- The paper introduces RDRO to stabilize density ratios and improve model alignment by replacing unbounded estimates with a bounded, relative formulation.
- RDRO employs a mixing parameter α to blend preferred and non-preferred distributions, ensuring gradient stability and tighter convergence guarantees.
- Empirical evaluations on models like Qwen and Llama show RDRO's superior performance and robustness in handling diverse, unpaired human preference datasets.
Relative Density Ratio Optimization for Stable and Statistically Consistent Model Alignment
Introduction and Motivation
LLM alignment is critical for maintaining safety and reliability as these models are deployed in increasingly sensitive settings. Most current alignment strategies, including RLHF and DPO, rely heavily on strong assumptions about the structure of human preference (e.g., Bradley-Terry or prospect theory models). However, empirical work has shown these models frequently fail to capture real-world, possibly cyclic or intransitive, human preferences, leading to statistical inconsistency: even with infinite data, such methods may not converge to the “true” human preference.
Direct Density Ratio Optimization (DDRO) advances this problem by discarding explicit preference modeling, aligning the model directly with human preferences through density ratio estimation. While DDRO achieves statistical consistency, it suffers substantially from instability—density ratios can diverge if the distributions’ supports do not overlap, causing gradient explosions and unstable optimization. This instability is particularly pronounced where preferred and non-preferred sample distributions differ significantly in real datasets.
This paper introduces Relative Density Ratio Optimization (RDRO), which fundamentally stabilizes DDRO by replacing the standard density ratio with a relative density ratio, ensuring boundedness and thus improved convergence, stability, and statistical guarantees.
Methodological Innovations
Standard Density Ratio Optimization and its Instabilities
DDRO estimates the density ratio g∗(y∣x)=p+(y∣x)p−(y∣x) between non-preferred (p−) and preferred (p+) response distributions, using a reference model as a mixture of the two. The policy pθ(y∣x) is trained via Bregman divergence minimization to match p+, with practical optimization reduced to logistic regression in parameter space. However, as p+(y∣x)→0 (i.e., in low support regions), the density ratio diverges (see below).
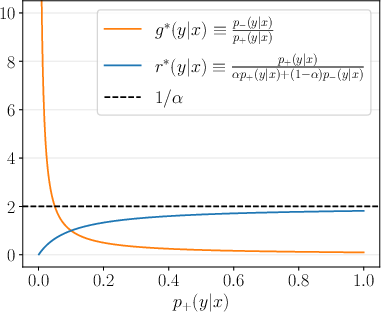
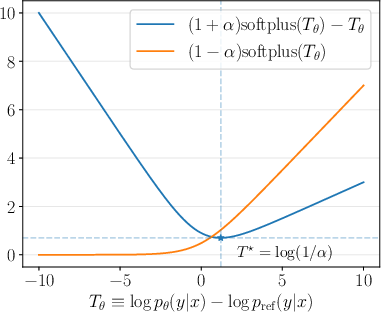
Figure 1: Comparison of the unbounded density ratio g∗ and the bounded relative density ratio r∗ as p+(y∣x)→0, with p−(y∣x)=0.1 and p−0.
This divergence is a primary source of training instability in DDRO, necessitating heuristic regularization or ad-hoc stabilization such as softplus transformations.
Relative Density Ratio Optimization
RDRO addresses this directly by estimating a relative density ratio:
p−1
where p−2 controls the degree of mixing and serves as an explicit regularization parameter. Notably, p−3 is upper-bounded by p−4 by construction, preventing divergence across all support regimes. In practice, RDRO models p−5 and aligns via minimization of the Bregman divergence between p−6 and p−7, formulated as a logistic regression problem with data from both preferred and non-preferred sets.
Synchronization of the RDRO objective with the DDRO stabilization heuristics occurs naturally, with the required softplus/sigmoid transformations emerging directly from the mathematically-grounded relative density ratio formalism.
Theoretical Properties
RDRO provides both rigorous stability and statistical consistency guarantees:
- Boundedness and Gradient Stability: The upper bound on the relative density ratio ensures gradient terms for preferred and non-preferred samples cannot cause divergence, with p−8 acting as an explicit regularizer that can be tuned as a function of class balance.
- Statistical Consistency and Tight Convergence: Theoretical analysis establishes that, under the typical assumption that the true human preference distribution is contained in the hypothesis space, RDRO shows quadratic risk decays as p−9—identical in order to DDRO but with all constant factors strictly tighter (i.e., lower), since pathological terms (e.g., p+0 where p+1 is the minimum probability in preferred support) are eliminated.
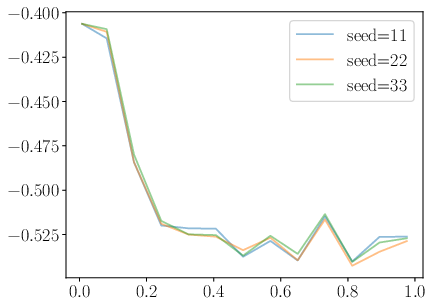
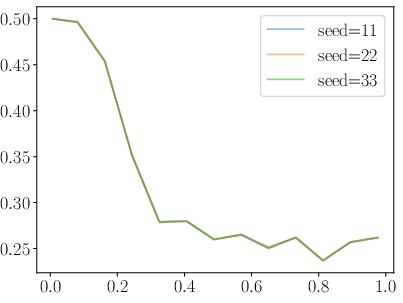
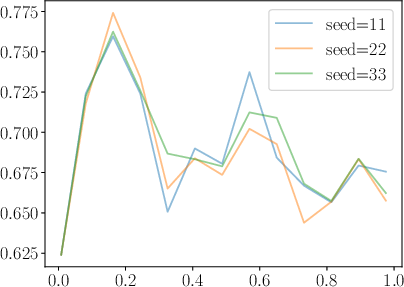
Figure 2: Schematic representation of the DDRO framework and the regions where divergence can occur due to density ratio instability.
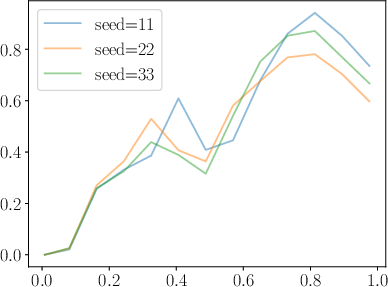
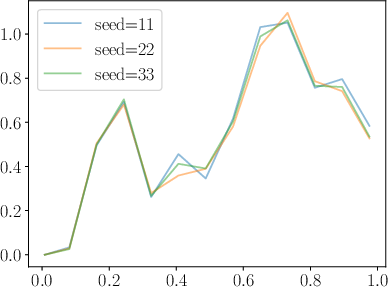
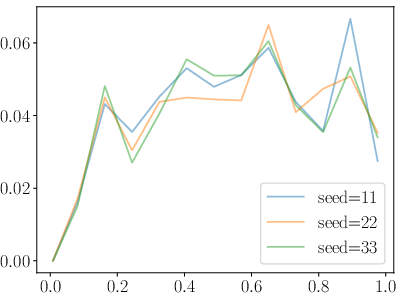
Figure 3: Demonstration of improved training dynamics in RDRO compared to DDRO, as exhibited by gradient norm behavior.
Experimental Evaluation
Extensive empirical validation supports the proposed methodology:
- Datasets & Models: Experiments are conducted using Qwen 2.5 (1.5B, 3B) and Llama 3 (3B, 8B) as base models, with two diverse human preference datasets: UltraFeedback GPT-3.5-Turbo Helpfulness (UF-G) and KTO Mix 14K (MIX-14K).
- Metrics: Evaluation uses AlpacaEval (LC win rate) and chain-of-thought benchmark BIG-Bench Hard (BBH) to quantify both alignment and general reasoning performance.
RDRO consistently matches or exceeds KTO and DDRO across all model/dataset combinations. Particularly on UF-G (which lacks paired preferred/non-preferred responses per prompt), RDRO provides statistically significant improvement over alternatives, reflecting its advantage in more challenging or unpaired preference settings.
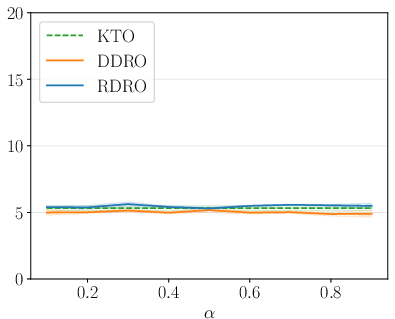
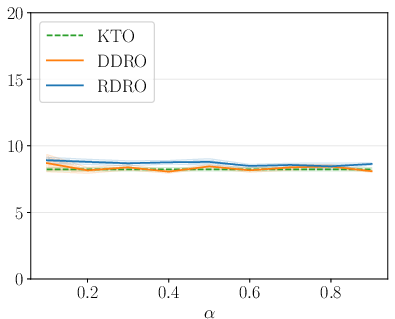
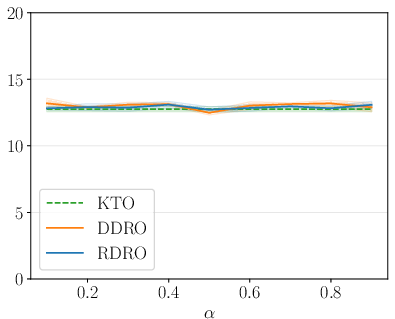
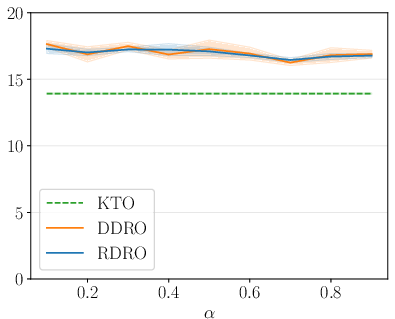
Figure 4: AlpacaEval LC win rates for Qwen-1.5B across alignment methods, showing RDRO superiority.
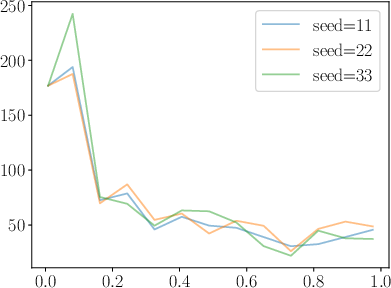
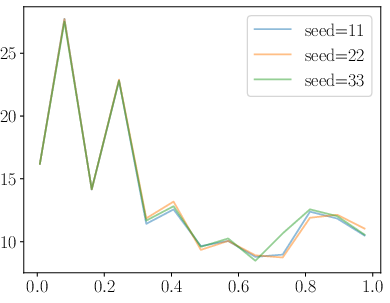
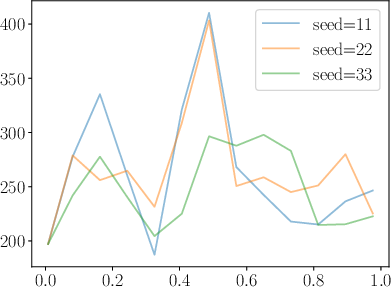
Figure 5: Training stability visualized through loss curves for DDRO, KTO, and RDRO, highlighting the absence of catastrophic spikes in RDRO.
Ablation and sensitivity analyses further confirm the robustness of RDRO to the mixing parameter p+2; optimal results are obtained by simply matching p+3 to the fraction of preferred samples, and performance does not fluctuate strongly as p+4 varies within reasonable bounds.
Implications and Future Directions
The introduction of relative density ratio estimation to alignment circumvents the main instability barrier to density-ratio-based alignment approaches. Empirically, RDRO's consistent superiority on "unpaired" datasets such as UF-G suggests it is inherently suited to scenarios where preferred samples are unavailable for the same prompt as non-preferred ones, a condition common in practice.
On a theoretical level, RDRO establishes a rigorous path for model alignment under arbitrary (even non-transitive) human preferences, with statistical guarantees that are unattainable under standard model-based (e.g., Bradley-Terry) assumptions.
Model robustness to support mismatch and improved generalization rates may also motivate further research into extending RDRO to semi-supervised or positive-unlabeled preference datasets, leveraging methods from PU learning or energy-based estimation for partial information scenarios.
Conclusion
Relative Density Ratio Optimization (RDRO) provides the first alignment method for LLMs that is both stable (in the sense of bounded gradients and objective values) and statistically consistent in the absence of strong human preference model assumptions. The method achieves tighter convergence guarantees than DDRO and shows strong empirical results across multiple challenging alignment scenarios, highlighting its broad promise as a new foundation for preference-based model alignment and future developments in scalable, reliable LLM alignment methodologies.