- The paper introduces Jellyfish, a framework that achieves zero-shot unlearning by replacing sensitive data with optimized proxy noise and disentangling class features.
- It employs a multi-objective loss and gradient harmonization to balance aggressive forgetting of target data while maintaining high performance on retained classes.
- Empirical results demonstrate complete target class erasure and minimal collateral accuracy loss, matching retrain-from-scratch baselines and enhancing privacy.
Zero-Shot Federated Unlearning with Knowledge Disentanglement: The Jellyfish Framework
Context and Motivation
Federated learning (FL) facilitates collaborative training across a distributed population while retaining data locality, satisfying critical privacy and regulatory requirements. However, robust support for post hoc data deletion and the “right to be forgotten” remains an unsolved challenge under FL. Model updates encode private information, and their aggregation may leak sensitive user contributions, even after raw data deletion. This concern is amplified by data protection regulations (e.g., GDPR, CCPA) that require that machine learning models not retain or disclose information about deleted records.
Classical approaches—full retraining after record removal or approximated post hoc parameter adjustment—are insufficiently efficient or privacy-preserving in FL due to high communication and compute costs or direct dependence on sensitive user data. The Jellyfish scheme (2604.04030) makes several explicit advances: it achieves data deletion in FL without direct access to the data to be forgotten (zero-shot deletion), utilizes structured proxy noise rather than original samples, explicitly disentangles entangled class features to minimize performance degradation on retained data, and employs repair mechanisms to restore model utility post-unlearning.
Knowledge Disentanglement: Design and Impact
Knowledge entanglement—in which features for distinct classes are intermixed within the feature space—poses a direct impediment to effective targeted unlearning. Removal of one class can degrade decision boundaries for others, causing over-forgetfulness and impairing FL model utility. Jellyfish addresses this using explicit feature disentanglement: sparsification and targeted regularization of the last convolutional layer restrict the influence of forgotten data to a reduced subset of feature channels. The mechanism calculates L1 norms for all channels post-convolution and retains only the top α fraction for each class selected for unlearning, suppressing the rest.
Figure 1: Knowledge disentanglement suppresses inter-class activation mixing, localizing features for each class and supporting class-specific unlearning.
Empirically, this reduces performance drop on non-target data during unlearning and increases interpretability of model representations. As shown in (Figure 2), accuracy of non-target classes is substantially stabilized post-disentanglement, mitigating collateral performance loss relative to baselines without disentanglement.
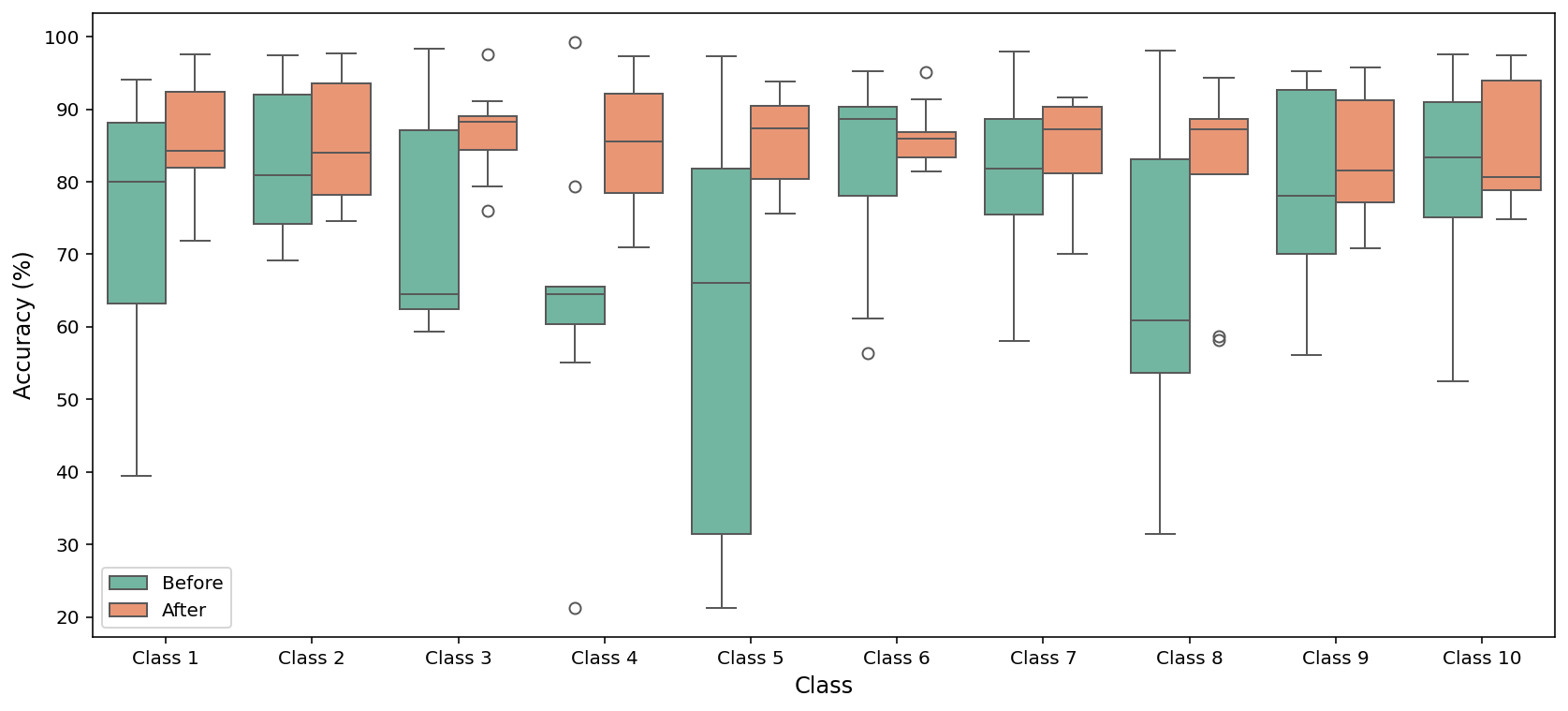
Figure 2: Disentangling knowledge across categories narrows the spread and lifts the medians of non-target category accuracy after targeted unlearning.
Zero-Shot Proxy Data via Error-Minimization Noise
Central to the zero-shot guarantee in Jellyfish is the replacement of sensitive original data Df and Dr with error-minimization noise matrices Nf and Nr. Proxy data is optimized locally by minimizing the predictive cross-entropy between model outputs on noise and the target class, converging to inputs recognized by the model as the target class but bearing no resemblance to the actual data. These noise proxies, distributed by the user to the central server, support unlearning and optional repair without disclosing any raw data characteristics.
The generation and aggregation of Nf is agnostic to data origin and supports multi-client federated aggregation. Statistically, proxy data maintains gradient alignment with genuine data classes sufficient to enable effective unlearning while avoiding privacy leakage.
Multi-Objective Loss Design and Gradient Coordination
Jellyfish addresses the intrinsic conflict between forgetting (maximally damaging model performance on the “forgotten” class) and retaining (preserving accuracy on all others) through a multi-component loss:
- Hard Loss: Maximizes loss on the original label of forgotten data (cross-entropy between model output and the true forgotten label).
- Confusion Loss: Shifts predictions for forgotten class to the most semantically similar remaining class, promoting controlled confusion rather than randomization.
- Distillation Loss: Employs an incompetent teacher model that lacks knowledge of the forgotten class; the primary model matches its predictive distribution, introducing stochasticity and further weakening class-specific memorization.
- Model Weight Drift Loss: Explicitly penalizes parameter deviation from pre-unlearning weights, reducing catastrophic utility loss on retained classes.
- Gradient Harmonization and Masking: Gradient directions for “forgetting” and “remembering” are projected to eliminate destructive conflict, and drift gradients are masked to remove components associated with forgotten classes.
This unified loss explicitly aligns gradient flow for both objectives. The critical necessity of harmonization and masking is supported by ablation: removal of gradient masking, hard loss, or harmonization results in a severe drop in forgetting efficacy or utility retention.
End-to-End Pipeline and Zero-Shot Repair
A user-initiated deletion request triggers proxy generation for Df and proceeds through disentanglement, unlearning, and optional repair (Figure 3). The server orchestrates knowledge disentanglement prior to forgetting; if utility loss exceeds threshold, clients may reinitiate repair via Nr. All communication is purely in noise and model weights.
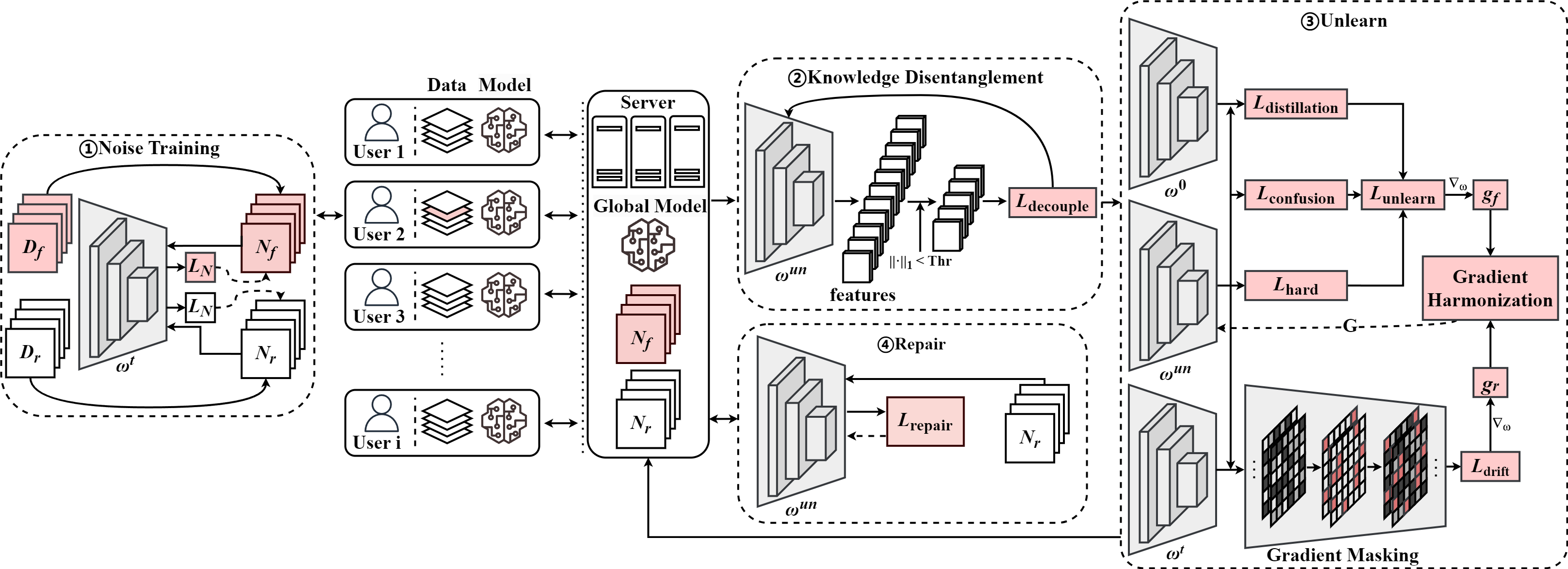
Figure 3: The Jellyfish pipeline: proxy training, knowledge disentanglement, unlearning, and optional repair.
The zero-shot repair mechanism restores accuracy using proxy data for non-forgotten classes. Once accuracy drop is detected, users submit Nr, which the server aggregates and uses to fine-tune the model toward pre-unlearning performance levels without encountering actual data.
Experimental Validation
Jellyfish is evaluated on MNIST, CIFAR-10, and CIFAR-100, using federated and centralized baselines encompassing retraining, negative gradient fine-tuning, saliency-based unlearning, and “bad” teacher distillation. All test set evaluations enforce the zero-shot principle: only proxy data is utilized after model initialization.
For one-class forgetting on CIFAR-10:
- Accuracy on unlearned data (Df) drops to 0.00% (fully erased), matching retrain-from-scratch and outperforming saliency-based and confusion-based baselines.
- Accuracy on retained data (Df0) is maintained at 87.23% (single class) and 87.39% (20% classes), nearly matching the original model and notably exceeding classic negative-gradient and random-label approaches.
- Membership inference attack success on forgotten data drops from >97% to ~53%, approaching random guess rates and equivalence with retrain-from-scratch, confirming strong privacy restoration.
- Computational cost: Execution time and batch cost are significantly reduced compared to full model retraining, with only minor overhead from proxy generation and disentanglement.
Proxy data performance tracks real-data unlearning with insignificant gap (Figure 4), empirically supporting the efficiency and validity of the zero-shot protocol.
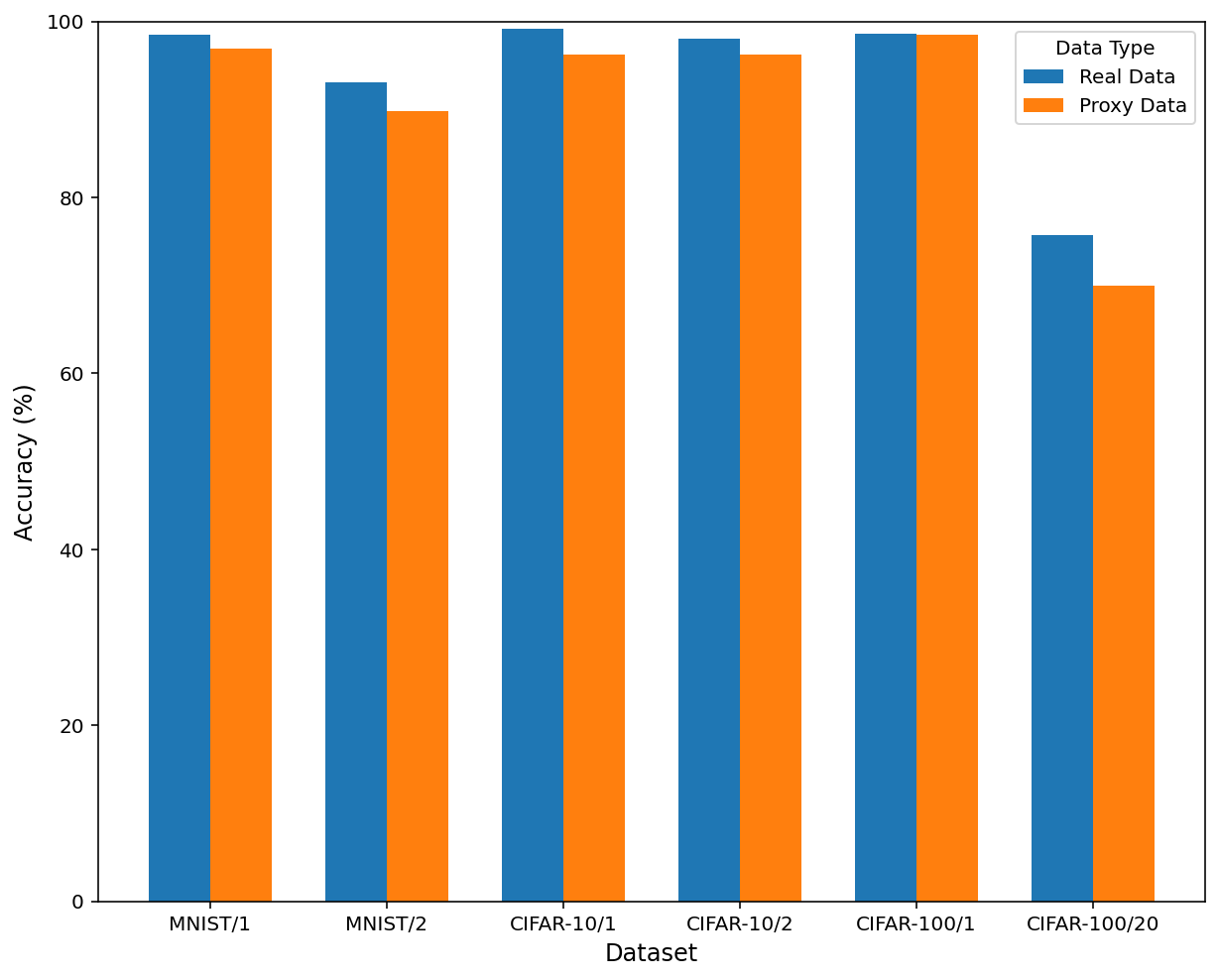
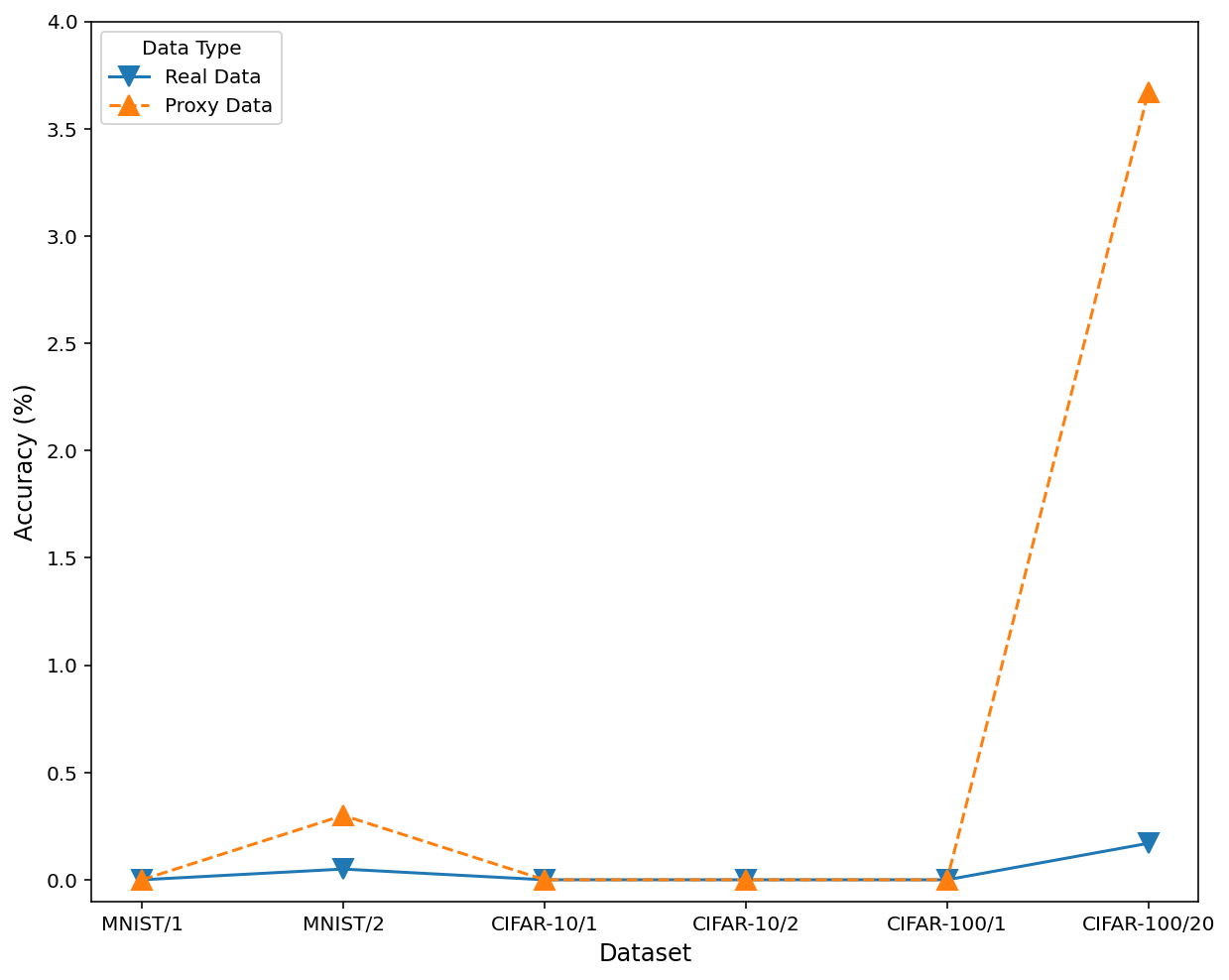
Figure 4: Performance parity between unlearning with true data and zero-shot proxy data for both forgotten and retained accuracy.
Similarity to retrain-from-scratch models is directly measured via Jensen-Shannon divergence, L2, and T-test (Figure 5). Jellyfish consistently achieves the lowest divergence from the gold standard, demonstrating superior fidelity among zero-shot and federated methods.
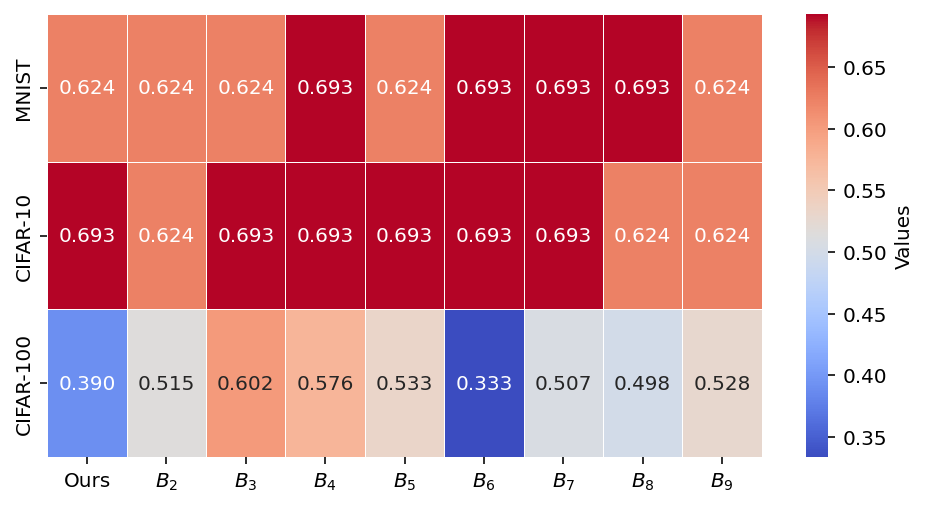
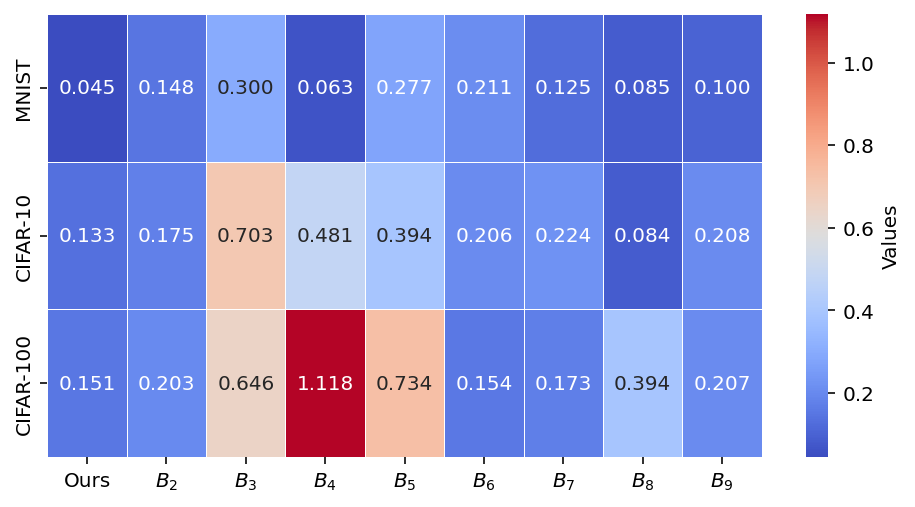
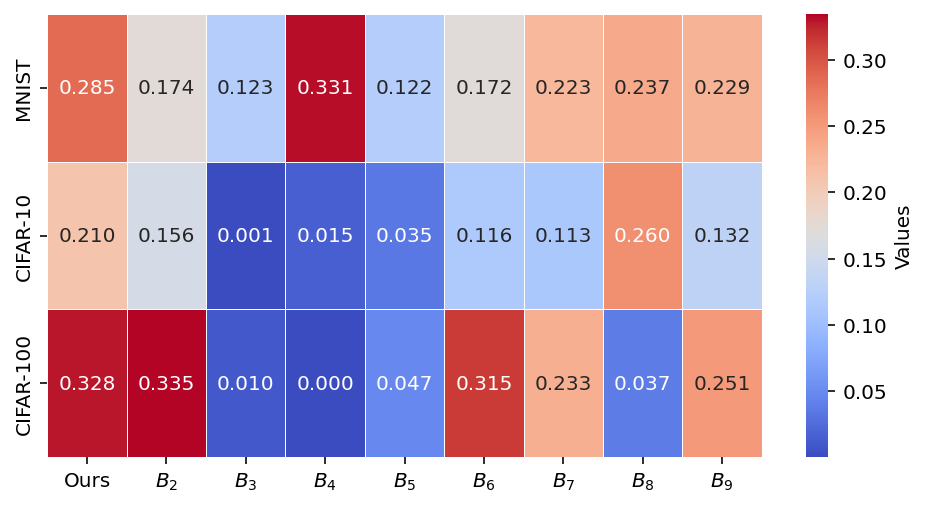
Figure 5: Unlearning performance on the test set—Jellyfish minimizes divergence (JSD, L2) to the retrained model and achieves lower p-values, evidencing nontrivial differences from the original model.
Theoretical and Practical Implications
Jellyfish advances federated unlearning both by achieving effective zero-shot deletion without privacy-compromising data disclosures and by systematically mitigating the utility-vs-forgetting trade-off via disentanglement and gradient-level coordination. Strong empirical results—especially full eradication of target class accuracy (0.00%) paired with minimal retained accuracy loss—set a new baseline for zero-shot FL unlearning.
Mechanisms for proxy repair expand the practical viability of FL in regulated settings, reducing retraining burden and ensuring fidelity to post-deletion performance. The disentanglement strategies provide a compelling blueprint for future FL deletion frameworks: explicit structural regularization at the feature level is necessary to avoid information leakage and over-forgetfulness.
Prospects and Future Directions
The architectural paradigm introduced by Jellyfish—separation of entangled knowledge, enforceable proxy-driven optimization, and gradient harmony—is applicable beyond vision tasks to more general deep multimodal and LLMs subject to deletion requests. Upcoming research should address proxy synthesis for structured or sequential data, robustness to model and data heterogeneity, and scalable aggregation under non-IID client populations.
Furthermore, current privacy verifications rely on membership inference; comprehensive formal guarantees (e.g., leveraging DP, auditability [see (Chen et al., 2024, Yao et al., 2024)]) should be integrated. The knowledge disentanglement by feature channel sparsification invites cross-pollination with pruning and explainability research.
Conclusion
Jellyfish demonstrates precise, efficient federated data unlearning in a strictly zero-shot setting, leveraging feature disentanglement, proxy-based optimization, and multi-objective gradient coordination. Empirically, complete unlearning of target classes is achieved with minimal collateral utility loss and strong computational efficiency, substantiated by direct comparison to retrain-from-scratch and prevailing federated unlearning baselines. The approach provides a substantial contribution to privacy-preserving FL, aligning technical capability with regulatory requirements and robustly enabling the right to be forgotten in practical deployments (2604.04030).