- The paper introduces MMF-BEV, which employs hybrid deformable attention to effectively fuse 4D radar and camera data for robust BEV 3D object detection.
- The methodology leverages BEVDepth and RadarBEVNet branches with bidirectional cross-attention, ensuring balanced semantic and geometric representation.
- Experimental results demonstrate that MMF-BEV outperforms naive fusion techniques, achieving up to 69.2% mAP in safety-critical regions on the View-of-Delft dataset.
Multi-Modal Sensor Fusion using Hybrid Attention for Autonomous Driving
Overview
The presented work introduces MMF-BEV, a hybrid deformable attention-based radar–camera fusion architecture for Bird’s Eye View (BEV) 3D object detection, specifically targeting safety-critical perceptual tasks in autonomous driving. The framework leverages robust geometric cues from 4D radar and dense semantic features from monocular camera input, systematically evaluating the interplay of intra-modal and cross-modal deformable attention mechanisms within a unified BEV space. Sensor contribution analysis is conducted to offer interpretable insights into the complementary behavior of the two modalities, utilizing the View-of-Delft (VoD) 4D radar dataset as a comprehensive benchmark.
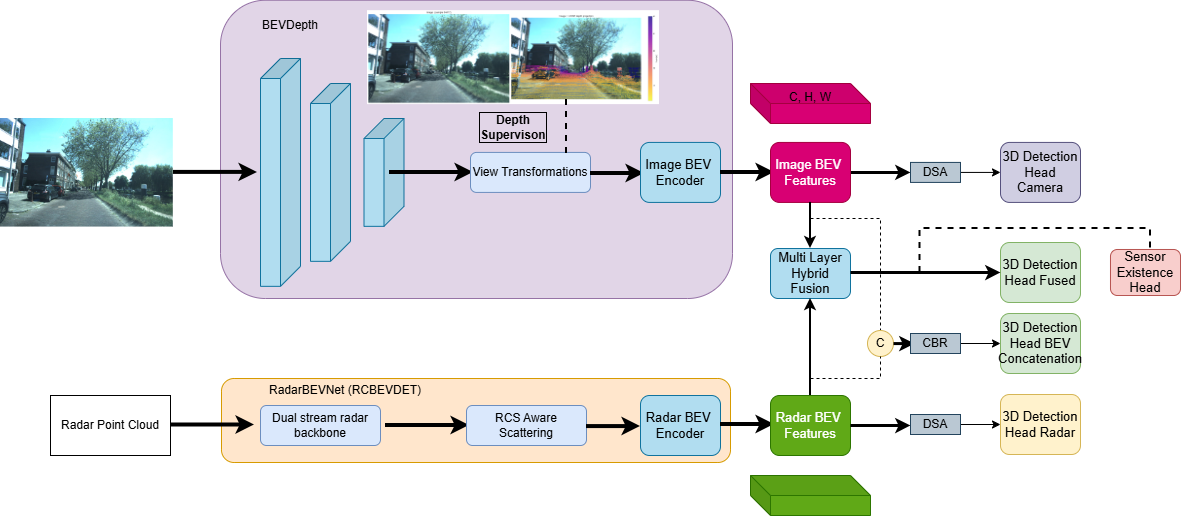
Figure 1: Overview of the MMF-BEV pipeline: BEV features from camera (via BEVDepth) and radar (via RadarBEVNet) are refined with Deformable Self-Attention, then fused using cross-modal hybrid attention mechanisms for 3D object detection.
Depth estimation in monocular camera pipelines is inherently ambiguous, especially in a safety-critical BEV context, manifesting as unreliable geometry and substantial performance gaps. 4D radar, by contrast, provides precise ranging, Doppler velocities, and resilience in adverse conditions but lacks semantic richness. Prior fusion methods often fall short in cross-modal spatial alignment, particularly for challenging scenarios involving small, vulnerable road users at long distances. MMF-BEV strategically combines recent advances—including BEVDepth-based depth prediction, RadarBEVNet, and deformable attention—but extends beyond baseline architectures (such as RCBEVDet [lin2024rcbevdet]) by providing a systematic, interpretable analysis of both self- and cross-attention mechanisms and per-bin sensor contributions.
MMF-BEV Architecture
MMF-BEV consists of three major components: a BEVDepth-based camera encoder, RadarBEVNet for 4D radar encoding, and a multilayer hybrid fusion module. Both branches are equipped with Deformable Self-Attention (DSA) to refine modality-specific context before information is exchanged and fused via Deformable Cross-Attention (DCA). This architectural symmetry (camera→radar and radar→camera queries) ensures both semantic and geometric consistency across modalities.
- Camera Branch: Input images are transformed to BEV features through depth-conditioned pooling and DSA. Explicit depth supervision (using LiDAR) improves geometric localization over purely photometric baselines.
- Radar Branch: Aggregates temporally accumulated 4D radar sweeps, encoding geometric context with dual-stream backbones (PointNet-based and transformer-based) and Distance-Modulated Self-Attention. Final RCS-aware BEV features are extracted post-scattering and encoded via a SECOND-style network.
- Hybrid Fusion: As illustrated in Figure 1, cross-attention is performed bidirectionally, followed by concatenation with DSA-refined features and multi-layered CBR-based aggregation. This mitigates modality-specific failures (e.g., radar sparsity or camera depth ambiguity) and enforces complementary representation.
Training Strategy and Optimization
A decoupled two-stage training process stabilizes the challenging optimization in fusion contexts:
- Stage 1 (Camera Pretraining): BEVDepth + DSA is trained with explicit depth supervision. Camera weights are frozen after convergence.
- Stage 2 (Fusion Training): The radar branch and fusion modules are trained, with camera parameters fixed to prevent degradation of the depth estimation representations.
This separation effectively reduces negative mutual interference between monocular depth learning and cross-modal alignment, significantly improving final convergence quality.
Experimental Validation on View-of-Delft
The MMF-BEV framework is evaluated on the VoD dataset, both on the full annotated area and in a safety-centric driving corridor region of interest (ROI). Key empirical findings include:
- Camera-only (monocular) models yield highly limited mAP (~22.3% full/38.15% ROI), with profound depth-induced failures particularly for pedestrians.
- Radar-only models achieve substantially higher mAP (~43.3% full/63.4% ROI), evidencing strong spatial reliability but weak semantics.
- Direct BEV concatenation of unimodal features naively improves mAP over individual modalities but performs worse than attention-based fusion, indicating the importance of explicit spatial alignment.
- Full MMF-BEV (deformable hybrid fusion) achieves competitive results: 48.9% mAP (full area) and 69.2% mAP (ROI), closely matching or surpassing contemporary fusion baselines such as RCBEVDet [lin2024rcbevdet] and RCFusion [zheng2023rcfusion], with particular strengths in car localization due to robust radar anchoring.
BEV Feature Visualization

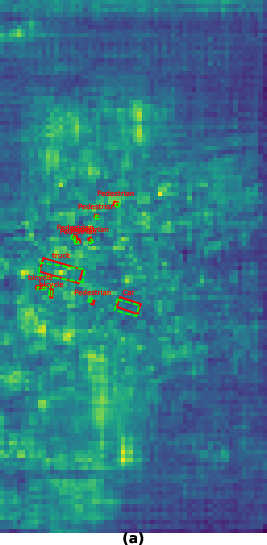
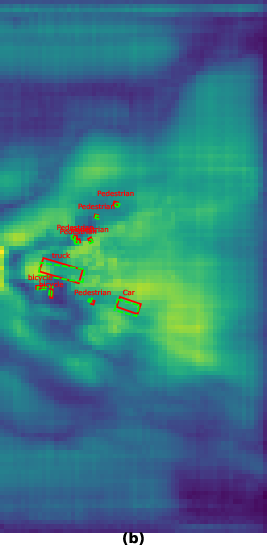
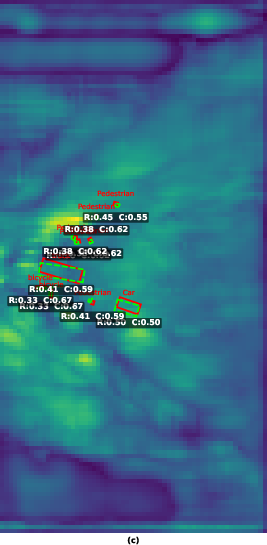
Figure 2: Comparison of BEV feature maps (VoD scene 00000). Image-query cross-attention produces diffuse, semantic-rich maps; radar-query yields spatially focused activations; fusion sharpens overall localization, especially for large objects.

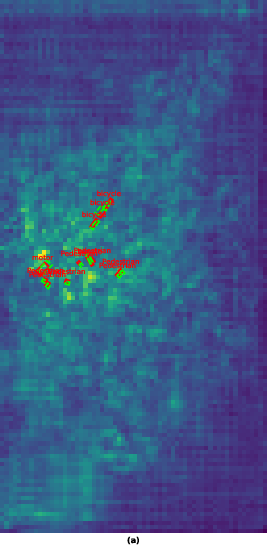
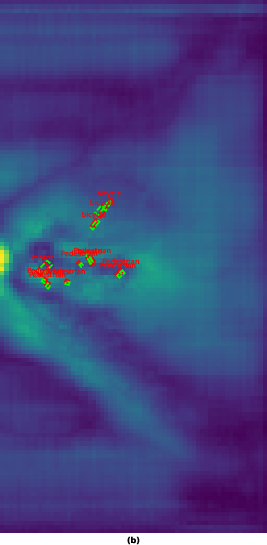

Figure 3: BEV feature representation for scene 00033, illustrating consistent modality-specific and fused feature allocation.


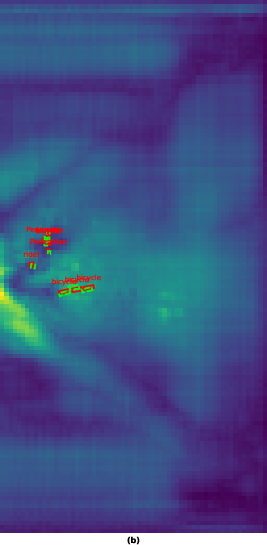

Figure 4: Scene 00102, where radar queries distinctly localize large, RCS-dominant objects, with fusion enhancing geometric precision.
Qualitative comparisons reinforce the complementary dynamics: camera queries accumulate semantic texture but suffer from spatial diffusion. Radar queries, by anchoring to physical returns, retain spatial sharpness but are semantically sparse. Fusion achieves balanced responses, preserving geometric integrity and semantic discriminability.
Sensor Contribution Analysis
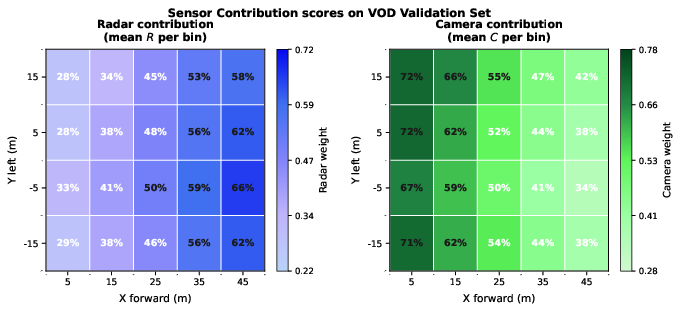
Figure 5: Sensor contribution maps in BEV space on the VoD validation set; left shows radar dominance at long range, right emphasizes camera dominance in the near field.
By extracting L2 norms of BEV features per cell and normalizing relative modality contributions, MMF-BEV reveals interpretable spatial patterns:
- Near-field (X<15 m): Camera features dominate (65–72%) due to reliable depth and high pixel coverage.
- Far-field (X>30 m): Radar features dominate (>55%) as depth ambiguity grows and radar spatial anchors sustain localization.
- Object Class: Cars and cyclists (large RCS) leverage radar-based localization; pedestrians depend more heavily on visual semantics due to weak RCS and erratic motion.
This analysis underpins the attention module's adaptive, spatially resolved fusion policy.
Implications and Future Directions
The MMF-BEV design demonstrates that effective fusion in BEV object detection critically depends on explicit, learnable spatial alignment of complementary modalities. The hybrid deformable attention mechanism not only narrows the performance gap to the best published methods but also improves interpretability, a requisite for certifiable AI in automotive standards (e.g., ISO/PAS 8800:2024).
Further developments will address:
- Advanced radar backbone architectures tailored for 4D radar distributions.
- Enhanced depth and uncertainty estimation in the camera branch, and the extension to multi-view/multi-camera regimes.
- Adaptive or uncertainty-aware transformer architectures for more robust cross-domain correspondence.
- Generalization to datasets with richer long-range annotation (e.g., aiMotive, NVIDIA Physical AI [matuszka2022aimotive]), leveraging MMF-BEV’s modularity for scalable deployment.
Conclusion
MMF-BEV provides a systematic methodology for radar–camera BEV fusion, leveraging deformable self- and cross-attention to resolve the geometric–semantic tradeoff inherent in multi-modal autonomous perception. Empirical analysis confirms the practical necessity and interpretability benefits of attention-based alignment over naive concatenation. The framework's results support further architectural and standardization advances, highlighting structured attention as a cornerstone for certifiable perception systems in automotive autonomy.

