- The paper proposes a single-stage synthesis framework with synthetic triplet supervision to jointly handle virtual try-on and human animation.
- It employs a dual-module diffusion transformer that integrates human animation and garment transfer, ensuring robust identity preservation and pose adherence.
- Comparative results demonstrate that Vanast outperforms two-stage methods on metrics like PSNR, SSIM, and FID, validating its effective compositional video synthesis.
Vanast: Unified Human Image Animation and Virtual Try-On via Synthetic Triplet Supervision
The synthesis of temporally coherent garment-transferred human animation videos from a single reference image, one or more garment images, and a pose guidance video is nontrivial due to compounding distributional shifts across distinct stages of conventional pipelines. Traditional two-stage approaches—first performing image-based virtual try-on, then animating the result—suffer from identity drift, garment distortion, and spatio-temporal inconsistency. These arise from the lack of alignment between the train-time distributions of the respective modules and insufficient mechanisms for faithful multi-conditional control.
Vanast addresses these issues by defining a single-stage, end-to-end synthesis framework. The method leverages a novel triplet supervision paradigm, where each training datum comprises (1) a reference human image in arbitrary attire, (2) target garment image(s), and (3) a video of the target subject wearing the garment(s) and performing desired motions. This triplet construction is not supported by any existing public dataset and necessitates significant data generation and curation advances.
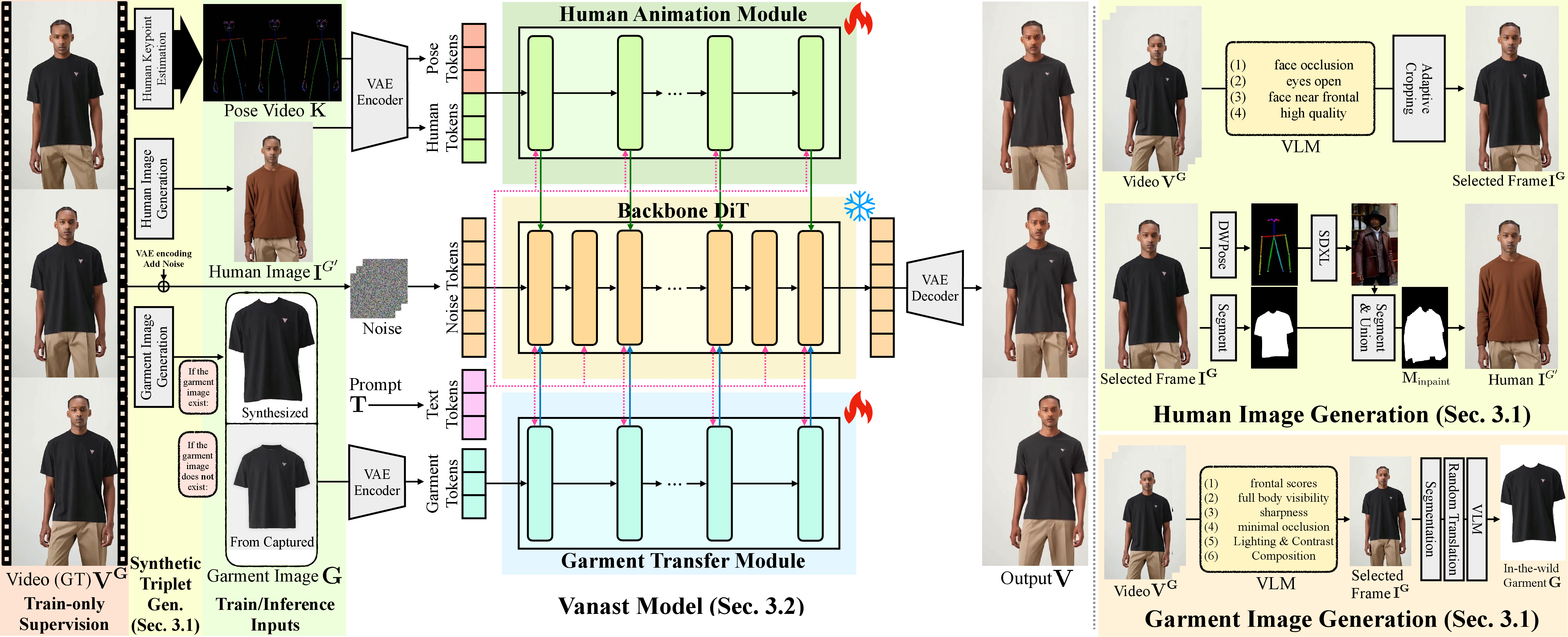
Figure 1: The Vanast pipeline jointly synthesizes virtual try-on human animation videos from a human image, garment images, and a pose video under its scalable data and network framework.
Synthetic Triplet Supervision and Scalable Data Generation
Vanast introduces a hybrid data generation pipeline capable of overcoming the dataset-specific limitations encountered in conventional settings. The synthetic triplet data is generated by:
- Identity-Preserving Inpainting: The reference human image is synthesized by applying garment-inpainting diffusion models (FLUX), guided by segmentation and VLM classification, to a subject frame, ensuring the garment differs from the target video while preserving pose and identity.
- In-the-Wild Data Augmentation: To address domain gaps and garment variety, synthetic triplets are mined from unconstrained Internet video (e.g., HumanVid, TikTokDress), with automatic garment segmentation and candidate frame selection governed by vision-LLMs (VLM) for pose, occlusion, and quality.
- Multi-Garment Studio Captures: To support simultaneous transfer of multiple garment types (upper and lower), new studio data is collected where subjects appear in various attire combinations.
This data construction results in significantly enhanced diversity in garments, poses, and scenes, and also provides critical supervision for single- and multi-garment transfer, as well as for in-the-wild deployment cases.

Figure 2: Synthetic triplet examples illustrating identity-preserving garment and pose diversity in the training corpus.
Standard approaches to joint conditional video synthesis struggle to propagate the three conditioning signals—human identity, garments, and motion—uniformly, leading to degraded disentanglement and convergence. Vanast resolves this by architecting a cascaded dual-module design atop a frozen pre-trained text-to-video DiT backbone:
- Human Animation Module (HAM): Specializes in encoding human appearance and pose variables.
- Garment Transfer Module (GTM): Focuses on encoding garment images (potentially multiple, if present).
- Cascaded Fusion: At designated transformer layers, representations from HAM and GTM are balanced and merged with the backbone, modulated by fixed mixing coefficients. The backbone itself remains frozen, preserving pre-trained generative priors and facilitating rapid, stable optimization.
- Tokenization Logic: VAE-based tokenization encodes the respective conditions for HAM/GTM. GTM also supports garment interpolation via linear mixing of garment tokens, enabling zero-shot garment style blending in output video.

Figure 3: Qualitative comparison (subject-to-image-based), demonstrating superior pose following, fidelity, and garment transfer in Vanast compared to two-stage methods.
Comparative Evaluation and Results
Quantitative and qualitative benchmarks against 16 combinations of state-of-the-art virtual try-on, subject-to-image, and human animation models (OOTDiffusion, CatVTON, OmniTry, Any2AnyTryon, VisualCloze, MOSAIC, UNO, StableAnimator, DisPose, VACE) demonstrate that Vanast achieves the best or competitive results across all major video and image quality metrics, including L1, PSNR, SSIM, LPIPS, FID, and VFID, on both Internet and ViViD datasets.
Vanast's single-stage synthesis demonstrates:
Ablations, Multi-Garment Transfer, and In-the-Wild Capabilities
Ablation experiments reveal that the dual module structure, combined with the synthetic triplet dataset, is essential for effective pose and garment disentanglement. Models trained with naïve concatenation of tokens, with LoRA-fine-tuned backbone only, or without explicit synthetic human image supervision, display inferior results—particularly in cases of pose-mismatch or novel garment types.

Figure 5: Single garment transfer samples substantiate Vanast's precision on garment localization and appearance.
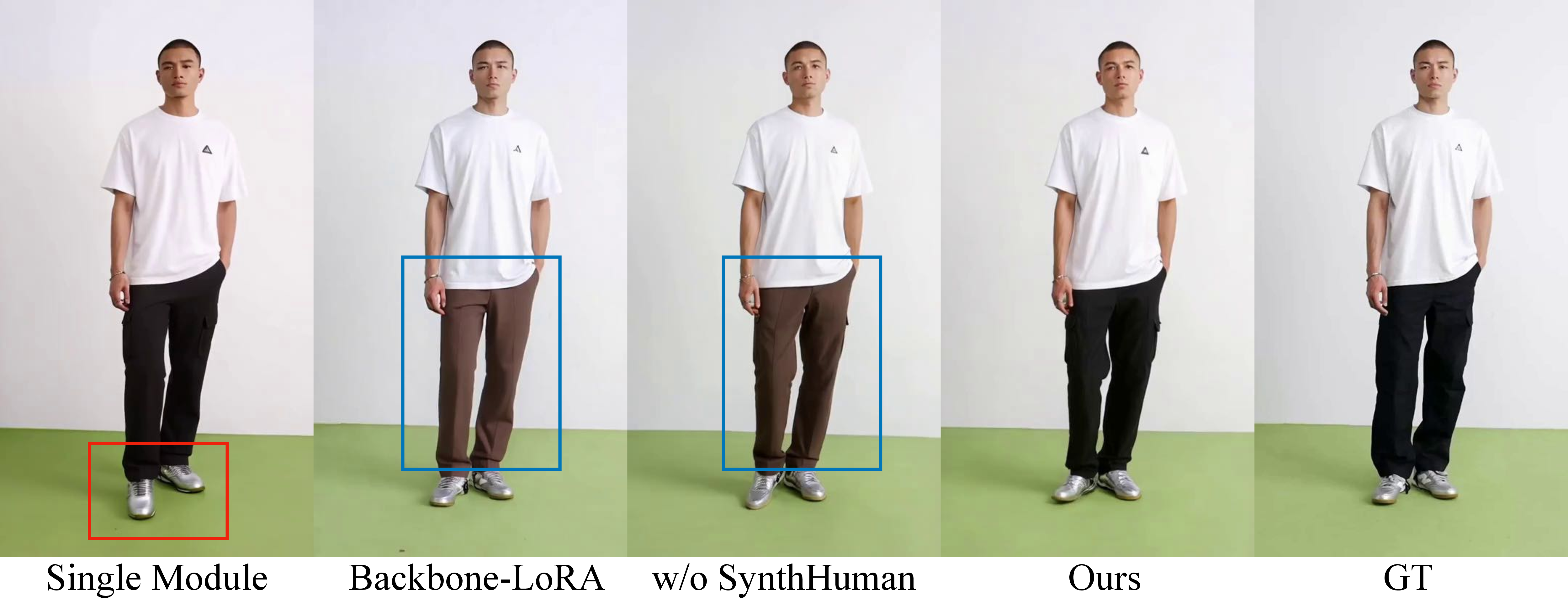
Figure 6: Ablation studies show competitive weaknesses in baseline designs concerning pose adherence and garment transfer.
The architecture is natively capable of multi-garment transfer: simultaneous transfer of upper and lower garments, with fine-grained logo and structural preservation and strong temporal coherence.

Figure 7: Multi-garment transfer scenarios, exhibiting preservation of fine-grained logos and robust consistency across animation frames.
Owing to in-the-wild supervision, Vanast generalizes to garments extracted from unconstrained sources, overcoming pose and lighting discrepancies endemic to Internet imagery.

Figure 8: In-the-wild garment transfer using TikTokDress images, with superior cross-pose and cross-scene adaptation.
The garment interpolation mechanism enables zero-shot transfer and morphing between styles, with seamless semantic blending across garments without requiring post hoc finetuning.

Figure 9: Zero-shot garment interpolation and transfer, modulated by the interpolation weight γ.
Theoretical and Practical Implications
The integration of synthetic triplet supervision, scalable triplet curation, and dual conditional modules provides a template for future work leveraging large-scale compositional control in generative video models. Beyond fashion and e-commerce, the methodology has immediate value for avatar generation, entertainment, and telepresence applications requiring coherent multi-attribute control in temporally extended outputs.
Theoretically, the results suggest that modularized attribute conditioning can effectively circumvent the entanglement issues observed in monolithic conditional architectures, provided that the data pipeline produces sufficiently diverse and attribute-disentangled samples. The synthetic triplet paradigm offers a scalable solution for self-supervised data construction in related domains.
Looking forward, Vanast's approach can be extended to full-body avatars, arbitrary accessories, and fine-grained kinematic editing, as advancements in VLM and inpainting models further improve synthetic annotation. The demonstrated zero-shot interpolation and strong out-of-distribution performance signal the viability of large-scale generalized compositional video synthesis in other identity/attribute domains.
Conclusion
Vanast sets a new benchmark for human-centric compositional video generation, unifying garment transfer and human image animation in a single, high-fidelity pipeline. Through synthetic triplet supervision and a dual-module architectural design, Vanast achieves state-of-the-art garment fidelity, pose adherence, and identity preservation, substantially outperforming modular two-stage approaches. The methodology introduces a scalable foundation for continued advances in attribute-controlled human video synthesis and supports seamless extension to multi-garment, in-the-wild, and interpolative scenarios.
(2604.04934)
