- The paper introduces AMuFC, an adaptive fact-checking framework that integrates a visual evidence necessity assessor alongside a verifier.
- Experiments reveal that indiscriminate fusion of visual evidence can degrade accuracy, highlighting the need for dynamic filtering.
- Error analyses show AMuFC’s balanced predictions and superior performance over verifier-only models, aligning with effective human workflows.
Adaptive Multimodal Fact-Checking: Challenging the Necessity of Visual Evidence
Automated multimodal fact-checking tasks typically operate under the implicit assumption that visual evidence, in addition to textual evidence, universally enhances verification reliability. However, this assumption is not rigorously validated across claim types and evidence configurations. The central research question examined is whether visual evidence is always necessary for multimodal claim verification in the presence of textual evidence. The paper investigates this through systematic experiments and error analyses, revealing that indiscriminate inclusion of visual evidence can degrade overall performance. This finding has immediate implications for the design of robust, trustworthy automated fact-verification systems.

Figure 1: Illustration of the research question: This paper examines whether visual evidence is necessary for verifying a claim when textual evidence is available.
Analysis of Visual Evidence Necessity
A comprehensive analysis across multiple datasets and VLM architectures demonstrates that naive multimodal fusion does not guarantee superior results. Empirical evaluation across four model families (Qwen2-VL-7B, Llama-3.2-11B-Vision, GPT-4o, Gemini-2.5-Pro) on the MOCHEG benchmark reveals that adding visual context to text-based evidence either fails to improve accuracy or introduces significant error, with the most pronounced decrease (−0.084 accuracy, −0.102 F1) observed for Llama-3.2-11B-Vision. Oracle experiments, where an upper-bound “correct-modality” selector is used, demonstrate statistically significant improvements, motivating an “adaptive” multimodal evidence paradigm.
Qualitative annotation of evidence types highlights critical distinctions: “necessary” visual evidence provides non-redundant, complementary, or claim-critical context, whilst “unnecessary” evidence either repeats information or introduces noise. Chi-square analysis confirms a significant interaction between claim category and evidence utility, advocating for dynamic filtering and selection.
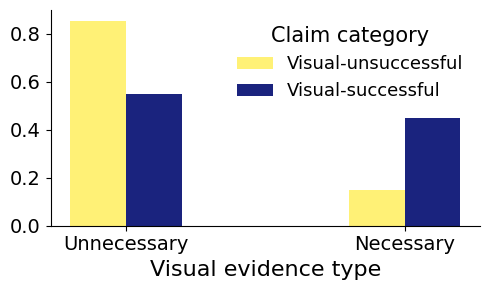
Figure 2: Distribution of visual evidence types across claim categories, illustrating their associations.
The AMuFC Framework
Addressing the pitfalls of static evidence fusion, the paper proposes AMuFC (Adaptive Multimodal Fact-Checking), an agent-based architecture comprising a Retriever, an Analyzer, and a Verifier.
- The Retriever executes standard evidence retrieval over a fixed knowledge base.
- The Analyzer (a specialized VLM) assesses, via natural-language reasoning, whether visual evidence is indispensable for supporting/refuting the claim, given both evidence modalities.
- The Verifier (a second VLM) integrates the Analyzer's judgment, the claim, and evidence, and issues the veracity decision.
This explicit modeling of “visual evidence necessity” marks a departure from prior rigid fusion and is theoretically aligned with differentiated processing in human expert workflows, where evidence relevance and synergy are assessed before making judgments.

Figure 3: Overall pipeline of AMuFC. Given the retrieved evidence, the Analyzer and Verifier assess the necessity of visual evidence and predict claim veracity.
Empirical Evaluation
AMuFC is benchmarked against recent retrieval-augmented multimodal fact-checkers, including MOCHEG, LVLM4FV, HGTMFC, and MetaSumPerceiver, utilizing both gold and retrieved evidence configurations. On the MOCHEG test set, AMuFC achieves accuracy of 0.612 and macro F1 of 0.600 with gold evidence—substantially outperforming all baselines. When relying on retrieved evidence, absolute performance decreases as expected, but the relative margin for AMuFC remains strong.
Ablation studies dissect the contributions of the adaptive architecture. Variants omitting the Analyzer or including it only as a filtering component (w/o explanations) yield clearly lower performance. Experiments with unified models (merging Analyzer and Verifier roles), or Verifier-only Chain-of-Thought justifications, fail to close the gap, highlighting the benefit of a dedicated necessity-assessment agent and deep integration of its output into the veracity judgment phase.
Further, cross-model analysis (open- vs closed-weight VLMs) shows Qwen2-VL as the most robust Verifier, with both Llama-3.2-V and closed-source models serving effectively as Analyzer. Case studies involving transfer to unseen domains (financial, open-web claims) substantiate the broad applicability of AMuFC.
Error Distribution and Qualitative Insights
A comparison of confusion matrices between AMuFC and a Verifier-only baseline uncovers systematic differences. The Verifier-only model suffers from over-prediction of the "Refuted" class, while AMuFC produces a more balanced error profile, especially improving "Supported" and "NEI" discrimination. The Analyzer's explanatory signal helps the Verifier to refrain from overconfident false positives and aligns model behavior better with real-world verification imperatives where abstaining (NEI) is preferable to incorrect assertions.
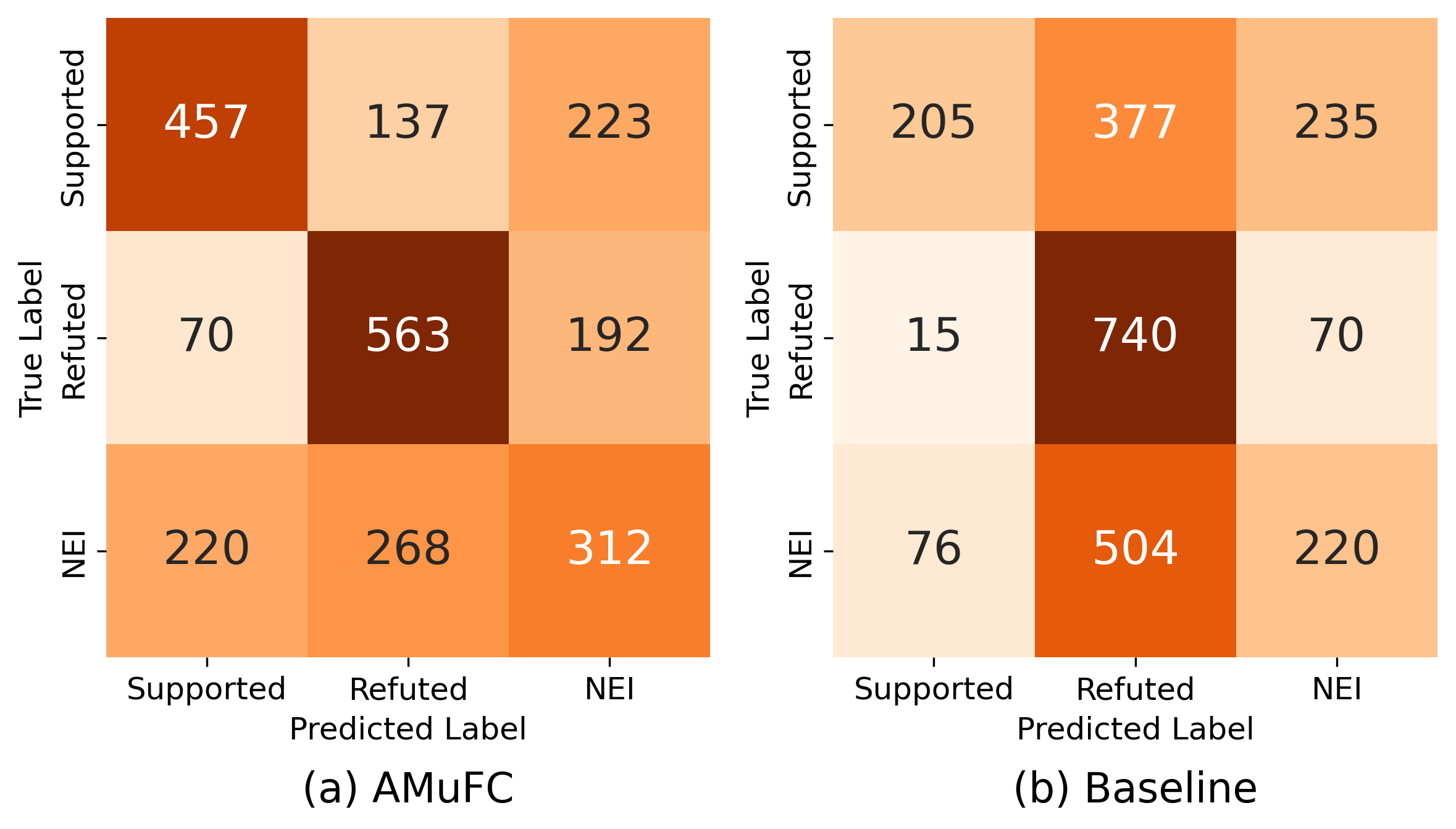
Figure 4: Distribution of confusion patterns for AMuFC compared with the Verifier-only baseline.
Practical and Theoretical Implications; Future Directions
The study decisively challenges the default paradigm of unimodal or indiscriminate multimodal fusion in automated fact verification. It provides strong evidence that explicit, instance-level evaluation of evidence necessity is required for system-level robustness, especially in the presence of noisy, irrelevant, or misleading images. Practically, this points toward integration of adaptive, agent-based collaboration as standard in high-stakes applications, including journalism, content moderation, and financial news.
From a modeling perspective, this work encourages further investigation of multi-agent VLM pipelines, dynamic modality gating, and reasoning heuristics for evidence utility. In addition, extensions to multilingual datasets, lower-resource regimes, and integration with advanced retrieval architectures (dynamic RAG, tool-augmented retrieval) are promising directions. Optimization of computational efficiency via miniaturized or specialized agents, in line with trends toward SLM-based agentic AI, remains an open engineering challenge.
Conclusion
This paper provides extensive empirical and analytical evidence that visual evidence is not inherently beneficial for all multimodal fact-checking scenarios and that its unnecessary inclusion can be counterproductive. By introducing a VLM-based necessity assessor in tandem with a dedicated verifier, AMuFC achieves state-of-the-art results and more closely emulates effective human workflows. This paradigm directly addresses intrinsic weaknesses of prior rigid fusion architectures and sets the stage for future advances in robust, efficient multimodal verification frameworks (2604.04692).

