- The paper introduces a stage-aware hybrid GPU execution model that fuses cryptographic operations to reduce DRAM traffic and latency in privacy-preserving queries.
- It optimizes data layouts for NTT and GEMM computations, achieving up to 305.7× higher throughput and significantly reducing memory overhead.
- Multi-GPU orchestration alongside extensive pipelining techniques enables scalability and sub-millisecond latencies on GB-scale databases, setting a new performance standard.
Background and Motivation
Lattice-based Private Information Retrieval (PIR) protocols enable privacy-preserving queries on public databases without revealing access patterns; however, such cryptographic primitives introduce severe server-side computational and memory bottlenecks due to heavy use of homomorphic encryption (HE) and associated polynomial arithmetic over large moduli. The OnionPIR family of schemes exemplifies state-of-the-art single-server PIR with minimal communication cost but high server workload. Modern GPUs offer massive parallelism and memory bandwidth, making them attractive for accelerating these cryptographic workloads, especially when exploiting multi-client batching to amortize costs. Despite this theoretical hardware fit, naive GPU implementations exhibit severe cache and bandwidth bottlenecks due to phase-specific working set and data layout challenges, notably the cache-capacity wall in batched workflows and a structural conflict between NTT-optimized and GEMM-optimized data layouts.
Computation Pipeline and Systemic Bottlenecks
GPIR targets OnionPIRv2, which organizes PIR queries into three computationally distinct phases: ExpandQuery, RowSel, and ColTor.
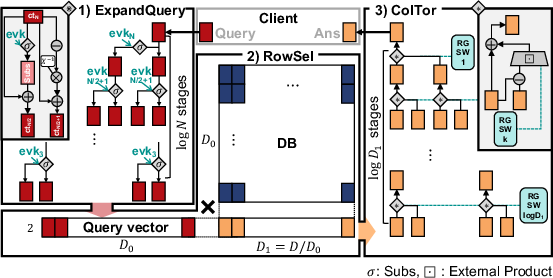
Figure 1: The end-to-end computation flow for OnionPIRv2, highlighting the transformation and selection phases required per encrypted query.
ExpandQuery recursively expands a compact encrypted query into a large set of HE ciphertexts (ct) via binary-tree homomorphic substitutions mainly involving digit decomposition, inverse/forward NTT, and polynomial arithmetic. RowSel executes a large batch of encrypted row selections as independent GEMMs using the NTT-domain, RNS-packed ct outputs, but is encumbered by the physical layout imposed by prior NTT steps. ColTor completes the PIR with a tournament-like column selection, again invoking external product operations (with digit decomposition) to reduce the ct outputs to the correct index.
These phases impose heterogeneous data partitioning requirements (Figure 2): NTTs need limb-major layouts (in RNS parlance, "rows" of the $4N$ prime-packed polynomial coefficients), GEMMs are optimal with k-major or m/n-major layouts, while digit decomposition aligns coefficient-wise. Transitioning between these layouts induces costly data movement and frequent cache-line invalidations, especially when working sets per batch and per protocol stage breach the 96 MB L2 cache, severely amplifying off-chip DRAM transactions.
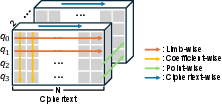
Figure 2: Comparison of partitioning strategies for core PIR operations, illustrating the mismatch between ideal layouts for NTT, coefficient operations, and GEMMs.
A detailed roofline model (Figure 3) exposes these architectural consequences: under batching, RowSel shifts from a memory-bound regime (dominated by D0×D1 DB access) to being compute-bound but suboptimal—the current layout reduces throughput to a fraction of peak IMAD. Conversely, ExpandQuery and ColTor move deeper into DRAM-bottlenecked regimes under larger batches due to explosive transient working sets in digit decompositions and inadequate data reuse.
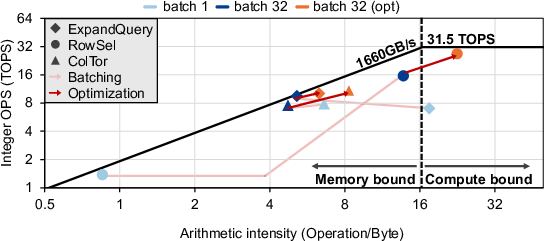
Figure 3: Roofline analysis of ExpandQuery, RowSel, and ColTor on RTX 5090, showing compute/memory throughput and bottleneck shifts with working set size.
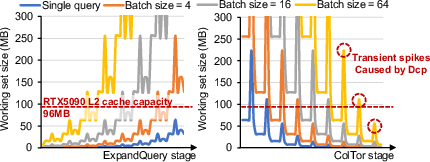
Figure 4: Working set growth per operation across expanding batch sizes, illustrating the cache pressure induced during ExpandQuery and ColTor.
Stage-Aware Hybrid Execution
The paper proposes a stage-aware hybrid execution paradigm to dynamically select kernel granularity for ExpandQuery and ColTor phases. When the working set is L2-resident, fine-grained (operation-level) kernels are used to maximize occupancy and parallel resource utilization. When working sets exceed the cache, GPIR fuses all stage-specific operations into monolithic (stage-level) kernels per ct/tree-node, physically retaining all transient intermediates in SM-local registers/shared memory to minimize DRAM churn. Multi-client batching ensures enough parallel ciphertexts are available to saturate hardware with these coarser kernels while confining working set spikes and significantly reducing DRAM traffic and latency.
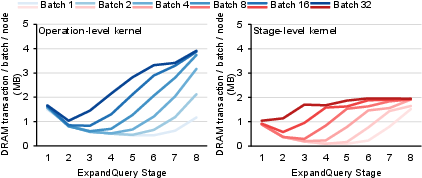
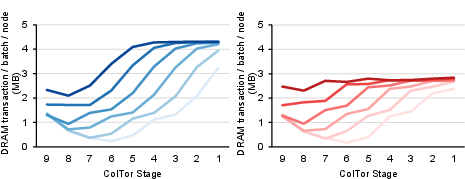
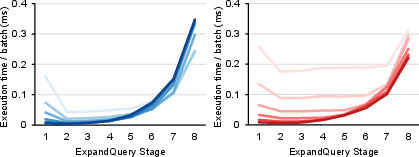
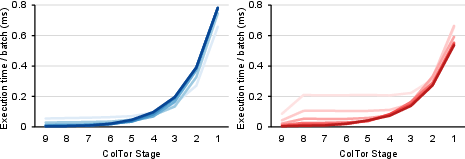
Figure 5: DRAM transactions and execution time for operation-level vs. stage-level kernels, showing stage-dependent traffic and occupancy trade-offs.
The transition point between kernel types is statically defined based on batch size and protocol tree depth, ensuring that L2 bandwidth is maximized before DRAM pressure dominates (as empirically validated in Figure 6).
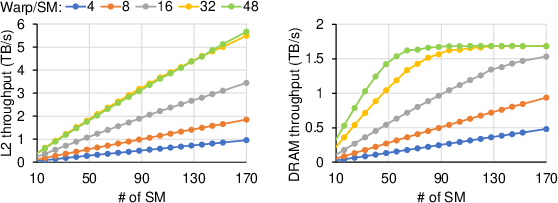
Figure 6: Bandwidth utilization under occupancy scaling, contrasting L2 scaling needs versus DRAM saturation endpoints.
Data Layout–Aware RowSel Optimizations
GPIR identifies that the conventional NTT-centric, p-major memory layout fundamentally impedes efficient, large-tile GEMM computation required for batched RowSel. The system introduces an explicit transposition step, reorienting ct and sothatlargetilescanbecomputedwithhighresourceefficiencyusingstandardk/m/n−majorlayouts,directlyenablingincreasedtiledimensions,reducedglobaltransactions,andhigherSMoccupancy.Forinstance,ina2GBDBwithbatch32onRTX5090,optimizedtilingyields1.76×highercomputethroughputandincreasedoccupancy.<imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2604−04696/data−layout−data.png"alt="Figure7"title=""class="markdown−image"loading="lazy"></p><p><imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2604−04696/data−layout−baseline.png"alt="Figure7"title=""class="markdown−image"loading="lazy"></p><p><imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2604−04696/data−layout−transpose.png"alt="Figure7"title=""class="markdown−image"loading="lazy"><pclass="figure−caption">Figure7:SchematicofrequiredRowSelGEMMs(a),andcomparisonofbaseline(p−major,b)andtransposed(k−major,c)tilingapproaches.</p></p><p>However,repeatedglobalmemorytranspositionsbefore/aftereachbatchedRowSelkernelcoulddominateoveralllatency.TheauthorsresolvethisbypipeliningtransposeandGEMMkernelsalongthepdimension:RNS−primeparallelismisexploitedvia<ahref="https://www.emergentmind.com/topics/kernelbench−cuda"title=""rel="nofollow"data−turbo="false"class="assistant−link"x−datax−tooltip.raw="">CUDA</a>streamswithchunkingovertheNpolynomialcoefficientaxis,furtheroverlappedandefficientlyscheduledusingCUDAGraphs.Thismulti−levelpipelininghidesupto6.7<imgsrc="https://emergentmind−storage−cdn−c7atfsgud9cecchk.z01.azurefd.net/paper−images/2604−04696/pipelining.png"alt="Figure8"title=""class="markdown−image"loading="lazy"><pclass="figure−caption">Figure8:PipelinedexecutiondesignforRowSel,usingprime−levelandN−chunkedpartitioningtooverlaptranspositionsandcomputations.</p></p><h2class=′paper−heading′id=′multi−gpu−orchestration′>Multi−GPUOrchestration</h2><p>GPIRsupportsboththroughput−andscale−outviamulti−GPUsystems.Threeexecutionparadigmsareanalyzed:purebatchparallelism(DBreplication,near−linearQPSscaling), sharding (partitioning DB across devices, with partial result aggregation for scale-up), and all-gather for batched ExpandQuery (distributing ExpandQuery load and aggregating expanded ct using high-bandwidth interconnects). The protocols are carefully profiled for inter-GPU communication: RowSel and ColTor aggregation costs are negligible, but ExpandQuery all-gather requires NVLink to prevent throughput loss at high batch sizes.
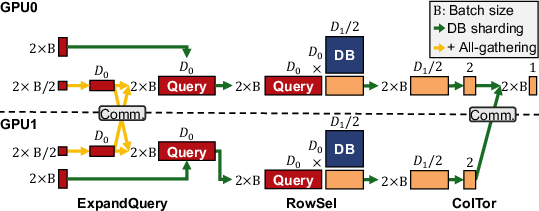
Figure 9: Multi-GPU PIR execution with DB sharding and all-gather patterns, demarcating communication points.
Quantitative Evaluation
A comprehensive ablation study is presented (Figure 10), evaluating GPIR on an RTX 5090 at multiple DB and batch sizes, isolating the effects of hybrid execution, transposed RowSel, k0-dimension pipelining, and multi-GPU scaling. The system delivers up to 305.7× higher throughput than PIRonGPU and 1.96–2.29× end-to-end speedup over a tightly optimized modern baseline. Notably, these gains persist as DB size increases, demonstrating scalability not observed in prior PIR GPU implementations, which sharply degrade above 2GB. DRAM savings of up to 1.83× (ExpandQuery) and 1.52× (ColTor) over prior work are shown (Figure 11).
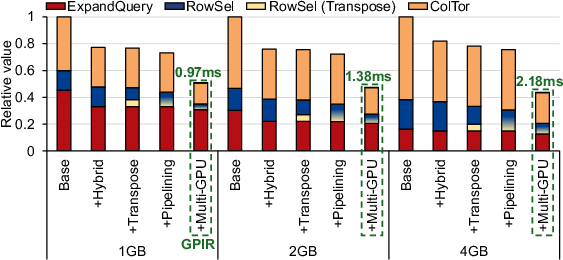
Figure 10: Execution time per batch after incremental application of each optimization technique.
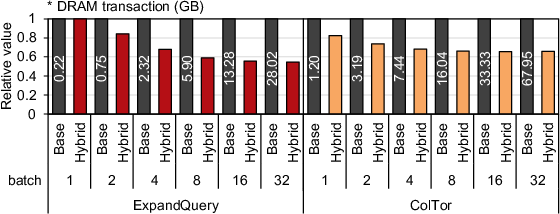
Figure 11: DRAM traffic reduction for ExpandQuery and ColTor under batching with hybrid kernels, normalized to baseline kernels.
Multi-GPU scaling experiments (Figure 12) indicate 1.73×–1.94× throughput scaling with two GPUs, with NVLink essentially eliminating communication as a bottleneck.
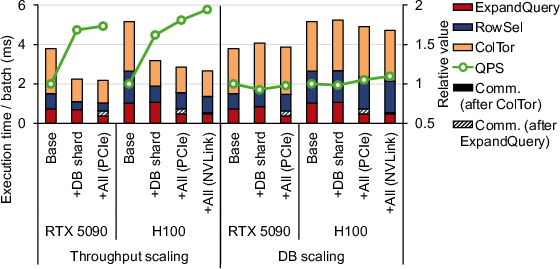
Figure 12: Throughput and scalability under multi-GPU sharding and all-gather strategies using PCIe or NVLink.
Implications and Future Trajectories
GPIR decisively demonstrates that architectural software/hardware co-design—including phase- and data layout–adaptive execution and fine-grained pipelines—is essential in realizing the full potential of high-throughput, single-server PIR. The results suggest that properly engineered software can render even GB-scale PIR practical on contemporary GPU platforms, without custom accelerators. Multi-GPU approaches support both larger databases and greater batch-QPS, suggesting deployment feasibility for use-cases such as private search, DNS, and blockchain data access.
On the theoretical front, the work reveals that phase-wise analytic modeling is fundamental in mapping cryptographic protocol complexity to parallel hardware. Practically, the outlined optimizations set a new performance reference for single-server PIR, potentially informing GPU-aware cryptographic library and protocol design. This carries cross-domain implications for large-scale privacy-preserving analytics, ML inference, and federated data property testing, where oblivious access patterns are required.
Given contemporary interest in HE, FHE, and privacy infrastructure, the methods in GPIR are immediately relevant for constructing secure, high-throughput cloud services. Companion future work could explore asynchronous protocol variations that interleave protocol phases (allowing for further hardware pipelining), cross-node load balancing, and architectural extensions to further reduce data layout friction at the hardware level.
Conclusion
GPIR provides a blueprint for practical, high-performance PIR on GPUs by resolving bottlenecks at the intersection of homomorphic cryptography, memory hierarchy, and parallel hardware. The demonstrated architectural awareness—hybrid kernel selection, layout-conscious execution, and orchestration for multi-GPU scaleout—enables GB-scale PIR queries at sub-millisecond latencies, setting a standard for software-only solutions in privacy-preserving database services (2604.04696).