- The paper introduces a modular ensemble strategy that decomposes networks into sub-modules, achieving exponential diversity with only linear overhead.
- The paper employs a frozen pretrained teacher for guided mutual learning, which stabilizes training and aligns diverse representations using contrastive objectives.
- The paper demonstrates up to 9.70% higher NDCG@20 and 7.69× faster convergence than baselines, while maintaining single-model inference efficiency.
FLAME: A Modular Ensemble Framework for Efficient and Stable Sequential Recommendation
Motivation and Problem Statement
Sequential recommendation systems must capture the heterogeneous and context-sensitive behavioral patterns inherent in user–item interaction data. Deep ensemble strategies, which aggregate the output of multiple models to enhance prediction accuracy and generalization, have previously shown superiority in uncovering user intent diversity. However, conventional ensembles incur prohibitive costs in both training and inference due to redundant duplication of model parameters and repeated computation, while also suffering instability due to noisy mutual knowledge transfer among randomly initialized networks.
Modular Ensemble Design
FLAME introduces a modular ensemble paradigm to address computational inefficiency and instability. Instead of instantiating N complete networks and ensembling their outputs, FLAME decomposes each network into M sub-modules (e.g., embedding layers, Transformer blocks) and dynamically assembles modular paths by combining sub-modules from either a learnable or a frozen network at each stage. This mechanism exponentially increases the diversity of latent representations with only linear overhead: with N networks and M modules, NM distinct computation paths are generated, compared to N in classical ensembles.
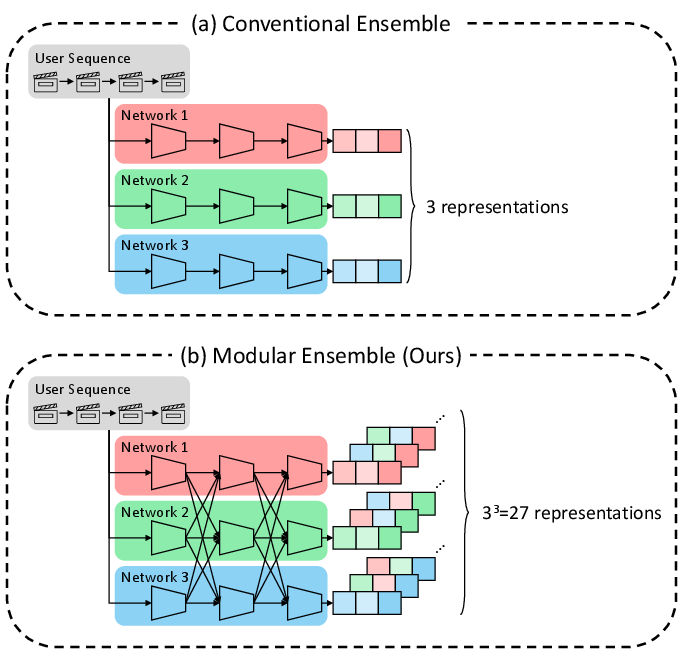
Figure 1: The modular ensemble exponentially increases representational diversity by dynamically combining sub-modules from two networks.
In practice, FLAME uses N=2 networks (one learnable, one frozen) and, by default, M=2 sub-modules (embedding and encoding), resulting in four unique representations per user sequence. More fine-grained decomposition (e.g., per-layer) can further increase diversity, but with diminishing returns due to optimization complexity.
Guided Mutual Learning with a Frozen Semantic Anchor
To mitigate training instability, FLAME employs a frozen, pretrained network as a semantic anchor for guided mutual learning. The learnable network is trained from scratch under the influence of this frozen teacher, which provides stable knowledge and encourages the learnable sub-modules to map latent features into a reliable and well-shaped representation space. All possible modular paths (except the fully frozen path, which provides the anchor) are aligned into a unified semantic space using contrastive objectives, specifically, pairwise noise-contrastive estimation (NCE), where representations from the same user but different paths act as positive pairs.
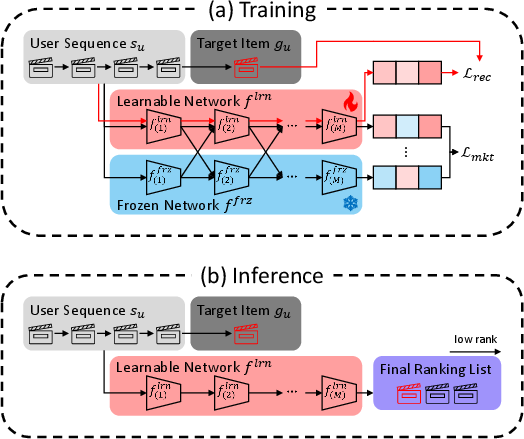
Figure 2: Training and inference procedures in FLAME. During training, diverse paths are generated by combining frozen and learnable modules; only the learnable network is used at inference.
To further regularize this process, FLAME introduces:
- Similarity-based pair weighting: The contrastive loss between structurally similar pairs (which share more sub-modules) is down-weighted, focusing the optimization on pairs with the greatest diversity.
- Coefficient annealing: The weight of the mutual knowledge transfer objective decays over training. This prevents over-regularization and allows the learnable network to eventually emphasize intrinsic task-specific signals.
Inference-Time Efficiency
A defining feature of FLAME is its deployment efficiency. Because the modular alignment process ensures the learnable network's representations capture the ensemble's diversity, only this network is retained at inference—yielding computational costs identical to the base model, with no runtime aggregation across ensemble members. This sharply contrasts with standard ensembles, where inference scales linearly with the number of participating networks.
Empirical Evaluation
FLAME is evaluated on six large-scale datasets, spanning diverse domains and levels of sparsity, against both single-model, contrastive-learning, and ensemble-based sequential recommenders. Across all experiments, FLAME demonstrates consistent improvements over strong baselines.
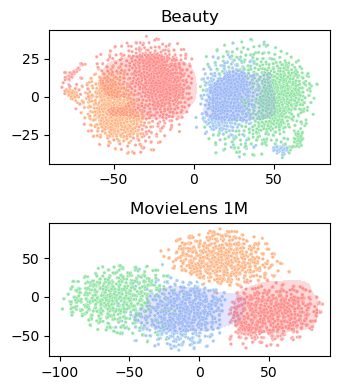
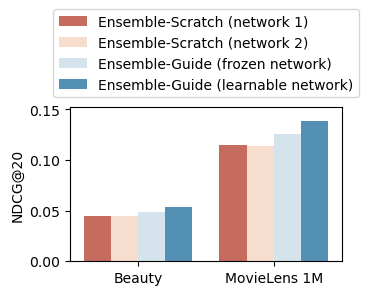
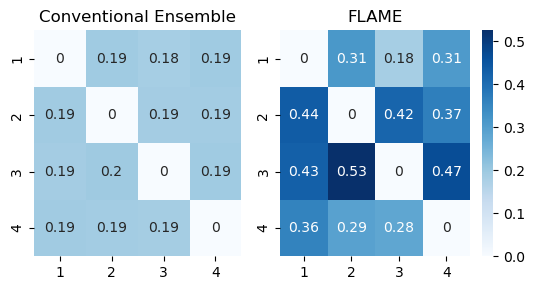
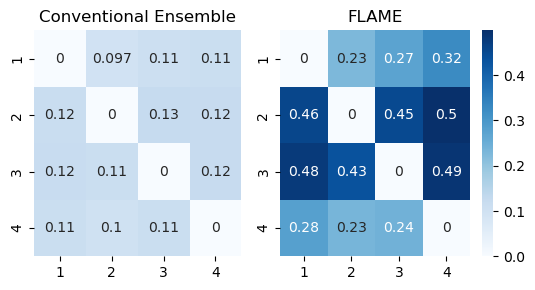
Figure 3: t-SNE visualization illustrates that the modular ensemble yields a richer and more distributed set of representations compared to standard ensemble methods.
Notable empirical findings include:
- Superior accuracy: FLAME delivers up to 9.70% higher NDCG@20 compared to the best-performing baseline (FamouSRec, DHEN, EMKD), and up to 7.69× faster convergence.
- Training stability: Guided mutual learning via a frozen teacher leads to faster and more stable optimization, abating the optimization pathologies seen in classical ensembles (e.g., persistent under-performance and high variance).
- Efficiency: At inference, FLAME's computational cost is identical to a single SASRec; ensemble baselines incur 4–7× higher latency or parameter count for comparable accuracy.
Robustness and Ablations
Ablation studies confirm the critical importance of both modular decomposition and the presence of a frozen teacher, each yielding significant drops in performance when omitted. FLAME remains robust to architectural choices in the frozen network (achieving improvements with RNN, MLP, CNN, and Transformer teachers), and is relatively insensitive to the sub-module granularity and moderate variations in contrastive loss hyperparameters.
Scalability and Diminishing Returns
Analysis of finer-grained modular decomposition reveals that while additional sub-modules can bring further performance improvements, gains become marginal beyond M=4 due to increased coordination and alignment complexity. This highlights a practical regime for FLAME: two to four sub-modules suffices for a strong efficiency/effectiveness trade-off.
Theoretical and Practical Implications
FLAME’s exponential representation generation through modularity establishes that ensemble-level diversity is attainable in a single-parameter-trajectory network given careful structural architectural design and stable targets. This contradicts the canonical view that diversity requires independent training of multiple networks. From a practical standpoint, FLAME enables deployment of highly expressive recommenders with real-time inference speeds suitable for latency-critical applications—a substantial benefit over traditional ensembles.
Future Directions
Subsequent work may leverage FLAME’s combinatorial path structure for dynamic inference, activating only additional paths on high-uncertainty samples or for specific user cohorts. Moreover, theoretical understanding of modular path diversity and its expressivity relative to the full hypothesis space in sequential learning is an open avenue.
Conclusion
FLAME delivers an effective condensation of deep ensemble diversity into a single network via modular decomposition and guided contrastive alignment, producing robust accuracy gains, dramatically improved computational efficiency, and stable training dynamics. It redefines the landscape of ensemble strategies for sequential recommendation, demonstrating that both diversity and deployment efficiency can be simultaneously achieved through architectural and optimization design.
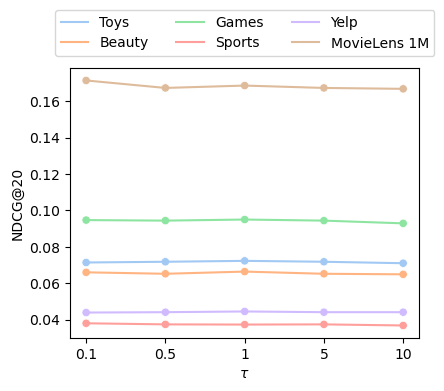
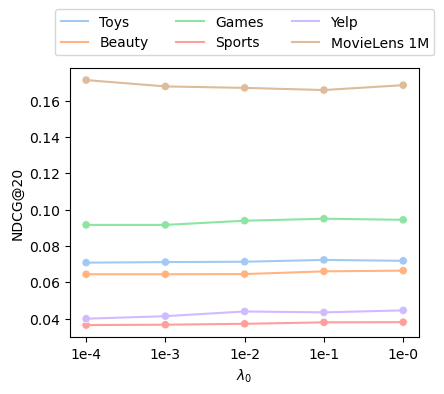
Figure 4: FLAME shows limited performance sensitivity to the temperature (τ) and initial coefficient (M0) of the contrastive objective, confirming training robustness.

