- The paper demonstrates a scalable LLM-assisted method that efficiently extracts and quantifies themes from millions of social media posts and interview data.
- It features a controlled user experiment where expert policy researchers reported improved speed and breadth over traditional analysis methods.
- The workflow is cost-effective and reveals both established and novel, community-specific insights aligned with authoritative policy reports.
LLM-Assisted Thematic Analysis for Policy Research: Evaluation and Implications
Introduction
This paper systematically evaluates an LLM-assisted workflow for thematic analysis in policy research. It addresses the challenge of rapidly synthesizing large-scale, unstructured data—such as Reddit discussions and chatbot-led interviews—to provide actionable insights to policy researchers. The study adapts the QuaLLM framework for scalable qualitative analysis, augments it with user-centred design, and benchmarks its outputs against authoritative policy reports. The investigation comprises two distinct studies: (1) a controlled user experiment with policy researchers, and (2) a comparative deployment using multimillion-post Reddit corpora and over a thousand chatbot interviews.
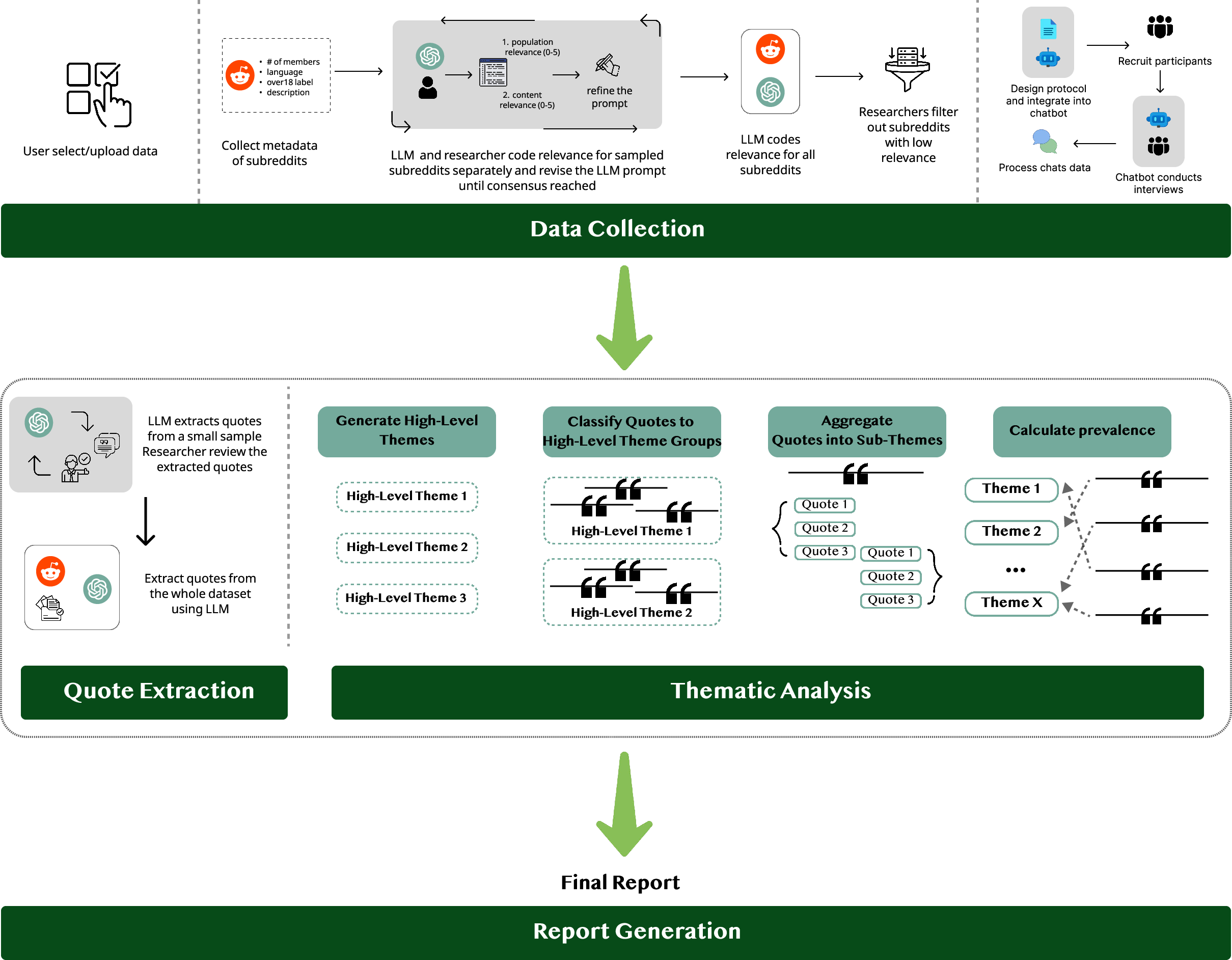
Figure 1: Overview of the workflow stages from data collection through report generation, orchestrated in four steps and grounded in the QuaLLM LLM-based framework.
Workflow Design and Rationale
The workflow is driven by several explicit design goals:
- Rapid scoping: Deliver survey-like maps of prevalent concerns, optimized for speed.
- Scalability: Ingest naturally-occurring large-scale public discourse, such as Reddit posts, and synthesize topic-specific themes.
- Source-awareness: Maintain explicit framing of analysis outputs as community- or corpus-specific, not population-generalizable.
- Prevalence guidance: Quantify and rank concerns based on their prominence in the data.
- Human oversight: Ensure researcher control via points of scope-definition and review.
QuaLLM is preferred over TopicGPT and LLooM due to its superior modularity, quick draft generation, explicit tie to source, and prevalence mapping at the quote level. The workflow itself consists of four stages: data collection, quote extraction, thematic analysis, and structured report generation.
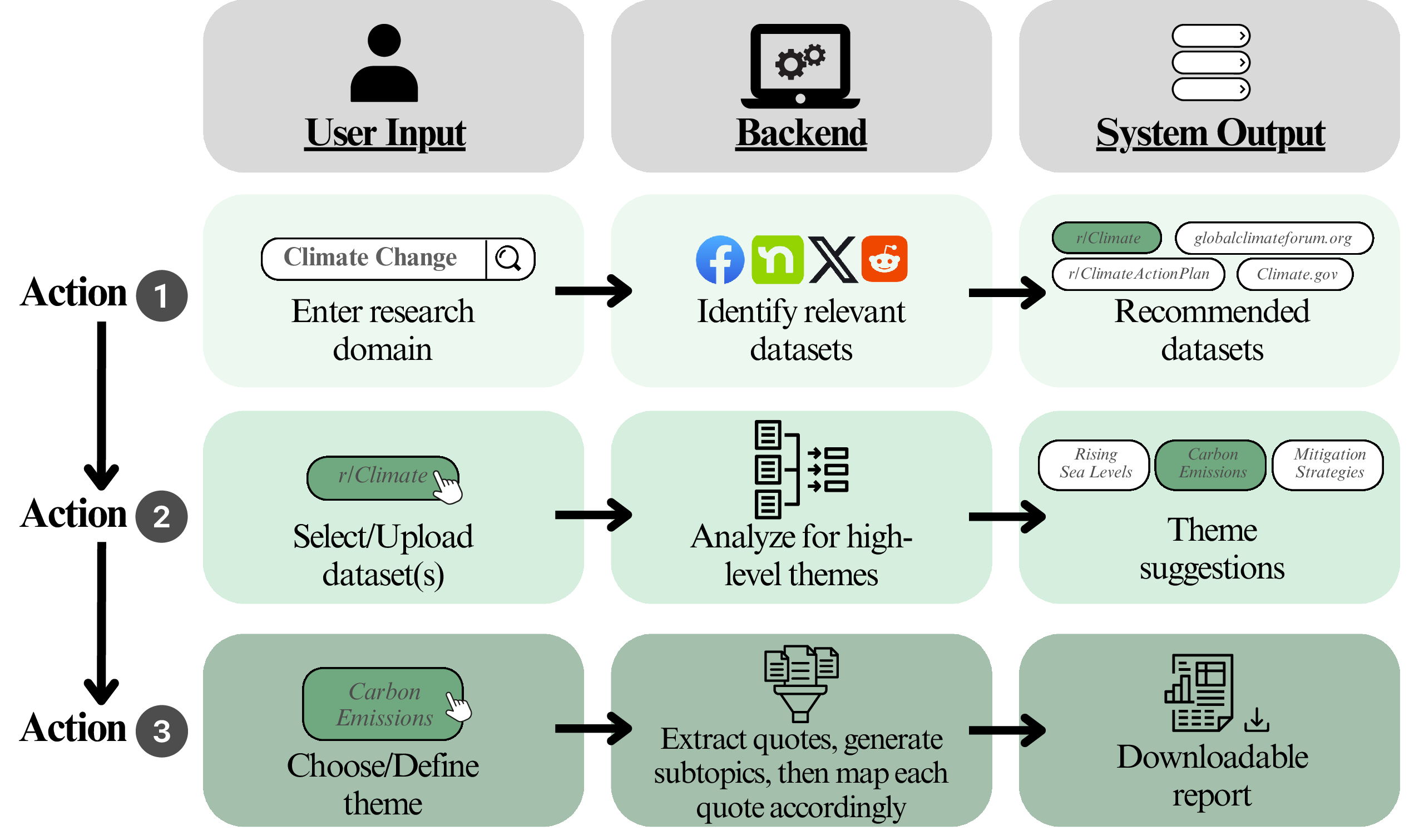
Figure 2: User interaction workflow: policy researchers specify a topic, select data, review AI-suggested themes, and generate downloadable reports through iterative human-AI collaboration.
Study 1: Policy Researcher Evaluation
A cohort of 11 expert policy researchers engaged in a controlled comparative study, using either the LLM-assisted workflow or their established research methods under time constraints across two topics (climate change, and social media's impact on minors). Qualitative and quantitative outcomes were aggregated.
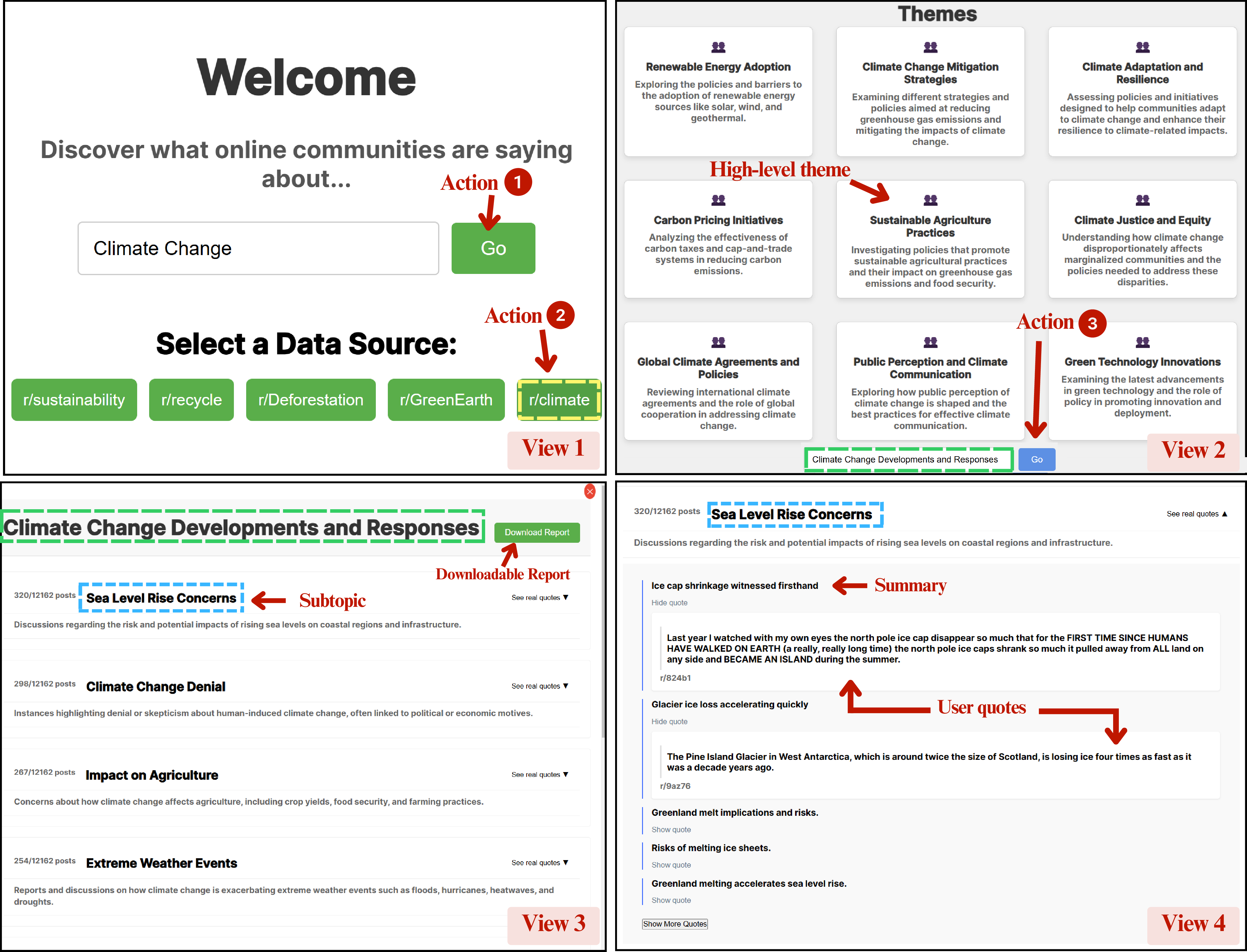
Figure 3: Screenshots illustrating the policy research workflow UI—from topic and data selection, through theme identification, to report generation with theme summaries and supporting quotes.
Figure 4: Timeline and structure for the user study, alternating topics and methods, with standardized templates for recording themes and anecdotes.
Key results include:
- Efficiency: On average, researchers extracted 2 more themes per topic and showed positive Likert-scale sentiment on speed and ease-of-use.
- Breadth: The workflow surfaced anecdotal evidence and themes not commonly captured in traditional polling or listening sessions.
- Cost reduction: Participants indicated notable savings compared to surveys and sessions, with the workflow running at sub-$1,000 scale for thousands of quotes.
- Integration: Researchers saw high value for early-stage exploration and background research, facilitating rapid scoping and gap identification.
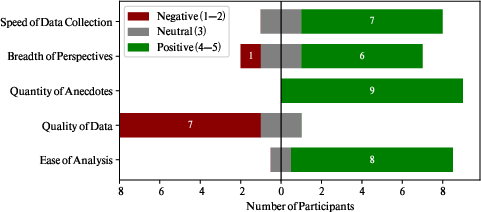
Figure 5: Diverging stacked bar chart visualizing participant Likert responses: ease of analysis and anecdote quantity scored highly; data quality concerns persist.
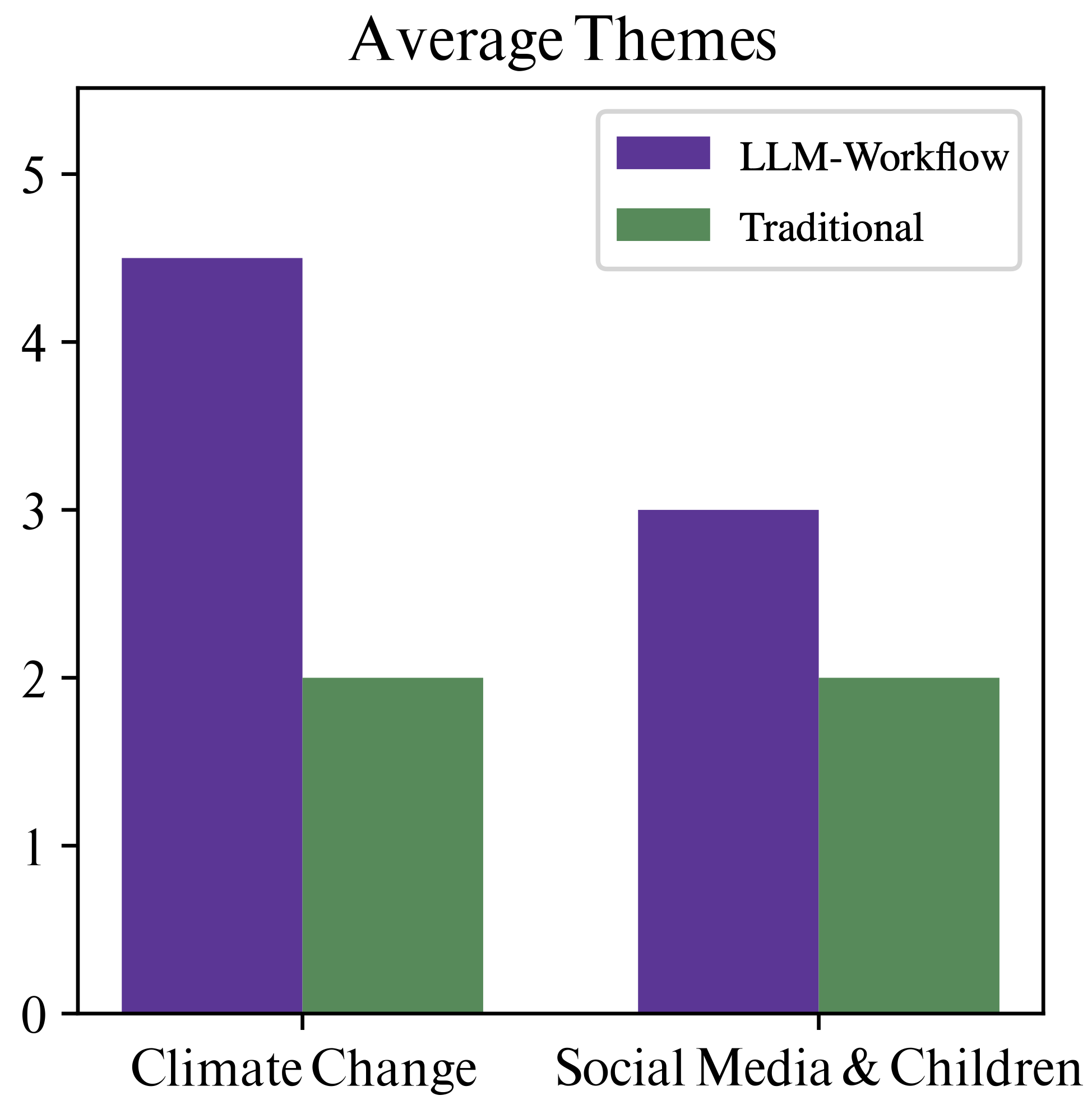
Figure 6: Bar chart comparing average numbers of themes gathered per method, showing that the workflow is an order of magnitude faster in the limited-duration test.
Study 2: Benchmarking Against Authoritative Reports
To address concerns of demographic representation and dataset breadth, Study 2 scales up both the corpus and methodological rigor:
- Reddit data: 5.5M posts, filtered from 40,000 subreddits using a structured LLM-driven screening protocol.
- Chatbot-led interviews: 1,058 U.S. adults, sampled via Prolific, with demographic metadata.
Both sources were analyzed through the same workflow pipeline and benchmarked via theme mapping against six authoritative reports from CBS News, Gallup, APA, Pew, and the World Economic Forum. The process included prompt-driven quote extraction, prevalence-guided theming, and manual verification.
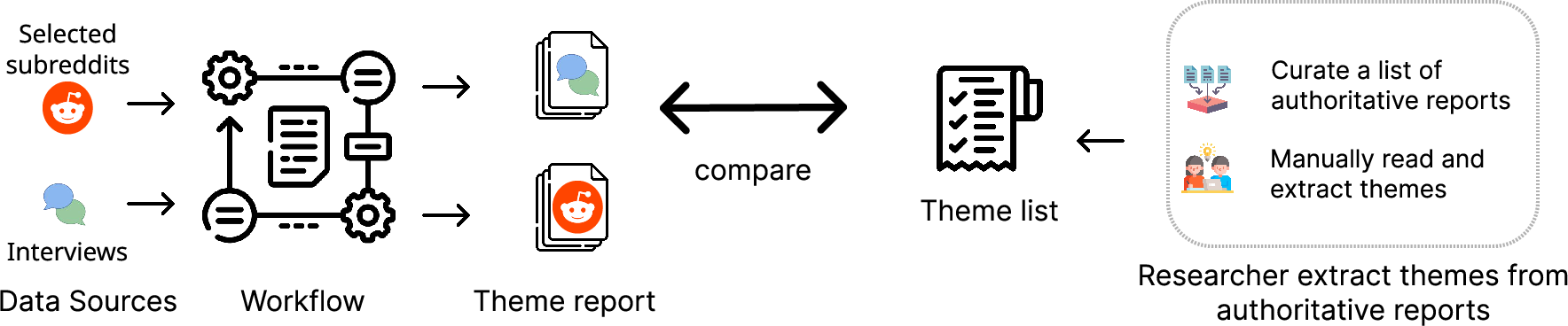
Figure 7: Evaluation pipeline showing application of the workflow to Reddit and interview data, with theme extraction referencing authoritative reports for alignment benchmarking.
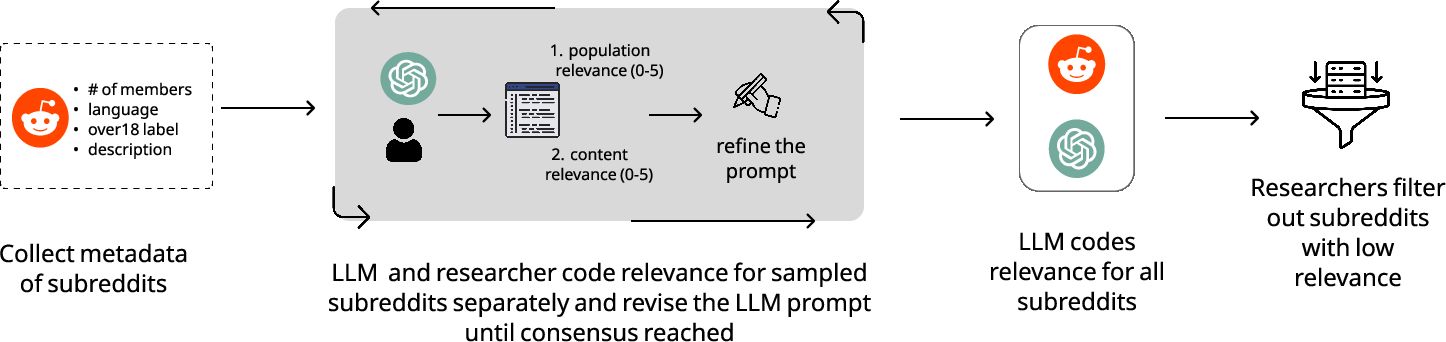
Figure 8: Subreddit selection workflow: metadata-driven filtering, LLM-assisted relevance ratings, and final pool construction for policy topic coverage.
Figure 9: Chatbot interview pipeline: protocol-driven Q-A segmentation, demographic collection, and workflow-driven thematic analysis.
Results: Coverage, Divergence, and Novelty
Thematic overlap with authoritative human-authored reports was substantial: 88.6% of identified themes appeared in Reddit or interview outputs, and most report themes were corroborated across these sources.
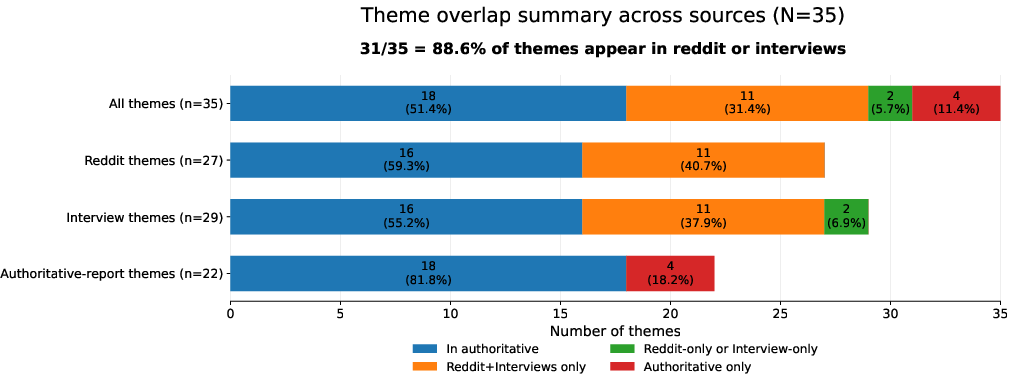
Figure 10: Stacked bars quantifying theme overlap across Reddit, interview, and report sources; most report themes are present in either Reddit or interview data, with additional themes uniquely surfaced by LLM-assisted analysis.
Workflow-generated reports included early-emerging, community-specific concerns missed by traditional survey instruments (e.g., gig economy impacts, freelancing, concrete policy suggestions like UBI, creative professional anxieties), while also uncovering micro-level coping strategies and skepticism/ambivalence about AI adoption.
Implications and Methodological Considerations
The LLM workflow, as instantiated, functions as a complementary analytic instrument rather than a substitute for conventional policy research. Its inductive, quote-driven bottom-up analysis allows for rapid exploration and diverse concern surfacing, scaling far beyond what is practical with manual coding or survey administration.
Practical implications include:
- Scalability: Enables policy researchers to analyze millions of posts/interviews within days, rather than months.
- Cost-effectiveness: Orders of magnitude less expensive for initial scoping and hypothesis generation.
- Precision: Capable of surfacing both general themes and granular, community-specific issues.
- Transparency: Human-in-the-loop design is critical for credibility, provenance, and trust, especially in addressing expert skepticism.
- Generalizability: Modularity permits extension to new LLM frameworks and alternative data sources.
Theoretical implications:
- Methodological expansion: Facilitates the integration of naturally-occurring discourse alongside survey-driven opinion into policy research pipelines.
- Early signal detection: Potential to identify emerging concerns before they are mainstreamed in formal policy analyses.
- Limitations: Challenges remain in demographic representation, trustworthiness of LLM outputs, and loss of nuance relative to human-led interviews.
Future Directions
Unresolved questions include:
- Improving representativeness and metadata granularity, particularly for platforms with demographic skews.
- Enhancing traceability in LLM-generated summaries to build user credibility.
- Comparative evaluation against alternative LLM-driven frameworks and traditional qualitative research methods such as grounded theory or dynamic survey instruments.
- Developing transparent, agency-preserving UI paradigms for non-technical policy practitioners.
Conclusion
This work demonstrates the viability of LLM-assisted thematic analysis as a rapid, scalable, and cost-efficient supplement for early-stage policy sensemaking. Strong theme alignment with authoritative reports, plus the surfacing of novel community-rooted concerns, illustrates practical utility and methodological versatility. However, issues of trust, provenance, and representativeness remain critical for broad adoption. Future efforts should focus on expanding workflow generalizability, improving transparency, and integrating rigorous evaluation standards to optimize AI-assisted tools for policy research applications.

