- The paper presents NeuroQuant, a dual-stream 3D VQ-VAE that disentangles anatomical and modality-specific features for enhanced MRI reconstruction.
- It employs factorized multi-axis attention and joint 2D/3D training, achieving superior PSNR, SSIM, and Dice scores on T1/T2 MRI datasets.
- The approach supports robust counterfactual synthesis and downstream analysis, offering scalable, modality-invariant representations in neuroimaging.
Modality-Aware Anatomical Vector-Quantized Autoencoding for Multimodal Brain MRI
Motivation and Context
Modeling multimodal structural MRI is crucial for comprehensive brain analysis, particularly as T1- and T2-weighted scans yield complementary anatomical and pathological information. However, data heterogeneity, limited access to multimodal acquisitions for every subject, and intrinsic differences among imaging modalities present challenges for representation learning. Existing brain VAEs are predominantly modality-agnostic or rely on modality-specific encoders, which inherently duplicate model parameters, yield redundant representations, and fail to exploit the shared anatomical structure underlying different imaging contrasts.
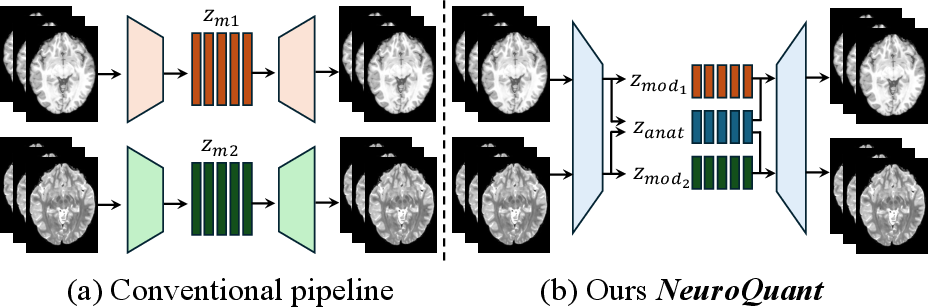
Figure 1: Conventional approaches handle different MRI modalities by duplicating separate encoders. In contrast, we employ a unified 3D encoder that disentangles shared anatomical representations zanat from modality-specific features zmod within the same latent space.
Unified anatomical encoding across MRI modalities is underexplored, while domain-agnostic VAEs in the medical space (e.g., MedVAE, MediTok) do not sufficiently enforce separation between anatomical content and modality-dependent features. These approaches underperform in terms of volumetric coherence and reconstruction fidelity, especially for 3D neuroimaging applications that demand anatomical precision. Consequently, improved methods are required to support high-fidelity generation, counterfactual inference, and robust downstream analysis in neuroimaging.
NeuroQuant: Dual-Stream 3D VQ-VAE Architecture
The paper introduces NeuroQuant, which implements a modality-aware dual-stream 3D VQ-VAE architecture. The encoder simultaneously disentangles modality-invariant anatomical structure and modality-specific appearance through parallel branched representation learning. Critically, global structural relations are captured via factorized multi-axis attention, ensuring long-range dependencies are modeled efficiently and effectively.
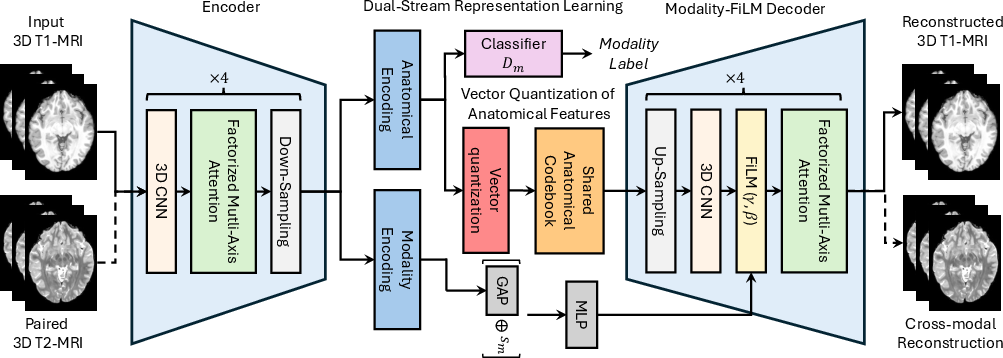
Figure 2: Architecture of NeuroQuant, which disentangles anatomical and modality-specific representations utilizing a unified encoder with factorized multi-axis attention, a shared vector-quantized anatomical codebook, and FiLM-based modality conditioning in the decoder.
The anatomical latent representation is discretized through a shared 3D vector-quantized codebook, while modality-specific features modulate the decoder’s pathway via FiLM transformations, parameterized by a modality embedding and MLP. This ensures adaptation to contrast variations while maintaining structural consistency, supporting accurate cross-modal synthesis and robust feature disentanglement.
The network is trained using joint 2D/3D batches, alternately sampling full volumetric scans and single slices along various orthogonal views. During 2D slice-focused training, axis-wise attention is selectively disabled for non-active planes and convolutional operations are adjusted for planar context, leading to greater flexibility, data efficiency, and improved recovery of high-frequency anatomical features.
Modality invariance for the anatomical code is enforced through cross-modal reconstructions (swapping modality codes on the same anatomical base) and adversarial training with gradient reversal. This dual-objective yields anatomical latents that are maximally informative for structure but minimally predictive of imaging contrast.
Experimental Results
NeuroQuant is benchmarked against multiple VAE and VQ-VAE models (VQGAN, SD-VAE, MediTok, MedVAE) on large-scale 3D T1/T2 brain MRI datasets (NCANDA, ABCD). Metrics capture voxel-level fidelity (PSNR, SSIM), structural and volume-level consistency (SynthSeg-assisted Dice), and linear decode performance for biological variables (sex classification).
NeuroQuant surpasses all baselines in PSNR, SSIM, and Dice scores across both T1 and T2 reconstructions, while using a more compressed (16×) latent space. On NCANDA, for T1 images, NeuroQuant achieves PSNR 28.89 and SSIM 95.27, outstripping MedVAE by +0.63 dB and +0.89, respectively. Performance is robust even on the heterogeneous ABCD set. Latent representations from NeuroQuant are semantically discriminative, achieving higher sex classification accuracy than competing models, illustrating the value of structural disentanglement for downstream analysis.
Ablations confirm that factorized multi-axis attention contributes most to structural fidelity, while the modality-FiLM decoder refines appearance adaptation. Joint 2D/3D training significantly improves both the voxel-level and anatomical quality of reconstructions. Auxiliary losses targeting cross-modal preservation and adversarial modality removal further enhance latent disentanglement, as evidenced by improved SynthSeg-derived regional volume estimates and reduced anatomical variance.
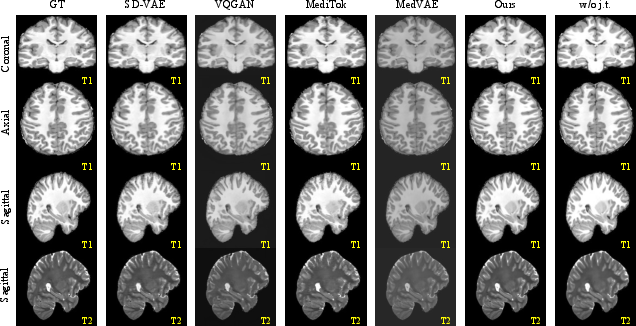
Figure 3: Qualitative comparison of T1- and T2-weighted MRI reconstructions; NeuroQuant (with joint 2D/3D training) recovers crisp cortical details and sharp boundaries, in contrast to baseline smoothing and slice-inconsistency artifacts.
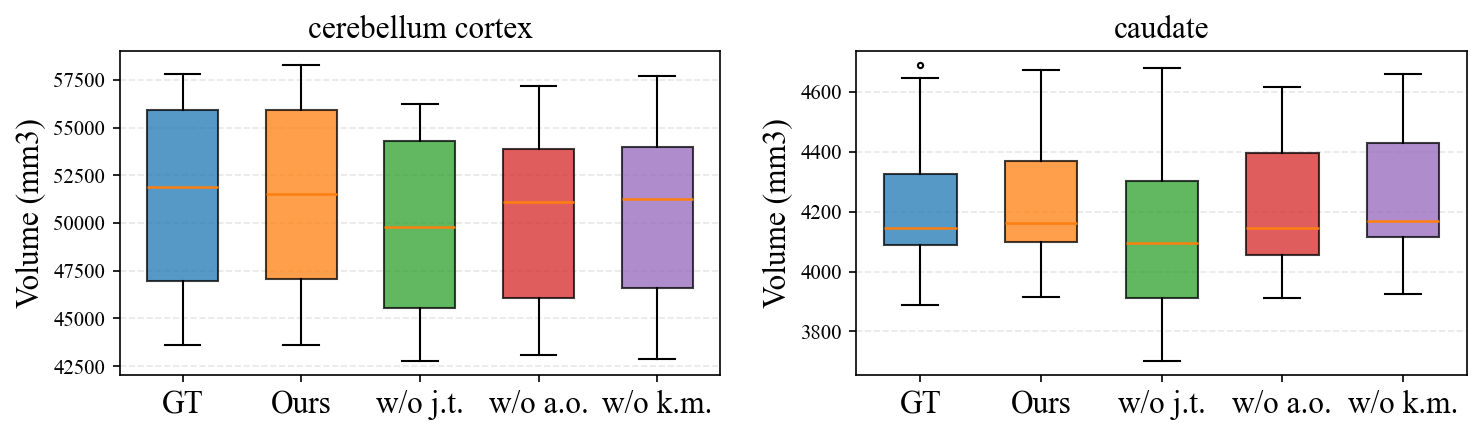
Figure 4: SynthSeg-based regional brain volume comparison (cerebellum cortex, caudate) between ground-truth, full model, and ablated variants; NeuroQuant’s predictions closely match the ground-truth distributions.
Practical and Theoretical Implications
Practically, NeuroQuant presents a compressive, semantically meaningful, and anatomically faithful latent space for 3D multimodal neuroimaging. This approach enables more scalable and generalizable foundation models in neuroimaging, supporting image generation, augmentation, and analytic tasks across imaging contrasts. The learned separation of anatomy and modality offers robust support for counterfactual image synthesis, interpretable generative modeling, and potentially, longitudinal or multi-center harmonization with minimal retraining.
Theoretically, the architecture demonstrates that dual-stream encoding—augmented with global attention and rigorous anatomical-modality disentanglement—advances the capability of VAEs in complex imaging domains. Joint 2D/3D training emerges as critical for bridging the demands of volumetric and planar context learning. Additionally, adversarial removal of nuisance (modality) variance from anatomical codes sets a strong precedent for scalable, modality-invariant medical representation learning.
Future Directions
The framework paves the way for several future research avenues:
- Expansion to additional modalities (e.g., FLAIR, diffusion MRI) and multi-institutional datasets.
- Integration with text or metadata conditioning for controlled counterfactual synthesis.
- Downstream applications in disease classification, progression modeling, and generative augmentation for rare-pathology cohorts.
- Extending the disentanglement approach for causal inference and explainable AI pipelines in medical analysis.
Conclusion
The NeuroQuant framework establishes a modality-aware, anatomically grounded VQ-VAE paradigm that outperforms established models on all core neuroimaging tasks by leveraging factorized attention, explicit feature disentanglement, and joint 2D/3D training. The resultant latent codes offer maximal anatomical fidelity and minimal modality leakage, setting a new standard for scalable, interpretable foundation models in multimodal brain MRI analysis (2604.05171).