- The paper introduces NPGC, a non-parametric Gaussian copula method that preserves empirical marginals for synthetic educational data with robust privacy.
- It decouples marginal and dependency modeling using empirical CDF transformations and latent Gaussian projection to prevent distribution drift and model collapse.
- Experimental results show over 95% fidelity across regeneration cycles, competitive utility in classification, and strong privacy guarantees with low computational cost.
Stable and Privacy-Preserving Synthetic Educational Data with Empirical Marginals: A Copula-Based Approach
Introduction
The paper presents the Non-Parametric Gaussian Copula (NPGC), a method for synthetic tabular data generation designed to preserve the empirical marginal distributions and ensure robust privacy guarantees, with a focus on privacy-sensitive educational data. The approach centers marginal fidelity and regeneration stability, establishing strong empirical performance relative to deep learning and parametric copula baselines. The paper further addresses the systematic problems of distribution drift and model collapse in synthetic feedback loops—challenges that are acute in iterative data-centric educational analytics—and investigates practical deployment scenarios.
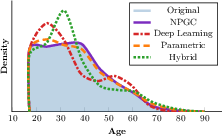
Figure 1: Marginal density of the Age variable in the Adult dataset; NPGC exactly matches the empirical marginal, unlike existing methods which introduce distortions.
Background and Motivation
Educational Data Mining (EDM) and Learning Analytics (LA) require individual-level student data, which is under strict privacy regulation. Even after anonymization, such datasets remain highly sensitive due to potential re-identification attacks. Systematic reviews demonstrate that sharing and reproducibility in EDM are severely hindered by privacy constraints, as most raw datasets are inaccessible for open research. LLM-based educational applications amplify demand for high-quality student data and exacerbate privacy considerations, compelling the adoption of synthetic data generation with formal privacy guarantees.
Existing Synthetic Data Generators for Tabular Data (SDG-T) generally fall into three model families: deep generative models (often GAN or VAE-based), parametric copulas, and hybrids. Deep models optimize joint objectives but lack explicit controls on univariate distributions, often collapsing multimodal marginals or tail behavior (as established in Figure 1). Parametric methods, including classical Gaussian copulas, fit predefined marginal families and thus introduce systematic mismatch for skewed/discrete/value-concentrated educational variables. Hybrid or copula-augmented GANs improve dependency modeling but do not resolve marginal mismatch.
Model collapse and distribution drift are significant concerns under iterative synthetic feedback—the so-called Synthetic Feedback Loop (SFL) or Model Autophagic Disorder—where repeated regeneration leads to compounding errors and loss of distributional support, including biasing underrepresented subgroups. Figure 2 illustrates the progression of variance collapse in a representative deep learning generator.
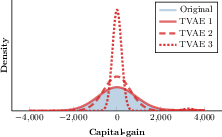
Figure 2: Marginal density of the Capital-gain variable in the Adult dataset across recursive regeneration iterations—variance collapse is evident in deep models.
Non-Parametric Gaussian Copula (NPGC) Method
NPGC decouples marginal and dependency modeling following Sklar’s theorem. The key innovation is replacing parametric or learned marginal models with empirical anchors, obtained via nonparametric estimation. The method consists of three primary stages:
- Marginal Transformation: Each variable is re-mapped to the unit interval using its empirical CDF, with missingness encoded explicitly. Differential privacy is enforced through Laplace noise injection on the empirical distributions.
- Latent Gaussian Dependency Modeling: The data is projected into a latent Gaussian space. Correlations are estimated with noise injected for privacy, followed by positive semi-definite (PSD) correction, and used to parameterize a Gaussian copula.
- Marginal Reconstruction: Synthetic samples are generated by sampling from the Gaussian copula and then mapping back through the privatized empirical CDFs, yielding data in the original feature space.
This process ensures both exact (modulo privacy noise) preservation of observed marginal distributions and robust modeling of linear dependencies, as visualized in Figure 3.
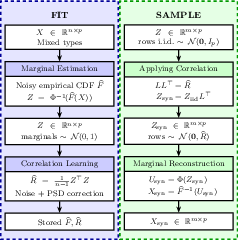
Figure 3: Overview of NPGC fit and sample workflow—empirical marginals and latent Gaussian dependencies are disentangled and privatized.
The procedure natively supports a mix of continuous, categorical, and integer variables, preserving missingness patterns as informative features. No neural network optimization or parametric density estimation is involved, resulting in a lightweight, computationally efficient workflow.
Experimental Evaluation
Marginal Fidelity
NPGC is evaluated on five benchmark datasets, including education-focused datasets (Student Dropout, Student Performance) and the widely used Adult dataset. Marginal fidelity is consistently maintained: as shown in Figure 4, NPGC reproduces non-standard shapes (multi-modality, heavy skew, or value clustering) in marginals, in contrast to baseline approaches which collapse or smooth over critical distributional structure.
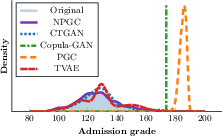
Figure 4: Marginal density of the Admission grade variable in the Student Dropout Success dataset, demonstrating NPGC’s empirical preservation under complex marginals.
Regeneration Stability
Iterative regeneration tests reveal that NPGC uniquely sustains marginal and bivariate distributional support under repeated synthetic feedback. For variables commonly subject to mode collapse, NPGC remains robust (Figure 5).
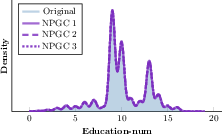
Figure 5: The Education-num variable in Adult maintains empirical marginal structure across three NPGC regeneration iterations; mode collapse is absent.
At the aggregate level, NPGC’s overall distributional fidelity remains above 95% across ten regeneration cycles, whereas all competing methods degrade catastrophically, losing support for rare/modality-spanning variables (Figure 6).
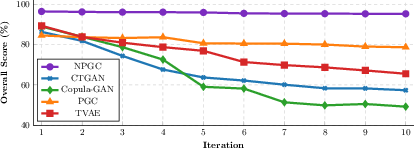
Figure 6: Overall Score (%) across ten regeneration cycles; NPGC demonstrates minimal degradation, outperforming all compared models in stability.
Privacy and Utility
NPGC integrates differential privacy at both marginal and dependency estimation levels, achieving lower Discriminator AUC and Distance to Closest Record (DCR) Share metrics than all baselines. This represents both strong resistance to record linkage attacks and lower memorization risk. In utility benchmarking (TSTR protocol with XGBoost), NPGC reaches competitive classification performance—16.99% accuracy drop, trailing only TVAE (8.66%) but with much higher fidelity and far stronger privacy. The computational cost is orders of magnitude lower, with NPGC model fitting in under 1 second on all datasets.
Real-World Deployment and Class Imbalance
A deployment on a large-scale educational platform’s xAPI logs demonstrates the practical impact of empirical marginal anchoring. The dataset exhibits extreme class imbalance: the minority “Hint” category appears in less than 0.2% of records. NPGC-generated synthetic data preserves category proportions exactly, including underrepresented classes, as shown in Figure 7.
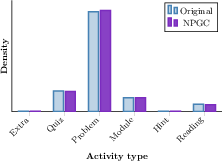
Figure 7: NPGC maintains true empirical activity-type proportions, including severe rare-class representation, in real and synthetic educational logs.
This property is critical for reliability in fairness or subgroup analysis, and cannot be matched by deep or parametric synthesizers, which consistently under-represent or smooth tail classes.
Implications, Limitations, and Future Directions
NPGC delivers strong practical and theoretical benefits for privacy-sensitive synthetic data generation:
- Marginal fidelity prevents undesirable attenuation of rare subgroups and enables structurally honest synthetic datasets, essential for reproducibility, benchmarking, and fairness analysis in EDM.
- Regeneration stability makes NPGC suitable for workflows dependent on iterative synthetic data (e.g., augmentation, distillation, progressive model retraining).
- Privacy integration allows compliance with strict regulatory frameworks without sacrificing statistical fidelity.
Limitations involve reliance on Gaussian copula dependency structure, which may not fully capture highly nonlinear interactions or complex conditional relationships, although this is less problematic for tasks centered on univariate or groupwise analysis. For settings requiring richer dependency modeling (such as longitudinal/panel or relational data), extensions to vine copulas or neural flows with empirical marginals are proposed.
Conclusion
NPGC establishes empirical marginal preservation and regeneration stability as primary desiderata for synthetic tabular data generation in privacy-constrained educational analyses. The method challenges the dominance of deep and parametric generators by demonstrating that nonparametric, privacy-preserving, and computationally efficient synthesizers can outperform in fidelity and stability while maintaining competitive utility. Future advances should focus on extending the framework to relational schemas and richer dependency models, enabling broader applicability to contemporary AI-driven educational research.