- The paper introduces a source-wise adaptive diffusion framework with GP priors that aligns latent dimensions for precise blind source separation.
- It demonstrates near-perfect source recovery in linear mixtures and effective disentanglement in challenging nonlinear settings.
- The method jointly optimizes reconstruction, GP penalty, denoising loss, and KL regularization to balance structure and accuracy.
StrADiff: Structured Source-Wise Adaptive Diffusion for Blind Source Separation
Introduction and Motivation
The StrADiff framework introduces a structured, source-wise adaptive approach to diffusion-based generative modeling targeted at blind source separation (BSS) tasks, extending to both linear and nonlinear mixing regimes. The model is motivated by the need for interpretability and structure in latent-variable models, particularly when learning representations intended to reflect underlying independent generative factors. While prior works on diffusion models in BSS applied shared or externally imposed priors, StrADiff departs by explicitly assigning each latent source dimension its own reverse diffusion branch and source-specific structural prior, operationalized here via adaptive Gaussian Processes (GPs). This instantiation enables strong specialization and alignment of latent dimensions with individual sources, aiming at improved unsupervised recovery, disentanglement, and interpretability.
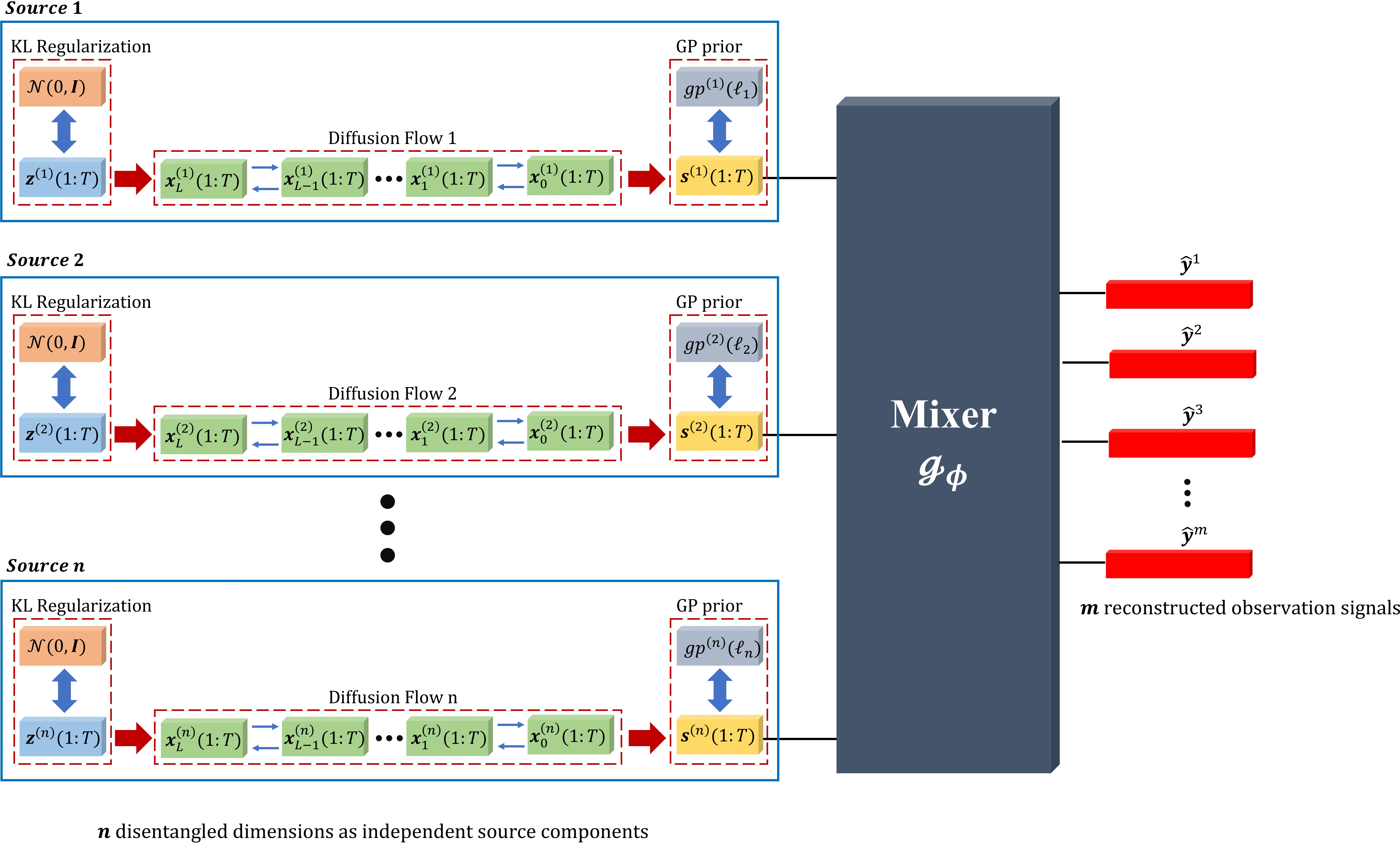
Figure 1: Overall architecture of the proposed StrADiff Framework, highlighting the source-specific initialization, reverse diffusion branches, GP priors, and explicit mixing map.
Methodological Framework
Source-Wise Latent Diffusion
The core innovation of StrADiff is the decomposition of the latent sources such that each dimension—indexed as k=1,…,n—is processed independently through its own generative path:
- Initialization: Each branch begins with a trainable Gaussian latent z(k).
- Reverse Diffusion: A dedicated network ϵθk guides each z(k) through L reverse diffusion steps, generating a candidate trajectory s(k).
- Explicit Structural Priors: Each s(k) is constrained by a GP prior with learnable length scale ℓk, imposing source-specific temporal smoothness and enhancing identifiability.
The separated s(k) are jointly mapped to the observed mixture through a flexible decoder gϕ, which may be linear or nonlinear, admitting both mixing paradigms in a unified objective.
End-to-End Training
The loss optimized over all parameters (mixing model, diffusion, GP hyperparameters, and latent initializers) composes four synergistically coupled components:
- Reconstruction Loss: Observation-space fidelity via Frobenius-norm error.
- GP Prior Penalty: Normalized negative log-density to enforce temporal regularization.
- Source-wise Denoising Objective: Standard diffusion model training through per-branch z(k)0-prediction losses.
- KL Regularization: Penalty to prevent degenerate collapse of the Gaussian latent variables.
All constituents are balanced with explicit weighting coefficients, allowing precise control over structure-specialization, reconstruction, and regularization trade-offs.
Empirical Investigation
Linear Mixing Experiments
Application to synthetic sources with distinct temporal dynamics under linear mixing demonstrates robust source extraction:
- Source Alignment and Specialization: Post-training, each branch converges to a high-fidelity recovery of a distinct underlying source, as demonstrated by permutation-matched correlation near unity and exceptionally narrow confidence intervals.
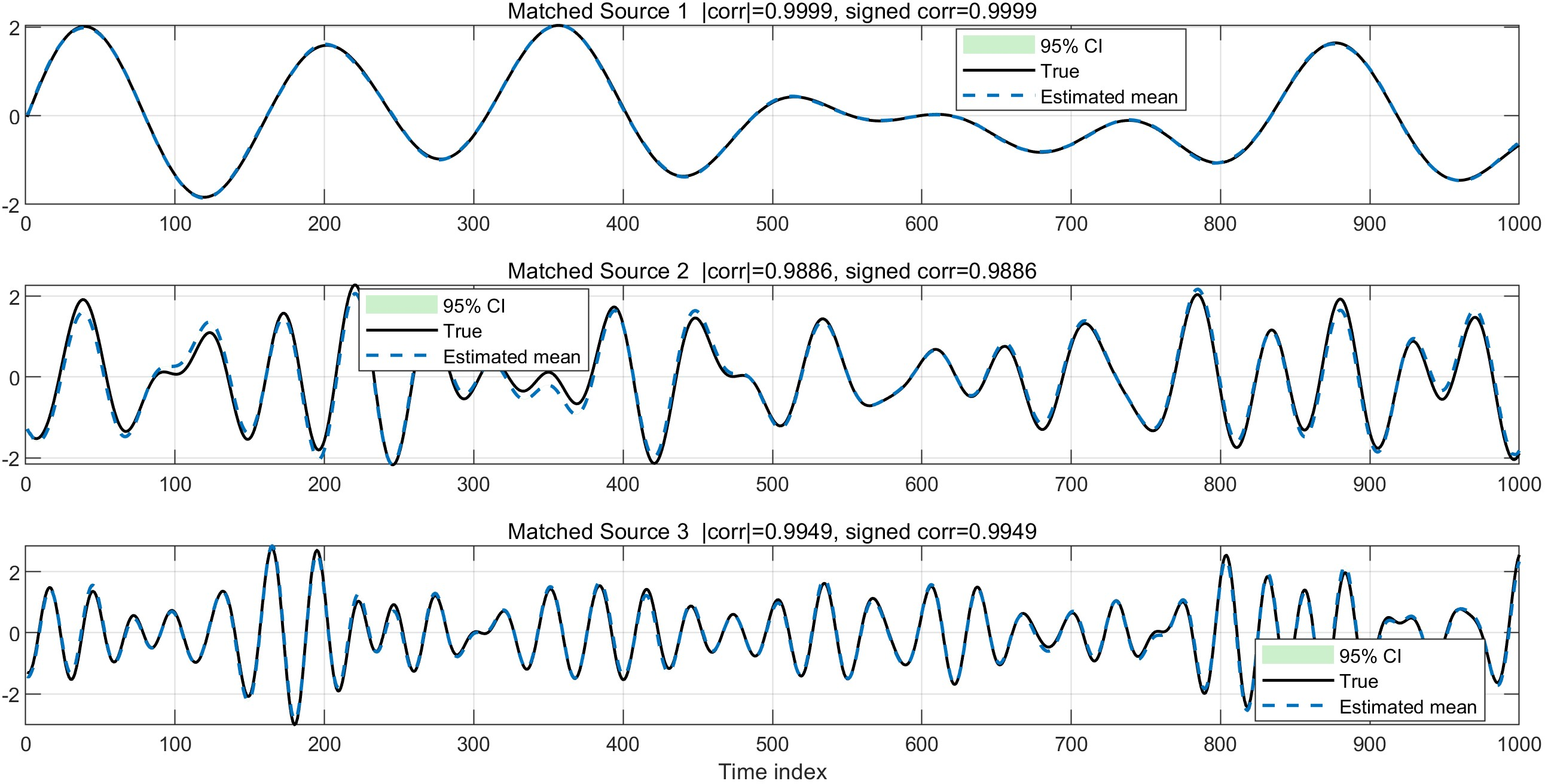
Figure 2: Linear mixing experiment: final matched source recovery results with nearly perfect alignment and confidence.
- Optimization Dynamics: Loss curves reveal rapid decrease in reconstruction error and stabilization of GP and denoising penalties. Source-wise correlations achieve high values early, indicating prompt and robust disentanglement.
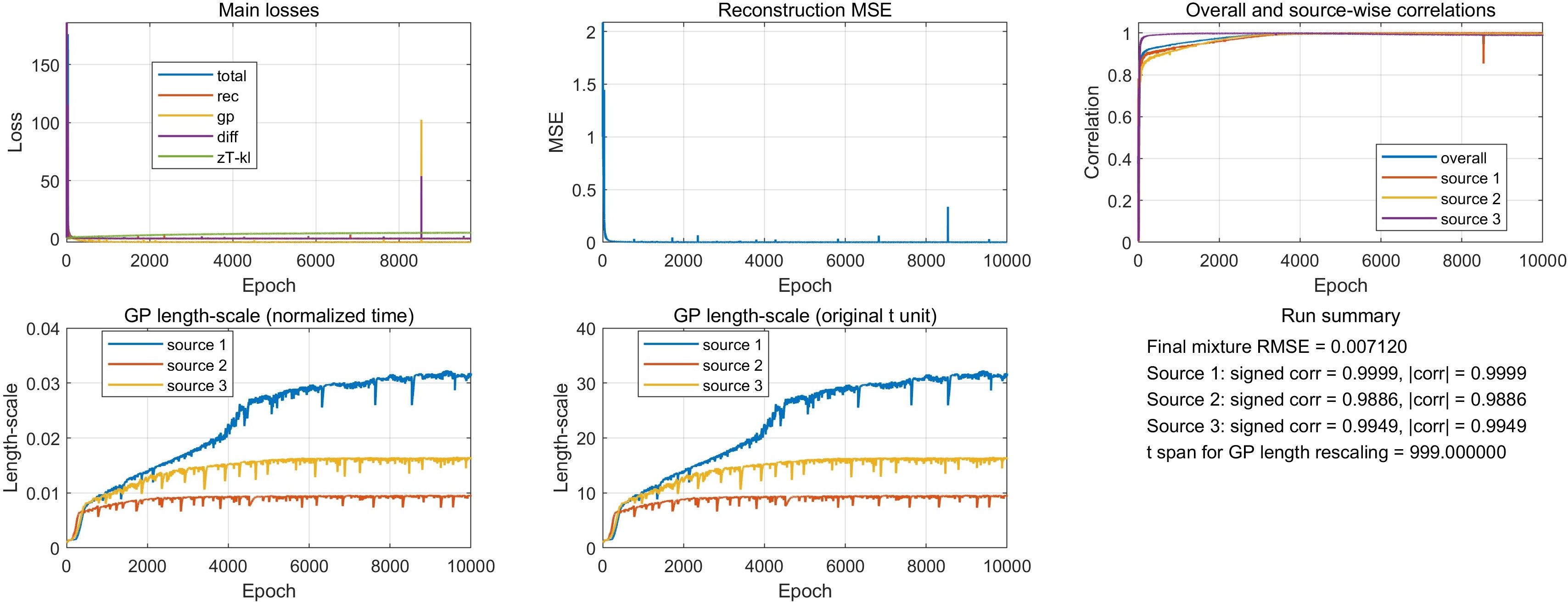
Figure 3: Convergence of main loss terms, reconstruction MSE, source-wise correlations, and learned GP length-scales in the linear experiment.
- Structural Adaptation: The GPs for different branches converge to distinct length-scales reflective of the specific underlying temporal processes of each source.
Diffusion Path Analysis
Visualization of intermediate reverse diffusion states across training epochs elucidates how StrADiff internalizes structure:
- At initialization, reverse diffusion paths are indistinguishable from noise.
- Mid-training, paths adopt shapes increasingly similar to their corresponding targets, and posterior uncertainty rapidly decreases.
- At convergence, each diffusion branch generates stable, source-specific structured trajectories.
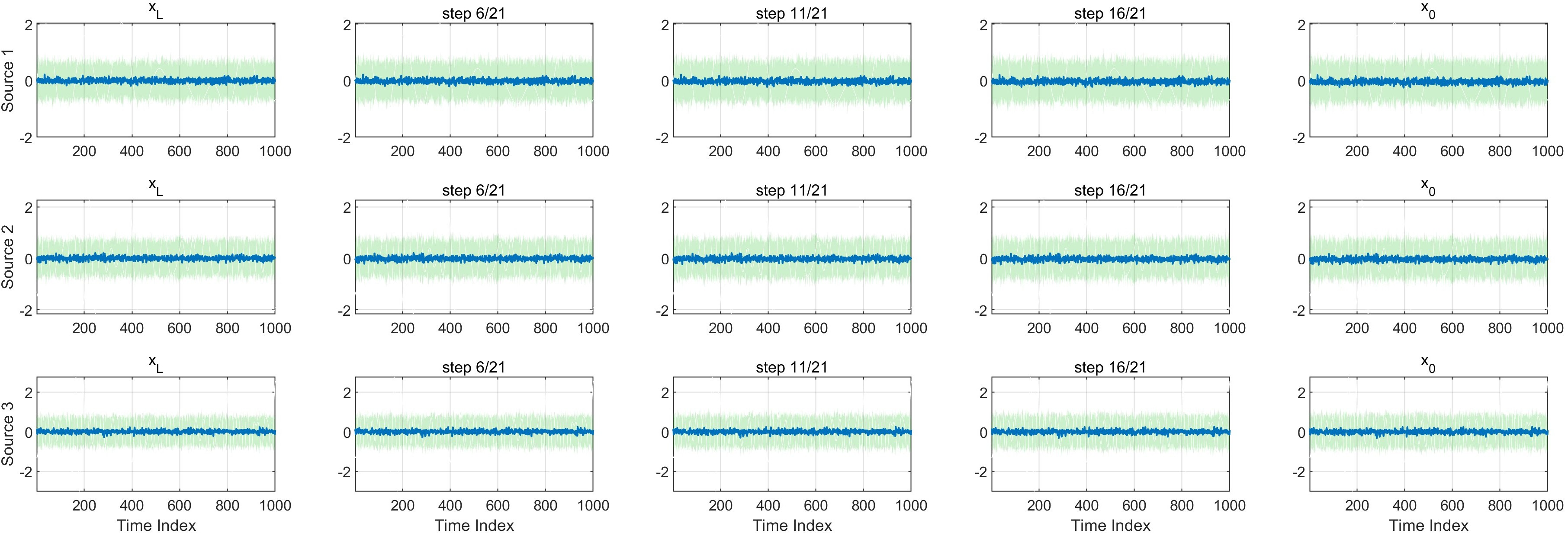
Figure 4: Reverse diffusion paths at the beginning of training remain unstructured.
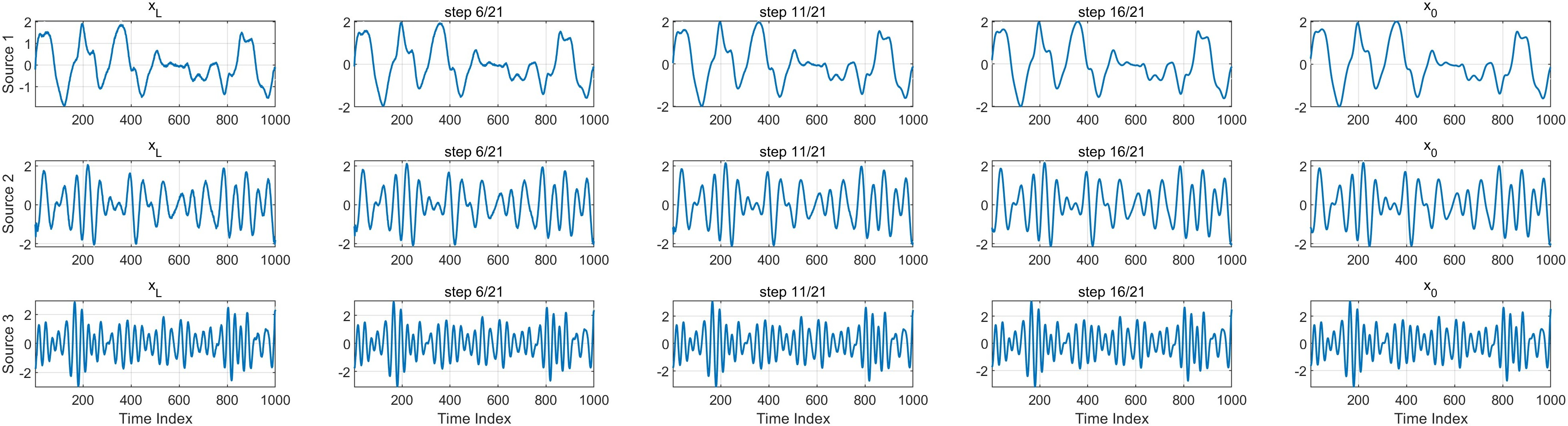
Figure 5: Reverse diffusion paths at an intermediate stage of training (epoch 3000) acquire significant structure and concentration.
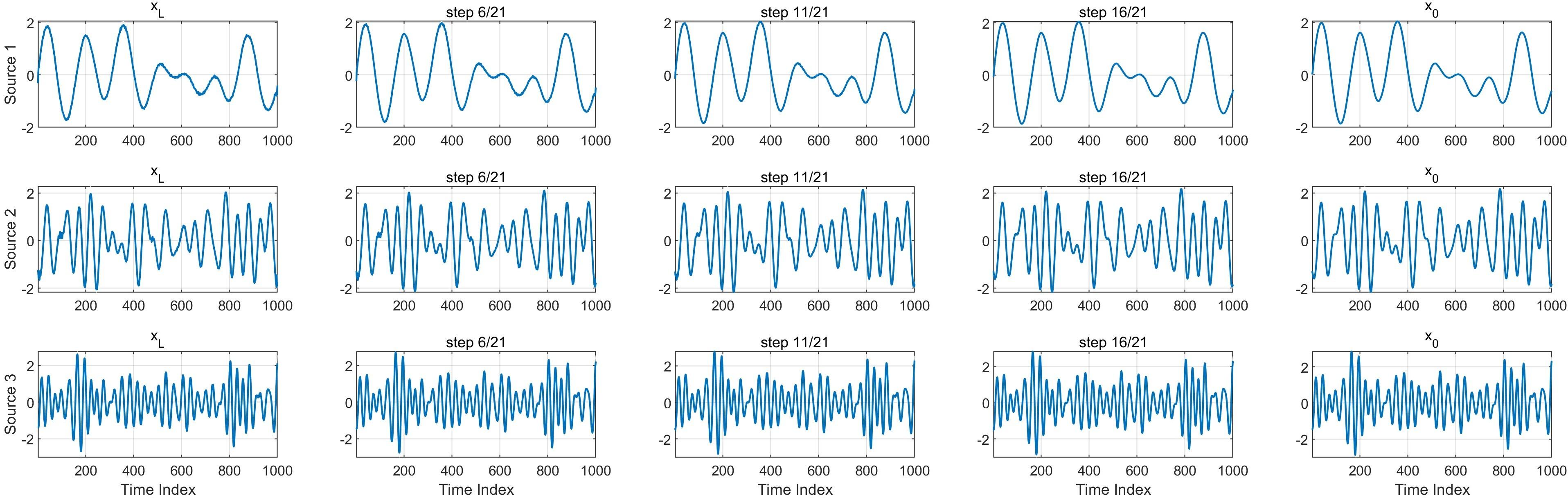
Figure 6: Reverse diffusion paths at the final epoch show highly stable, source-specific reconstructions.
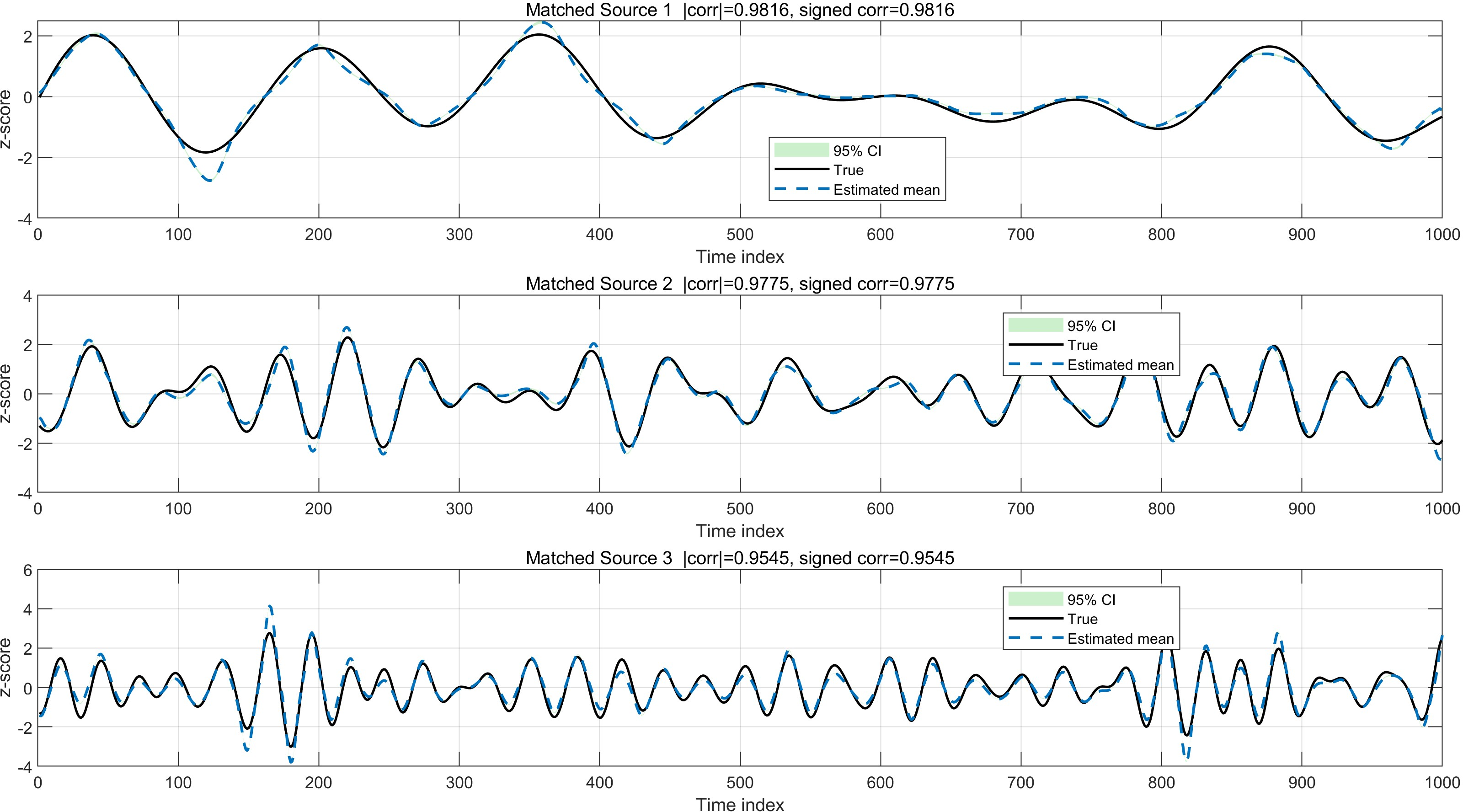
Nonlinear Mixing Experiments
For nonlinear mixing, source recovery remains effective but demonstrates performance degradation relative to the linear case:
Discussion and Implications
StrADiff's experimental results support several key insights:
- Strong Linear BSS Performance: Near-perfect separation in linear settings with precise alignment between sources and latent branches, minimal uncertainty, and stable loss convergence.
- Adaptive Structural Specialization: Different diffusion branches exploit their own GP prior hyperparameters, exhibiting source-dependent temporal adaptation.
- Active Role of Reverse Diffusion: The path analyses confirm that the reverse diffusion is not a passive generator but a learned transformation specializing each branch for genuine unsupervised source recovery.
- Nonlinear BSS: While nonlinear demixing remains more challenging, StrADiff still produces useful disentanglement—an empirical confirmation of the advantage of source-wise, structured modeling in unsupervised nonlinear ICA scenarios.
Theoretically, StrADiff bridges recent results in identifiability theory for nonlinear ICA with practical generative modeling, providing a shared framework apt for interpretable and structured unsupervised learning. It is not inherently bound to GP priors and can generalize to other structured regularizations as dictated by scientific or application-specific considerations.
Conclusion
StrADiff operationalizes a structured, source-wise adaptive diffusion paradigm for BSS, coupling explicit reverse diffusion branches, source-specific priors, and joint optimization of separation and observation consistency. The framework directly encourages specialization and interpretability, facilitates accurate source recovery (especially in linear mixing scenarios), and remains extensible to more complex separation, disentanglement tasks, or interpretable latent variable modeling beyond BSS.
Future developments may include applications to higher source dimensionality, more challenging nonlinearity, alternative structured priors (e.g., sparsity or dynamics models), and theoretical connections to nonlinear identifiability under broader structural conditions. The modular architecture recommends StrADiff as a candidate general platform for source-wise unsupervised learning and interpretable deep generative modeling.