- The paper introduces a novel triadic decomposition that splits each LLM layer weight matrix into sparse, low-rank, and binary components to enable training-free compression.
- It employs activation-aware pruning and truncated SVD, achieving up to 80% compression with significant perplexity reduction and improved zero-shot accuracy.
- The methodology enhances hardware efficiency and practical deployment on constrained devices, paving the way for energy-efficient on-device LLMs.
SLaB: A Sparse-Lowrank-Binary Decomposition for Efficient Compression of LLMs
Introduction
SLaB introduces a method for the compression of LLMs that leverages a triadic decomposition of each linear layer weight matrix into sparse, low-rank, and binary components. The framework directly targets the bottlenecks in computational and memory efficiency characteristic of modern LLM architectures, prioritizing deployment feasibility on constrained hardware without requiring retraining. The approach is noteworthy for its training-free compression, utilization of activation-aware pruning scores, and its demonstrated superiority over strong baselines, including SparseGPT and Wanda.
Methodological Framework
The SLaB framework decomposes a layer's weight matrix W into three mutually complementary matrices: a sparse matrix WS, a low-rank matrix WL, and a binary matrix WB, combined via the Hadamard product. The decomposition can be written as
W=WS+(WL⊙WB)
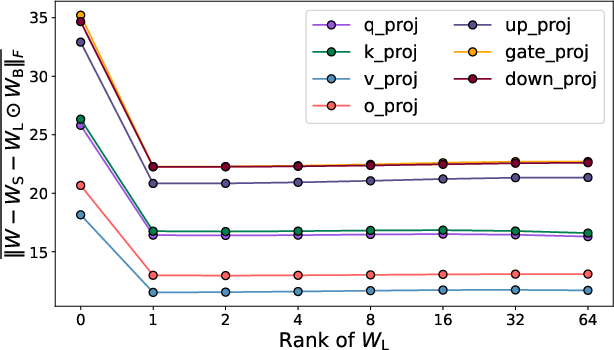
The optimization for each component employs an alternating scheme, drawing on robust principal component analysis techniques. Sparsity is imposed via activation-aware importance scores inspired by the Wanda approach, the binary matrix is assigned through sign functions, and the low-rank matrix is constructed by truncated SVD, leveraging Eckart–Young results.
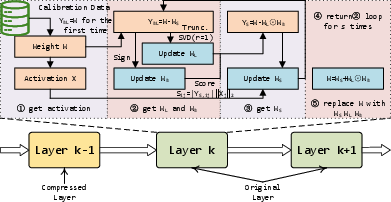
Figure 1: Overview of the SLaB framework.
The key design choices include:
Compression Efficacy and Empirical Analysis
Quantitative analysis demonstrates that SLaB consistently outperforms state-of-the-art one-shot pruning baselines across both unstructured and structured sparsity regimes, and at compression ratios up to 80%, on Llama-family models. Notably, at a 50% compression ratio on Llama-3.2 1B, the perplexity reduction reaches 36.04%, and zero-shot accuracy improvements of up to 8.98% are reported compared to the strongest baseline, under identical calibration and evaluation conditions.
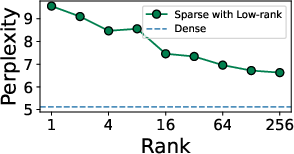
Figure 3: Perplexity comparison using only low-rank and sparse matrices under 50% compression illustrates inadequacy of standard combinations and motivates SLaB’s triadic approach.
Ablation studies indicate that the orthogonal incorporation of both the binary and low-rank matrices yields nonlinear compensation for the sparsity-induced degradation of expressivity, particularly critical at higher compression rates. Hyperparameter studies reveal that a rank-1 low-rank term is nearly optimal for practical purposes, and compression efficacy is stable as a function of reasonable choices of iteration counts and group sizes.
Theoretical and Practical Implications
SLaB’s approach—avoiding retraining entirely—exposes a new paradigm for LLM deployment in latency- and energy-constrained environments. The binary component contributes to hardware efficiency, while the low-rank term addresses the expressivity limits of sparse models alone. This arrangement enables on-device large language modeling for contexts where compute and memory are non-negotiable constraints.
On a theoretical level, the SLaB methodology positions itself at the intersection of contemporary trends in structured sparsity, quantization, and low-rank adaptation. Unlike straightforward additive or sequential combinations of compression modalities, SLaB’s Hadamard product-based marriage of low-rank and binary structure appears to sidestep loss barriers observed with simpler formulations.
Outlook and Future Directions
SLaB motivates several extensions. Potential avenues include hierarchical or dynamic allocation of rank and sparsity across layers, layer-specific binary codebook learning, and integration with emerging hardware accelerators designed for binary and low-rank computation. The absence of retraining requirements opens direct applicability to any LLM with accessible weights, extending the practical reach of the method.
Advances in model architectures and training regimes may further enhance SLaB’s efficacy, particularly as model scale and deployment needs continue to diverge. The framework has promising intersections with federated learning, privacy-aware on-device inference, and scalable model distribution.
Conclusion
SLaB delivers an explicit, systematic method for LLM compression that unites sparse, low-rank, and binary representations. The empirical results establish strong compression–quality Pareto improvements in the one-shot post-training regime, without necessitating retraining or intensive calibration. The triadic decomposition paradigm advances the toolkit for practical and efficient deployment of LLMs, and provides a foundation for subsequent research at the interface of structured model compression methodologies (2604.04493).