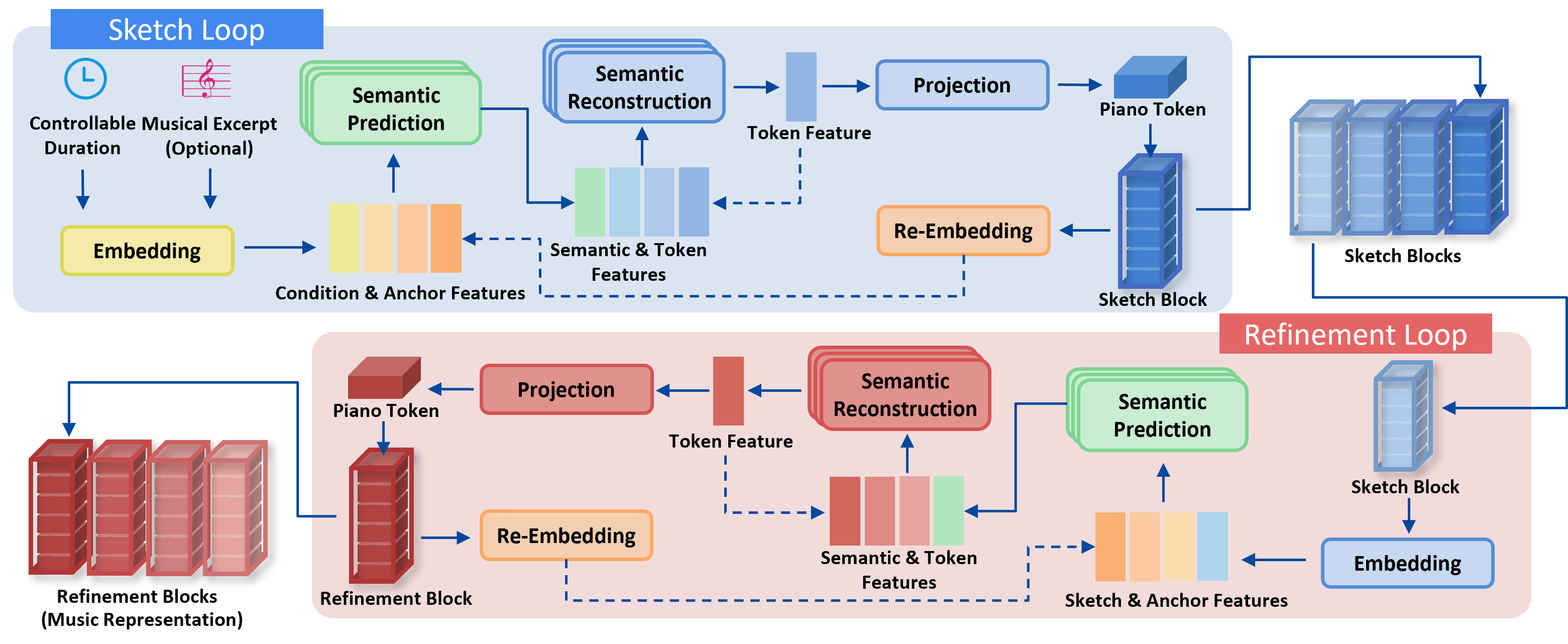
The Anchored Cyclic Generation (ACG) Paradigm
Error accumulation in AR models arises from using only previously predicted states as input for subsequent generation, causing any deviation to compound irrecoverably. ACG resolves this by leveraging "anchor features"—deterministically derived semantic summaries of previously committed musical content—at each time step, thereby cyclically re-grounding the generation process.
Architecturally, ACG interleaves three neural modules:
- Semantic Prediction Model: Predicts the semantic feature zt′ for time t using external conditions and anchor states from all prior blocks.
- Semantic Reconstruction Model: Autoregressively decodes zt′ into a sequence of piano tokens forming the next block.
- Re-Embedding Layer: Re-maps the generated block back into a semantic anchor, which feeds into the next prediction step.
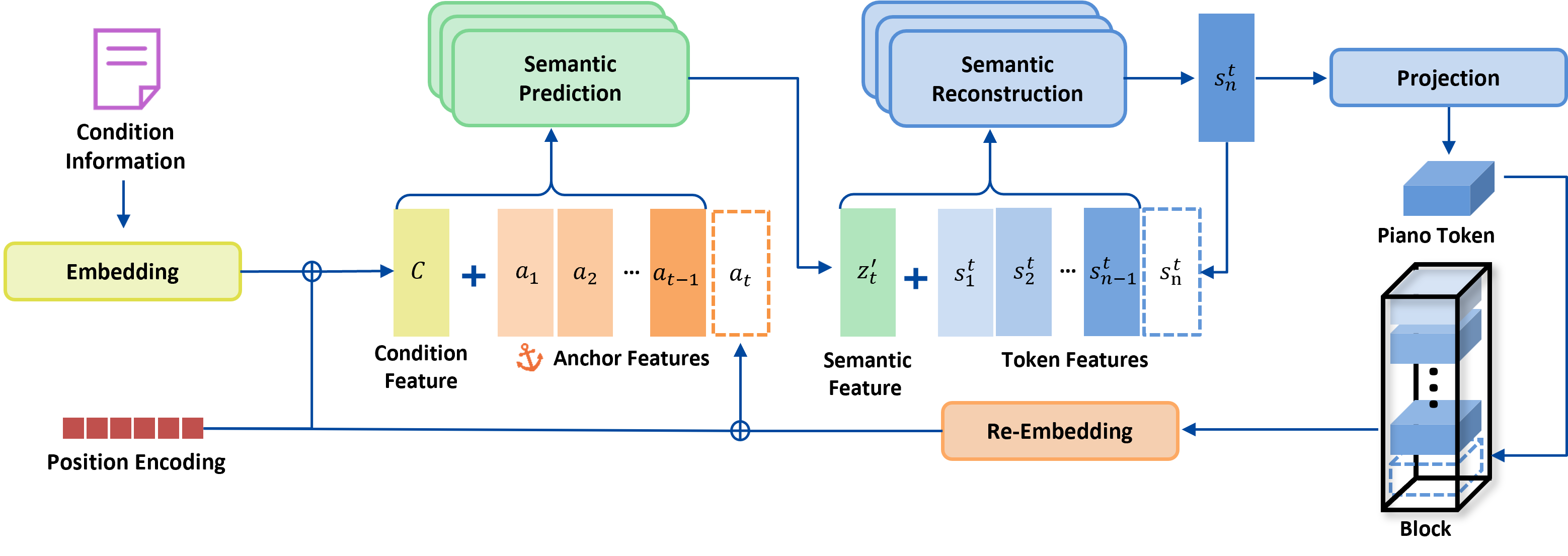
Figure 2: ACG architecture diagram, illustrating the flow from conditions and anchor features through prediction, semantic decoding, and anchor re-embedding for iterative, structurally grounded generation.
Empirically, ACG yields a 34.7% reduction in cosine distance between predicted and ground-truth semantic vectors relative to conventional AR baselines, as shown in feature space comparisons over multiple iterative steps.
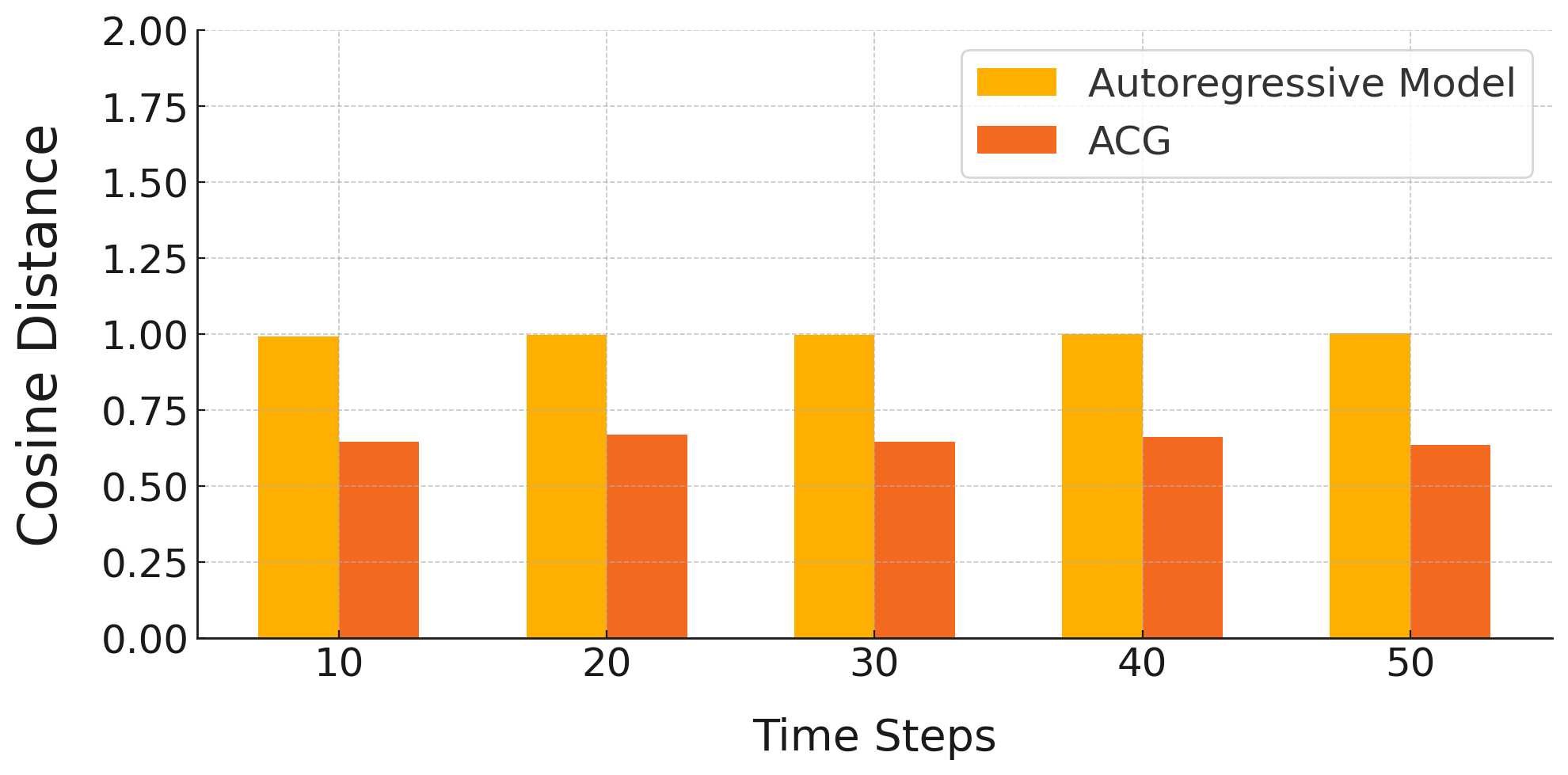
Figure 3: Cosine distances between ACG and AR feature vectors vs. ground truth across iterations; ACG consistently maintains tighter proximity, validating robustness to error accumulation.
Hierarchical Extension: The Hi-ACG Framework
Hi-ACG operationalizes ACG in a two-level cascade:
This global-to-local decomposition endows Hi-ACG with explicit duration control, musically interpretable planning, and the capacity to generate compositions of arbitrary length while maintaining long-range coherence.
Empirical Evaluation
Objective Analysis
The Hi-ACG system was benchmarked against Transformers (Music Transformer, BPE Transformer) and a state-of-the-art diffusion model (Cascaded-Diff) across multiple metrics: pitch entropy, rhythm entropy, harmonicity, melodic smoothness, and an LLM-derived Mean Opinion Score (MOS) as a proxy for subjective musicality.
- For 2-minute unconditional generation, Hi-ACG tightens pitch and rhythm distributions towards ground truth and exhibits the highest LLM MOS ($3.17$ vs. $2.45$ for the best non-hierarchical baseline).
- In conditional continuation tasks, Hi-ACG substantially outperforms both Transformers and diffusion models in terms of harmonic consistency and locality, with superior subjective scores as well.
Subjective Analysis
In a blinded MOS study with musically trained raters, Hi-ACG produced compositions rated almost on par with human data and well above AR and diffusion-based models, demonstrating real-world perceptual advantages over conventional methods.
Scalability and Robustness
The ACG paradigm features improved time complexity: standard AR models have O(L2) scaling, whereas ACG is O(Lsem2)+Lsem×O(Lrec2) (with Lsem sequence of blocks and Lrec local tokens), making it amenable to ultra-long sequence generation. Extended cosine distance analyses over 50 and 100 steps confirm the sustained superiority of ACG (see Figures 5 and 6).
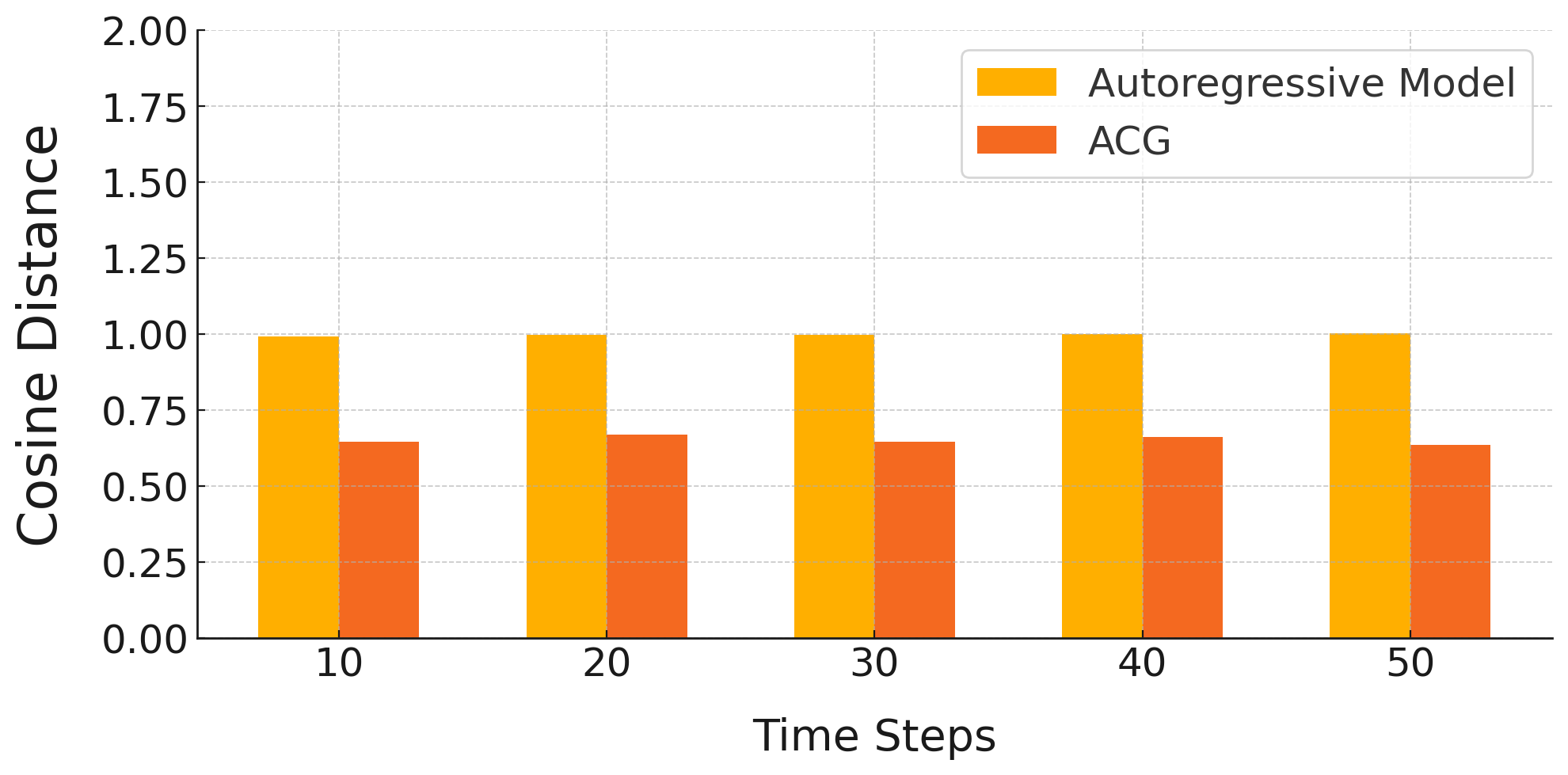
Figure 5: Cosine distance profiles for 50 iterative steps, illustrating extended error control.
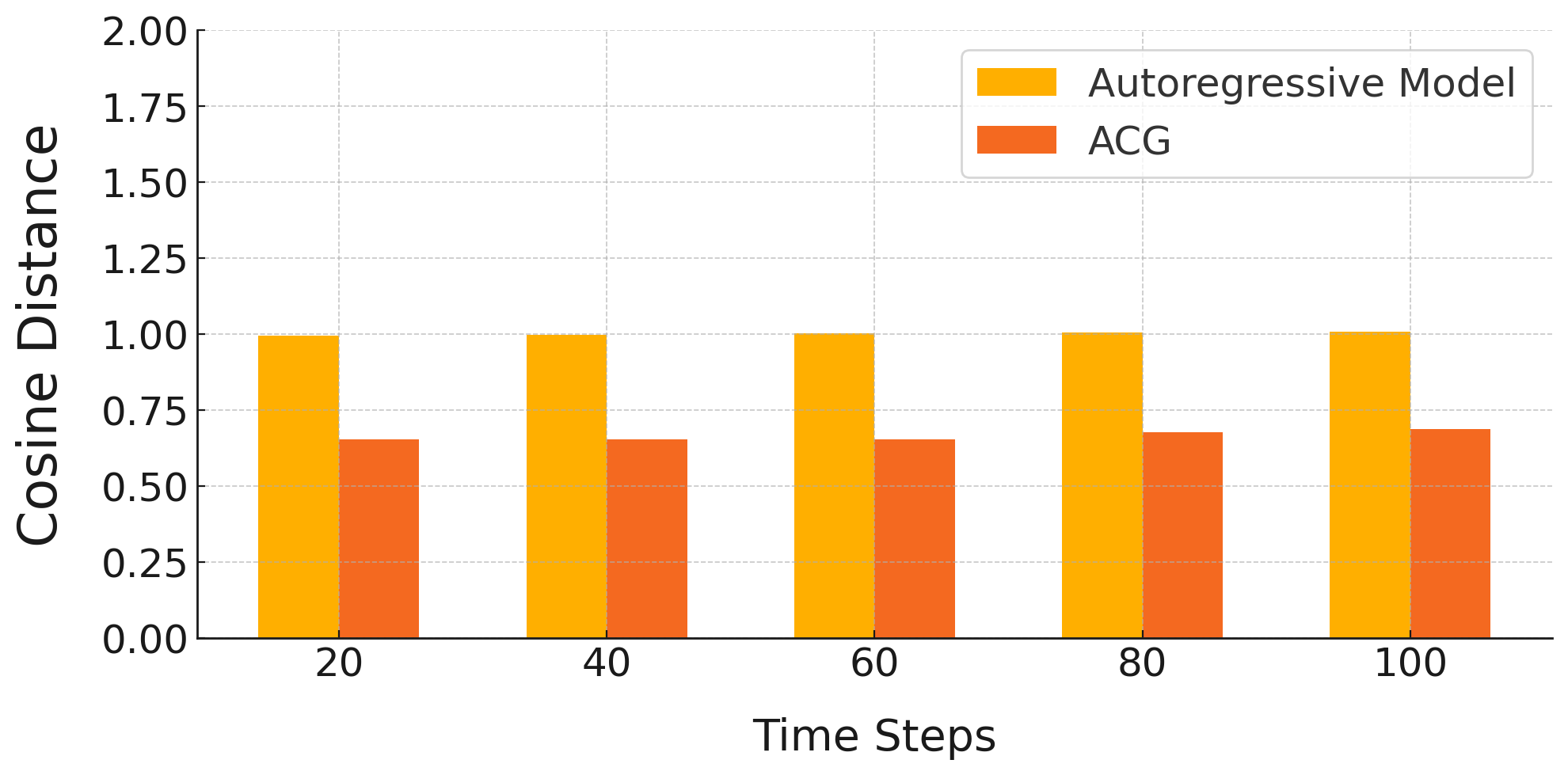
Figure 6: Cosine distance profiles for 100 steps, further highlighting sustained mitigation of error accumulation.
Qualitative Generation Examples
Examples of music generated by Hi-ACG for both 30-second (Figure 7) and 2-minute (Figures 8 and 9) targets—both unconditional and conditional—demonstrate structurally coherent and locally expressive output. These visualizations (piano roll plots) corroborate the system's fluency and capability for detailed stylistic control.
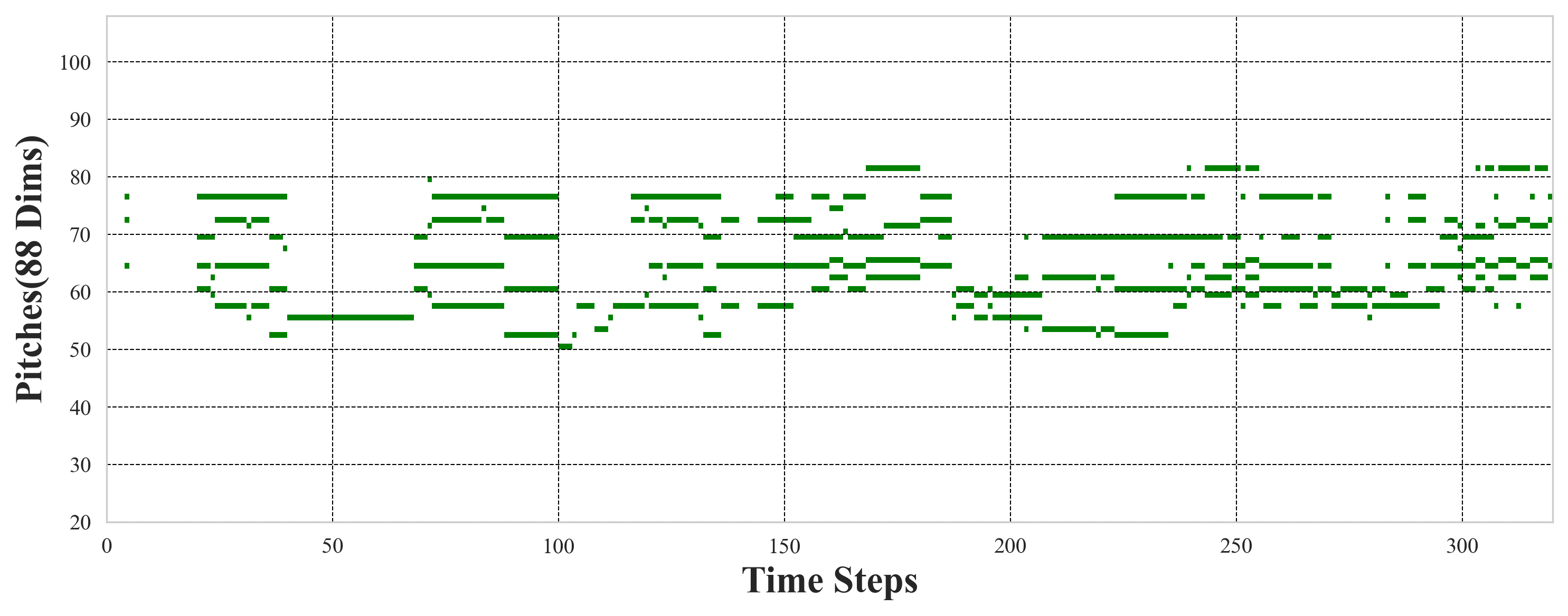
Figure 7: Piano roll visualization of a 30-second musical piece generated by Hi-ACG.
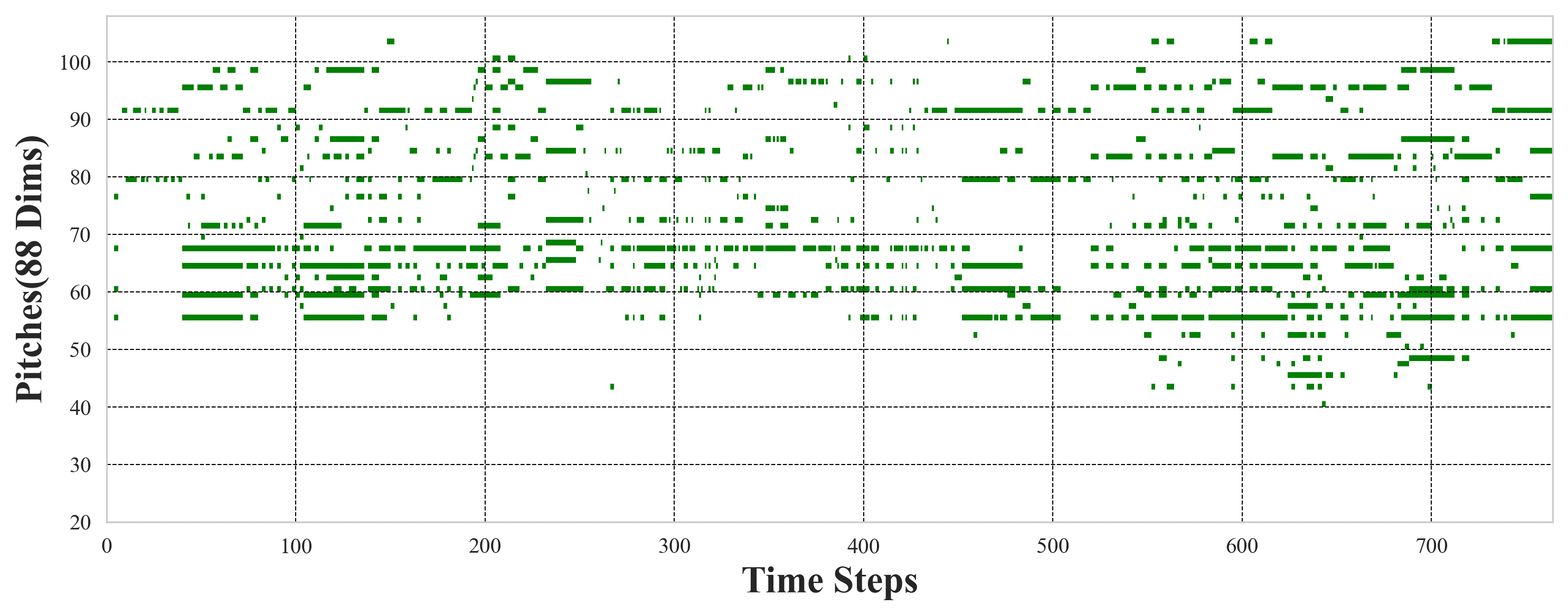
Figure 8: Hi-ACG-generated 2-minute unconditional music, demonstrating extended structure and coherence.
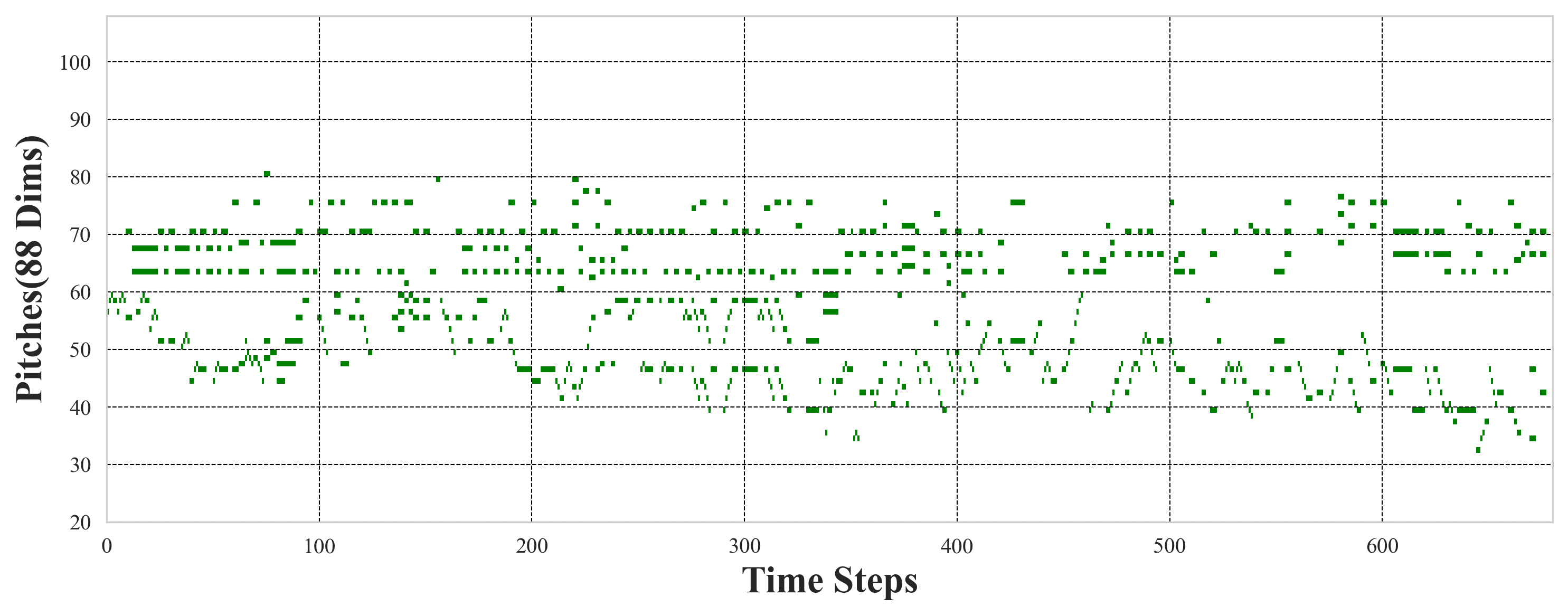
Figure 9: Hi-ACG-generated 2-minute conditional composition, validating the architecture's ability to respect context and continuation constraints.
Theoretical and Practical Implications
The primary theoretical implication is that structural anchoring using deterministically derived semantic summaries fundamentally mitigates error accumulation in long AR generation. Practically, ACG—and by extension Hi-ACG—establish a scalable, interpretable protocol for symbolic music generation that is compatible with existing AR models and transferable to other long-sequence domains such as narrative text, speech, and hierarchical video generation.
The use of a blockwise piano token representation enables both data compression and improved alignment between generative granularity and musical time scales. The hierarchical architecture, together with anchor-based conditioning, sets a blueprint for next-generation symbolic sequence generators that require both local expressivity and global form.
Limitations and Future Directions
Current controllability is limited in terms of explicit user-guided structure or expressive nuance. Extension to richer instrumentations, multi-track formats, and expressive (non-piano) vocabularies will require further architectural and dataset advances. The deterministic block representation may also miss micro-timing or expressive subtleties inherent to more flexible event-based encodings.
Exploration of anchor-based cyclic mechanisms for other structured generative tasks—beyond symbolic music—remains a rich avenue for developing error-resilient, hierarchically coherent sequence models.
Conclusion
The Anchored Cyclic Generation paradigm provides a robust solution to the core problem of error accumulation in AR symbolic music generation. Its hierarchical extension, Hi-ACG, sets new standards for long-sequence musical structure and quality, outperforming both Transformer and diffusion-based approaches in both objective and subjective settings. The innovations in representation, architecture, and error control have strong implications for a wide spectrum of sequence generation applications and open new directions for controllable, scalable symbolic generation systems (2604.05343).