- The paper introduces BUGS, which integrates univariate guidance into the horseshoe prior to adaptively modulate shrinkage in ultra-high-dimensional regression.
- It presents BUGS-Active, a computational strategy that dynamically selects active variable sets, reducing complexity for p in the millions.
- Empirical results demonstrate significant FDR reductions and enhanced signal detection in genomic data, supported by strong theoretical guarantees.
Bayesian Univariate-Guided Global-Local Shrinkage for Ultra-High-Dimensional Regression
Introduction and Context
This work presents a principled extension of Bayesian global-local shrinkage—specifically the horseshoe family of priors—via the direct incorporation of univariate (marginal) guidance into the prior hierarchy, yielding the Bayesian Univariate-Guided Sparse Regression (BUGS) and its computational variant, BUGS-Active. The methodology is situated toward sparse inference and model selection in ultra-high-dimensional linear models where p≫n, and is particularly suited for genomic or epigenomic settings, such as DNA methylation studies with hundreds of thousands to millions of candidate predictors.
Traditional global-local priors (e.g., regularized horseshoe) treat predictors symmetrically a priori, deferring all adaptation to the likelihood. The key innovation is to embed marginal relevance information, assessed for each predictor, into the shrinkage mechanism in a continuous, covariate-dependent, but fully Bayesian fashion.
Marginal Guidance in Shrinkage Priors
Within the BUGS framework, for each coefficient βj, the marginal relevance is quantified by a standardized statistic (e.g., scaled absolute marginal correlation), transformed and bounded to produce a guidance score zj∗. This statistic is computed a priori from observed data and then treated as fixed (not subject to Bayesian inference), analogous to conditioning on an empirical Bayes prior.
Marginal guidance influences the shrinkage hierarchy by modulating the local variance:
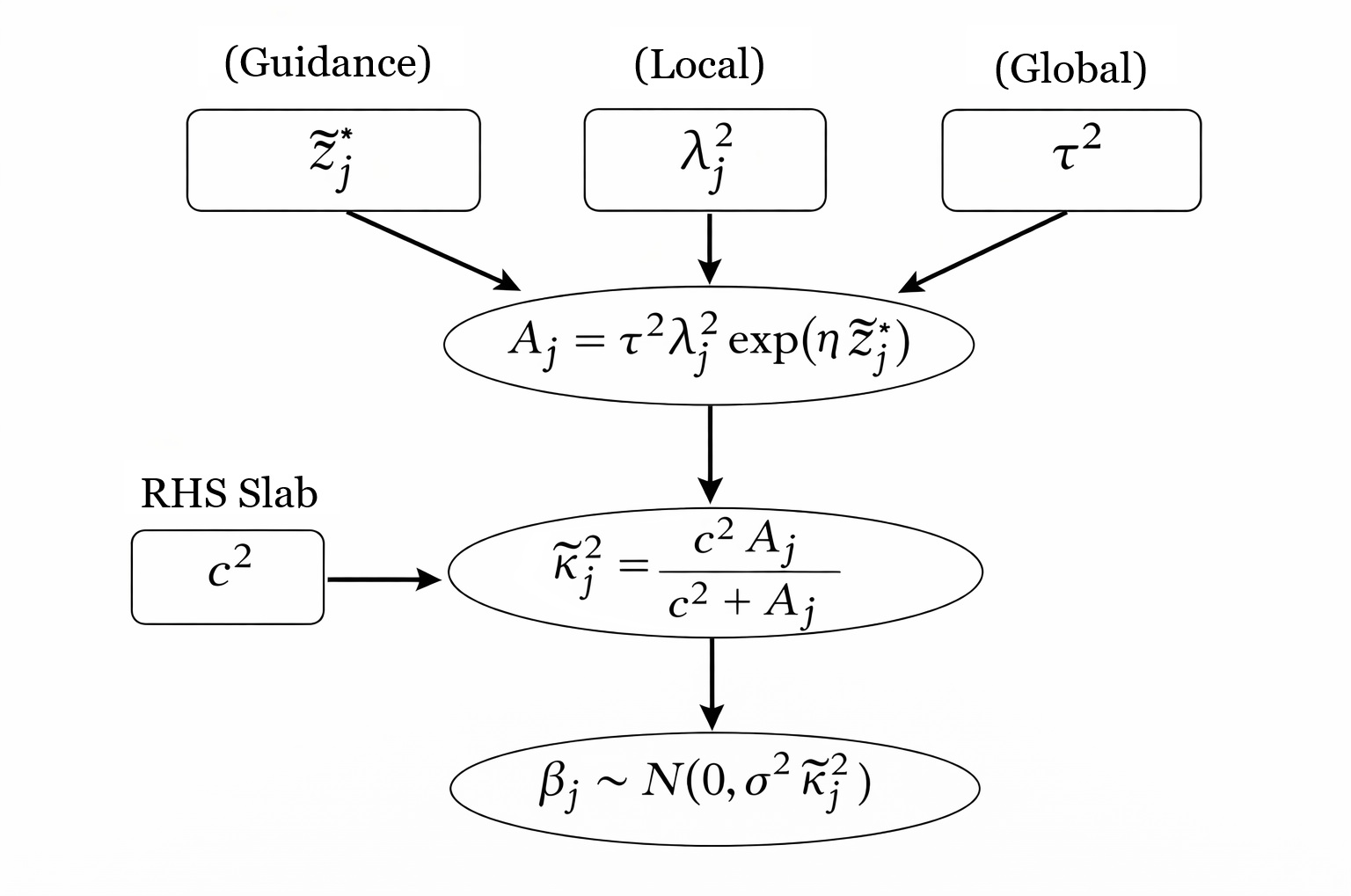
Figure 1: Schematic of the guided regularized horseshoe prior, in which the effective scale for βj is determined by both the classical global-local scales and a multiplicative guidance multiplier dependent on marginal association.
Specifically, the effective prior variance for βj is
κ~j2=c2+τ2λj2exp(ηzj∗)c2τ2λj2exp(ηzj∗)
where λj is the local scale, τ the global scale, c the slab scale, and η the strength of the guidance effect (also assigned a prior and learned from the data). The term βj0 amplifies (attenuates) the effective variance for variables with large (small) marginal effects.
Figure 2: The effect of marginal guidance on the prior; positive βj1 increases the local prior scale, enabling earlier escape from shrinkage, whereas negative βj2 intensifies shrinkage.
This formulation alters not just the amount of shrinkage per variable but structurally shifts the transition point from strong shrinkage to slab behavior in the prior—a key distinction from baseline weighted or covariate-dependent shrinkage priors, which merely modulate scale without affecting the nonlinearity of the thresholding.
Posterior Computation and Active-Set Approximation
For βj3 up to approximately βj4, the full model may be sampled via a hybrid Gibbs/slice sampler with Woodbury-based block updates for the coefficient vector. To enable inference for βj5, BUGS-Active restricts expensive local scale updates to a dynamic active set of variables prioritized by their guidance scores and/or large posterior coefficients. This reduces per-iteration complexity from βj6 to βj7 for local updates, while the coefficient vector is always sampled globally.
BUGS-Active is more than a computational heuristic: the paper establishes that when the active set screening satisfies suitable separation properties (codified via marginal score and posterior thresholding), theoretical properties such as posterior concentration, sure screening, and false discovery control are preserved asymptotically.

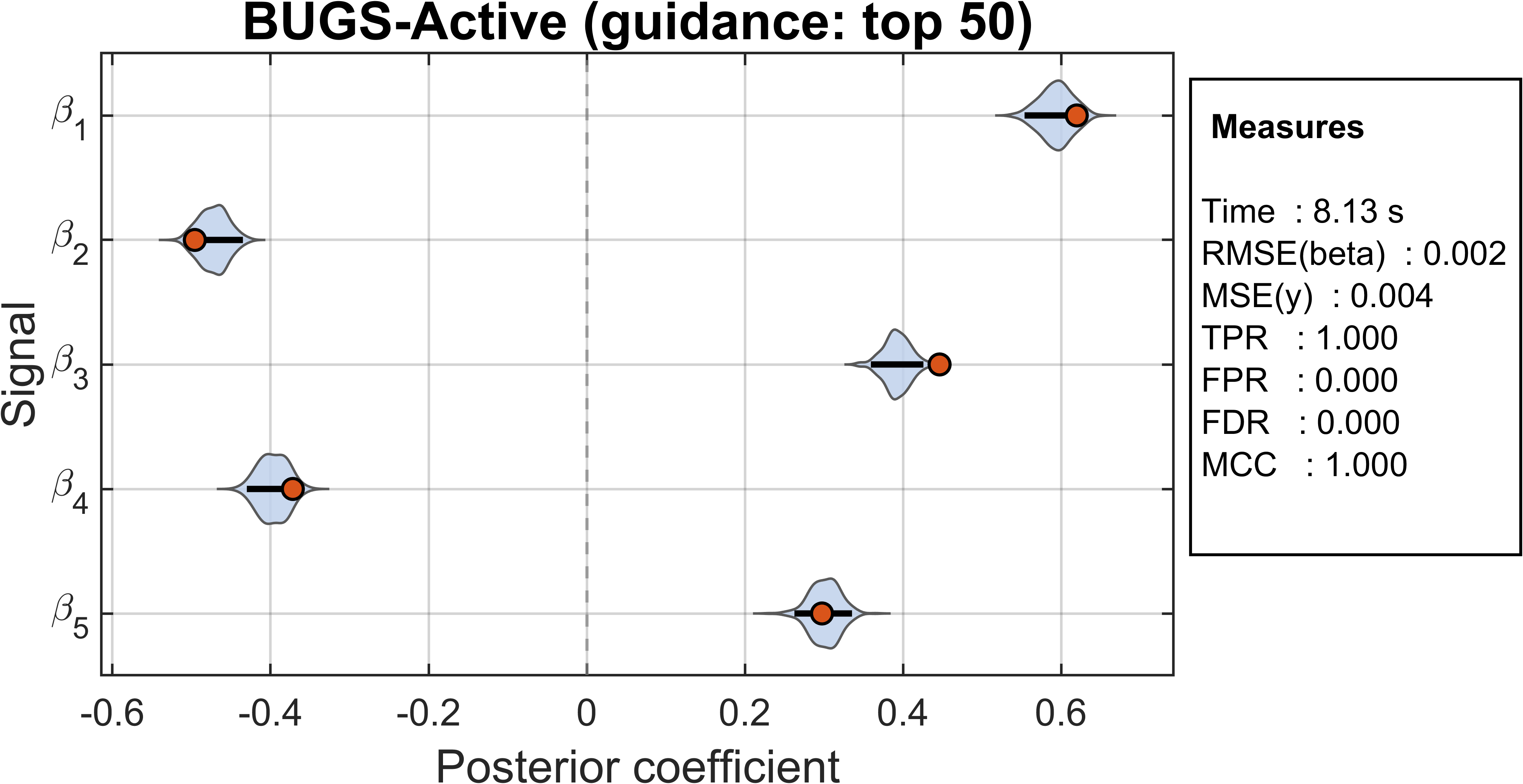
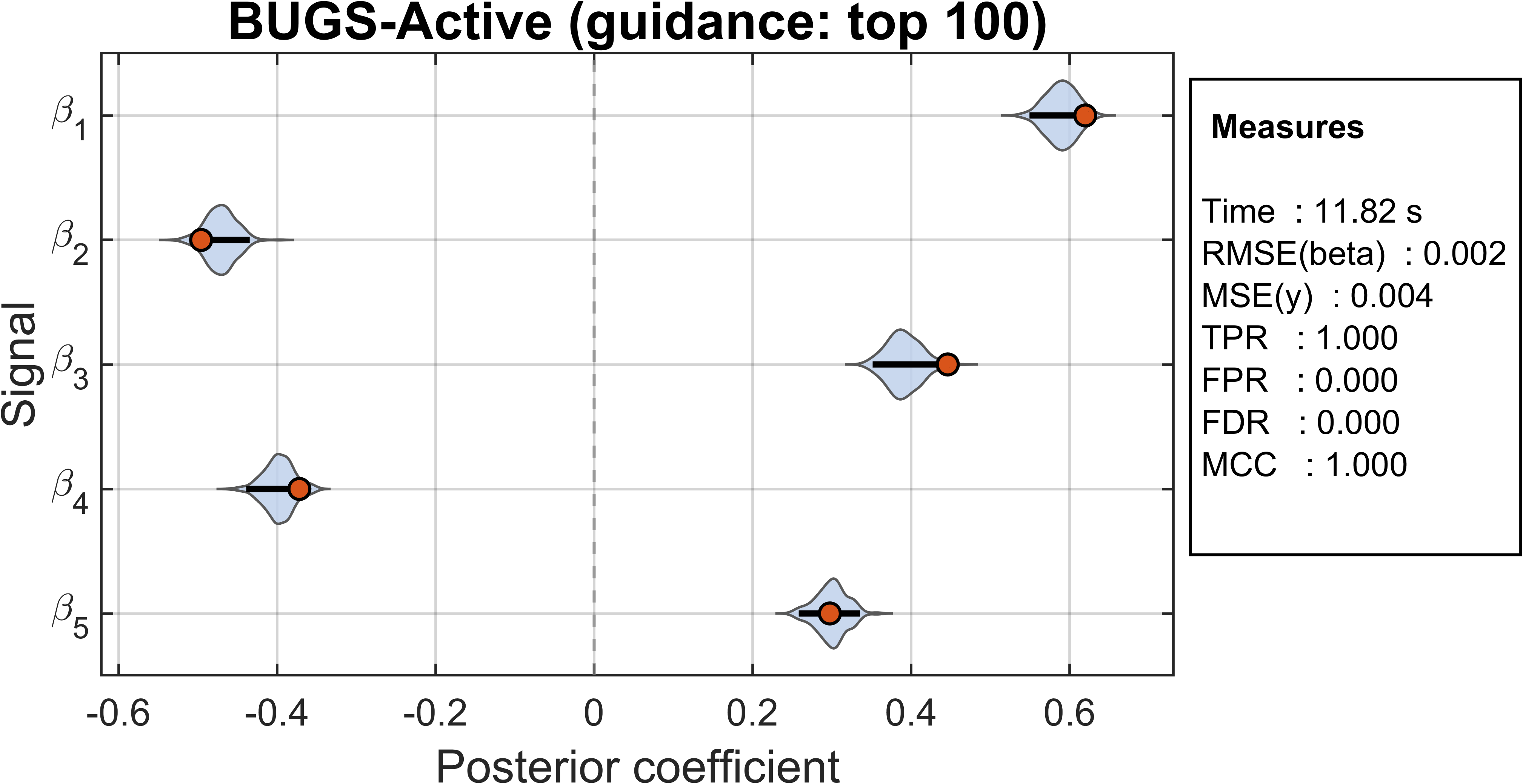
Figure 3: Impact of the guidance budget (size of active set for local updates) on posterior estimation for strong signals, illustrating the trade-off between aggressive computational savings and accurate posterior recovery.
Theoretical Properties
The paper synthesizes prior concentration and posterior contraction theory for the guided prior, explicitly accounting for both informative and uninformative marginal statistics. Main results include:
- The guided prior retains optimal (minimax) contraction rates for sparse high-dimensional linear models, matching unguided global-local priors when guidance is uninformative.
- Under informative guidance, the prior induces systematic shrinkage separation between signals and noise, enhancing FDR control.
- The active-set posterior with data-driven screening preserves support and contraction rates if screening thresholds are adequately separated from the noise distribution.
These properties are established under standard high-dimensional conditions (sparsity, restricted eigenvalue, bounded signals, bounded design norm), with the guidance vector and active set treated as fixed, potentially constructed from auxiliary data when necessary for formal validity.
Empirical Evaluation
Extensive simulations demonstrate that the guided prior yields substantial reductions in false discovery rates (FDR), often an order of magnitude lower than standard global-local or LASSO-type methods, while maintaining near-perfect true positive rates and high Matthews correlation coefficients (MCC) even as βj8 increases to βj9.
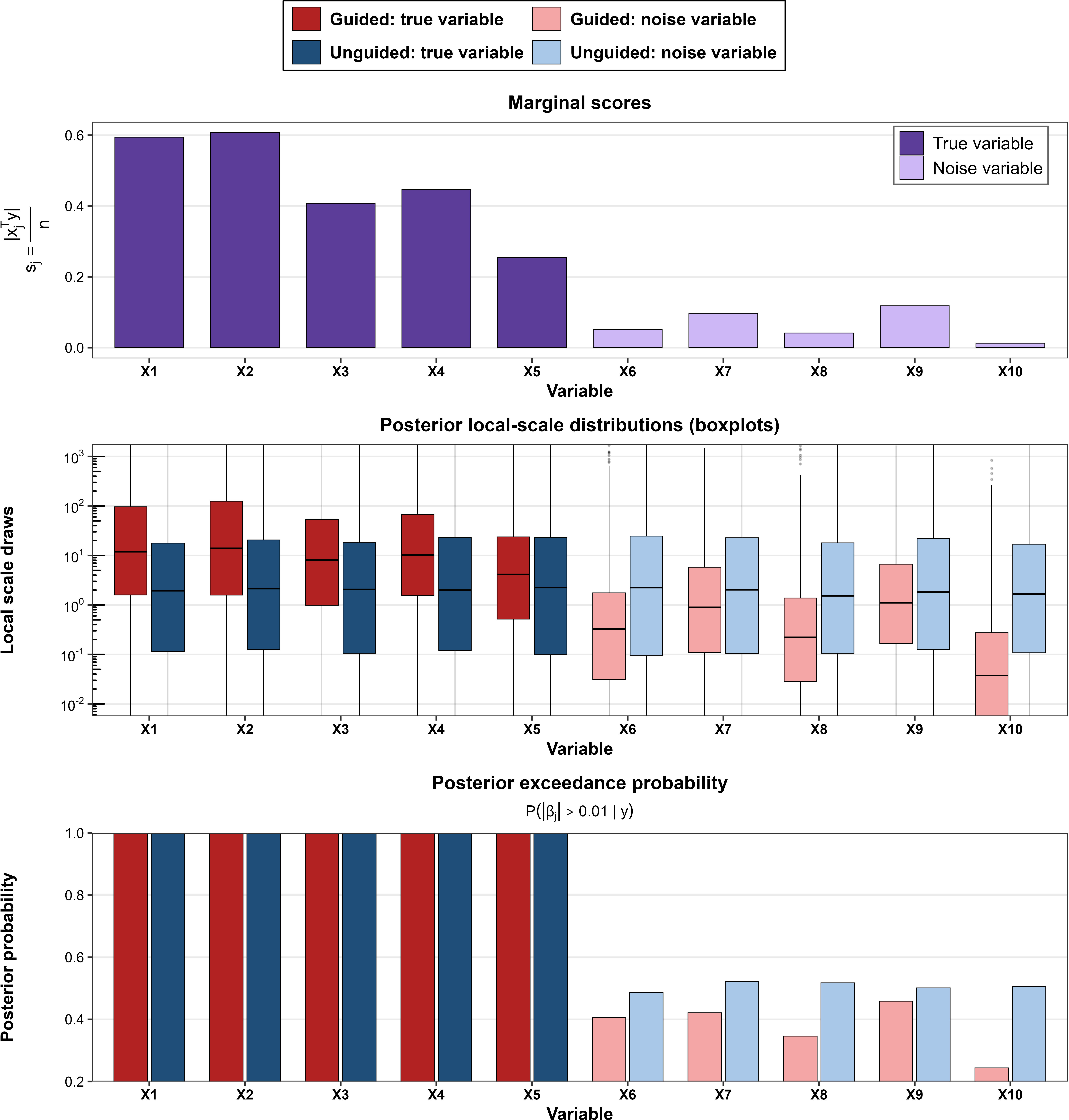
Figure 4: Marginal guidance effect in low dimension: guidance-modulated prior (red) yields more aggressive noise shrinkage and substantial signal separation compared to regularized horseshoe (blue).
The methodology is applied to an ultra-high-dimensional DNA methylation dataset (zj∗0, zj∗1), yielding sparse, interpretable effect estimates and improved out-of-sample predictive performance when compared to an unguided prior.
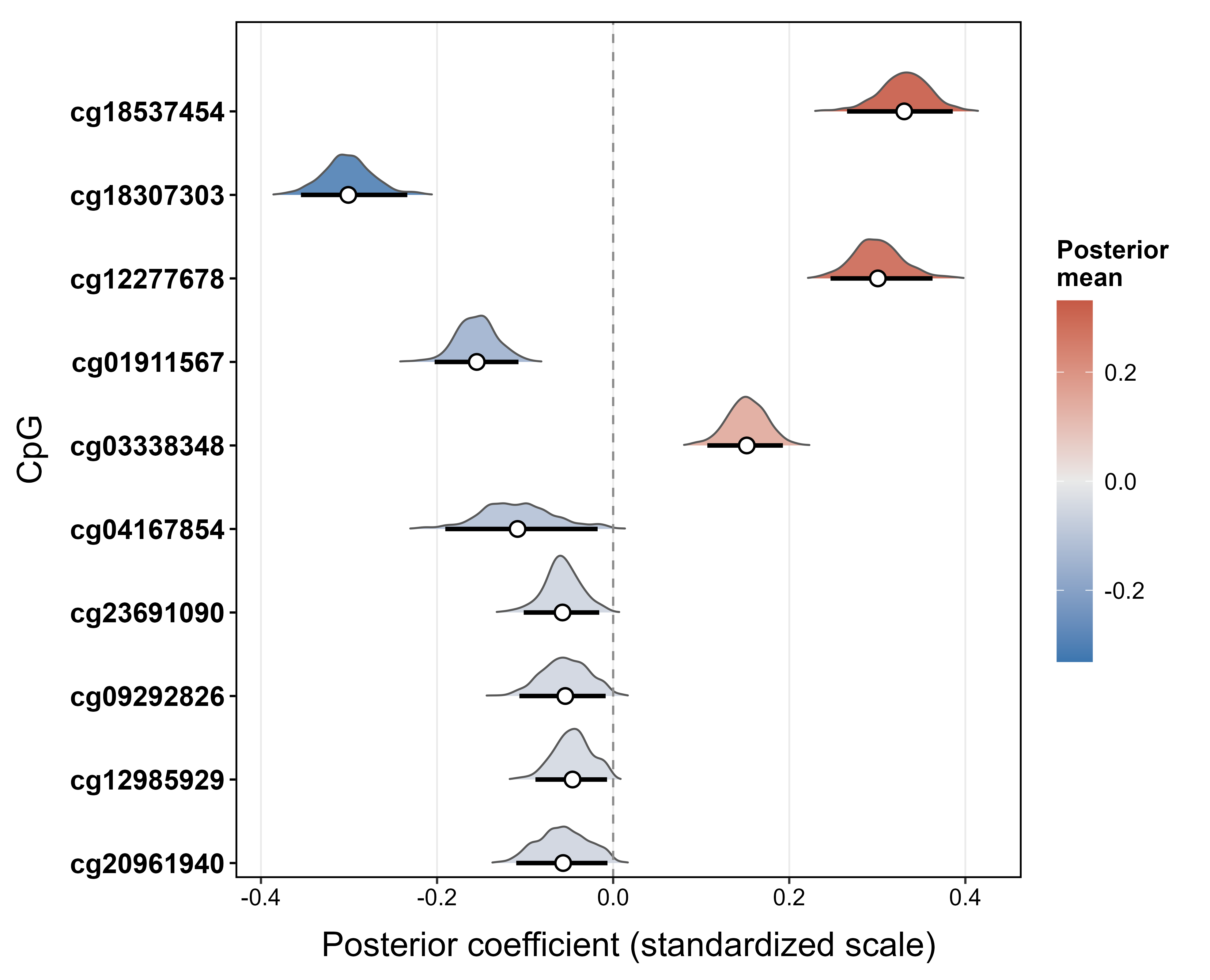
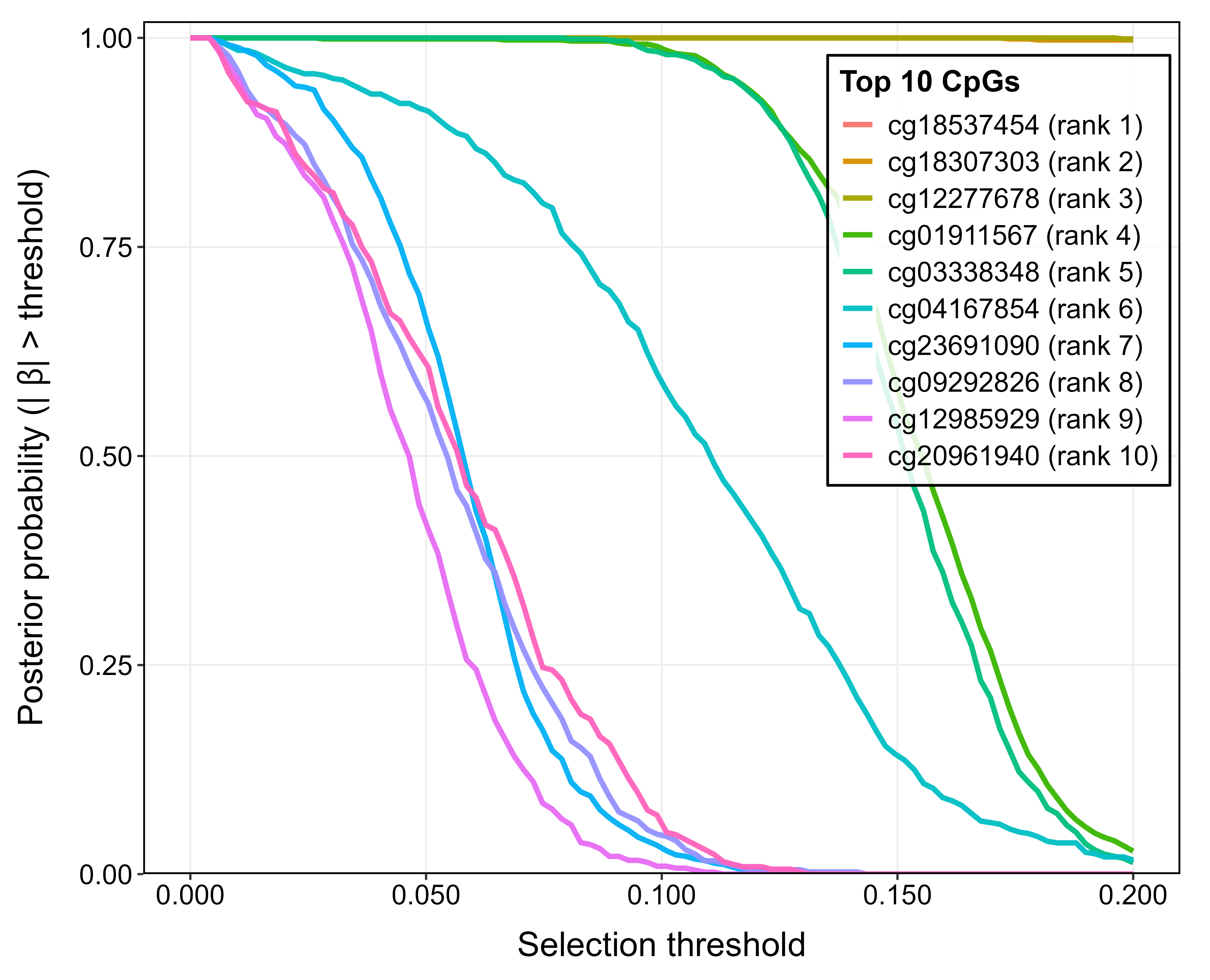
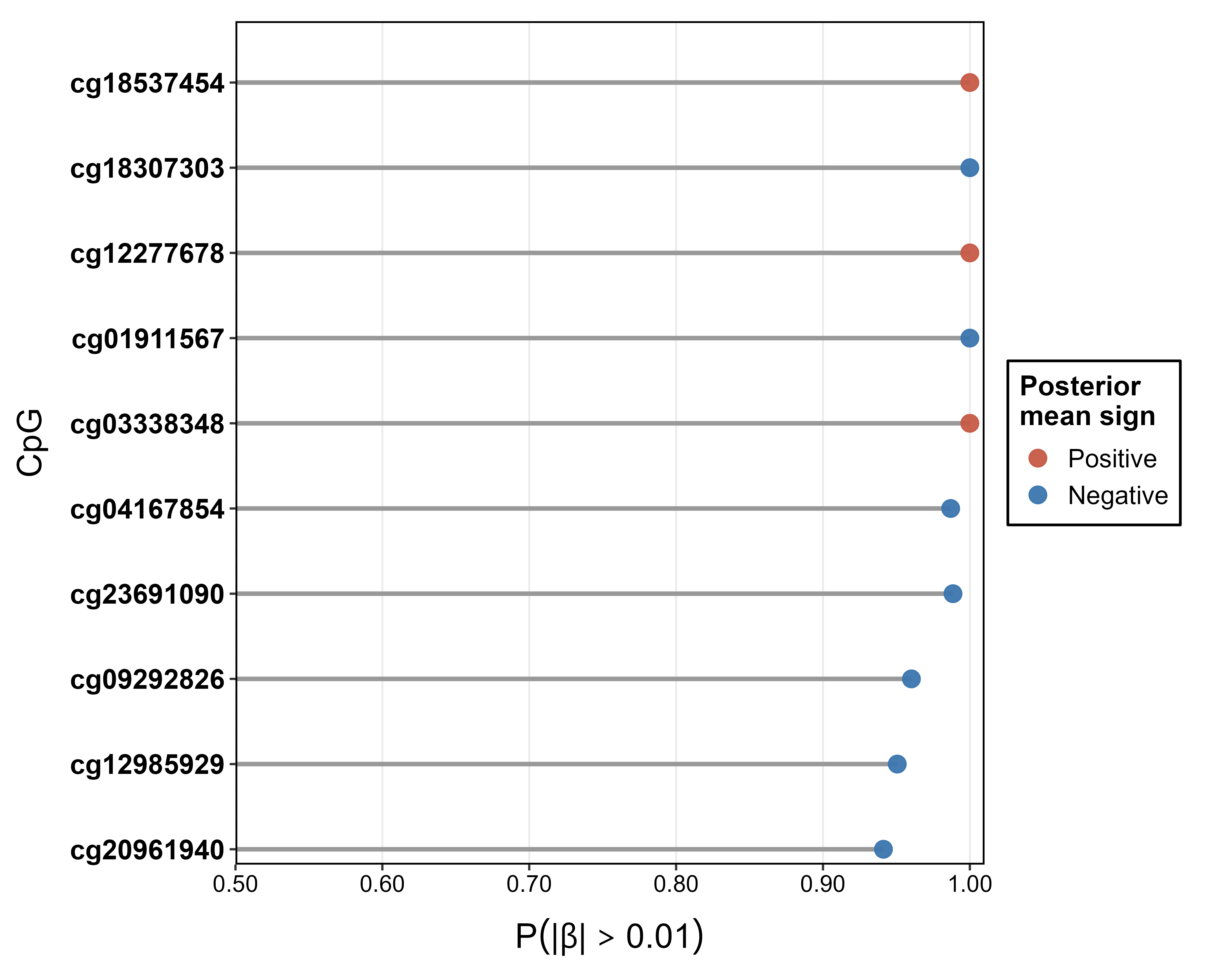
Figure 5: Posterior summaries for the top 10 identified CpGs influencing age in methylation data, posterior selection probabilities, effect directions, and predictive performance by developmental stage.
The results indicate that marginal guidance provides a continuous, data-adaptive regularization path that sharpens separation between true signals and noise, directly translating into improved selection and estimation properties in both synthetic and real datasets.
Discussion and Implications
BUGS and BUGS-Active contribute a scalable, theoretically justified Bayesian methodology for sparse variable selection and estimation in ultra-high-dimensional settings. Integration of marginal relevance as a multiplicative factor in the nonlinear shrinkage mapping enables more responsive adaptation and improved FDR control, especially relevant where protector-wise informativeness varies.
The framework provides a formal bridge between classical sure independence screening and modern Bayesian shrinkage, and its active-set approach delivers practical computational tractability for zj∗2 in the millions.
Key implications include:
- For statistical genomics and similar fields, the approach enables principled, uncertainty-quantified, interpretable inference without aggressive pre-screening or ad hoc post-selection adjustments.
- Theoretical robustness to uninformative guidance means the method is safe to deploy in scenarios where prior predictor information is weak or unreliable.
- As AI applications increasingly intersect with high-throughput data, such as feature selection in automated science, guided shrinkage mechanisms of this kind increase both the statistical performance and transparency of inference under extreme dimensionality.
- Further extensions to generalized linear and survival models, as well as adaptively tuned guidance budgets, will enable broader deployment in practice.
Conclusion
BUGS and BUGS-Active demonstrate that marginally guided shrinkage—realized through a data-adaptive modulation of the prior in the regularized horseshoe family—offers substantial advantage for ultra-high-dimensional sparse regression. The methodology brings tighter FDR control, improved interpretability, and practical scalability, with strong theoretical guarantees and demonstrable empirical superiority. This paradigm, integrating univariate guidance with nonlinear shrinkage, represents a natural and powerful direction for hierarchical Bayes in the era of massive, sparse data (2604.04964).