- The paper introduces ACES, which uses a leave-one-out strategy to compute AUC scores that distinguish informative tests from misleading ones in code generation evaluation.
- It presents two algorithms—ACES-C with a closed-form solution and ACES-O using gradient ascent—to weight tests based on their discriminative power.
- Empirical results demonstrate that ACES achieves high Pass@1 scores on benchmarks like HumanEval, HumanEval+, and MBPP, effectively enhancing code selection performance.
ACES: Leave-One-Out AUC Consistency for Test Quality Assessment in Code Generation
The ACES framework is motivated by the challenge of post-hoc code selection for LLM-generated code using LLM-generated tests, where both code and test correctness are unknown and highly variable. The canonical approach aggregates test results in a binary pass matrix B∈{0,1}n×m with n candidate codes and m tests. The central technical obstacle is the circular dependency: reliable tests are needed to determine code correctness, but reliable codes are necessary to appraise test quality.
Existing approaches, such as majority voting and consensus-set scoring (e.g., CodeT), treat all tests equally or apply heuristic filtering; other methods (e.g., MBR-exec, SRank) require expensive pairwise output analysis. No prior execution-only post-hoc method provides formal guarantees for reliable test identification from the pass matrix alone.
LOO-AUC: Theory and Discriminative Power
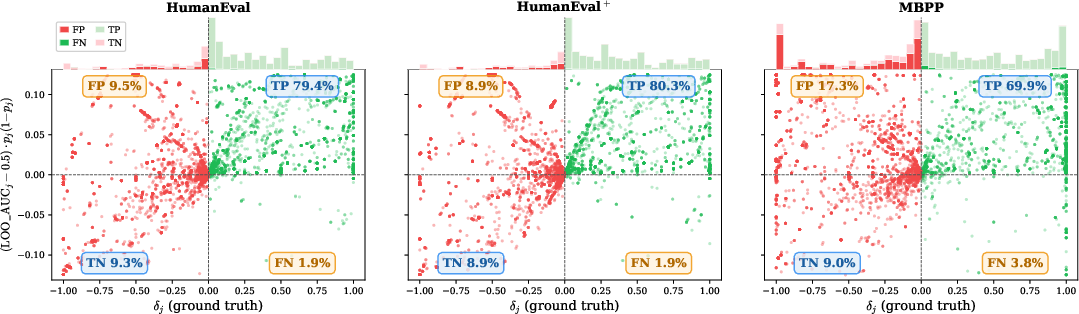
The principal insight of ACES is that for the purpose of ranking, a test's value lies not in its ground-truth correctness but in its discriminative power: the ability to separate correct codes from incorrect codes. The taxonomy of tests based on their class-conditional pass rates (αj, βj) and discriminative power (δj=αj−βj) is depicted below.
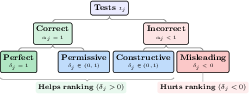
Figure 1: For ranking, only δj matters. Taxonomy of tests by correctness αj and discriminative power δj.
Rather than attempting to estimate the absolute correctness of each test, ACES breaks the evaluation circularity via a leave-one-out (LOO) approach: for each test tj, codes are ranked using the votes from the remaining tests; the degree to which n0's outcomes agree with this ranking is measured via the AUC between the held-out test's column and the aggregate code ranking ("LOO-AUC").
Formally, define the LOO-AUC for test n1 as n2, where n3 is the leave-n4-out code score vector. Theoretical analysis (Theorem 1 in the paper) shows the expected LOO-AUC is proportional to the unknown ground-truth discriminative power of n5 (n6), where the coefficient is a function of marginal pass rates and task difficulty. This result, the LOO-AUC Identity, is the first provable criterion for identifying both informative and misleading tests directly from the binary pass matrix.
ACES introduces two algorithms operating exclusively on the binary execution matrix:
- ACES-C (Closed-form): Test weights are proportional to the pass-rate-corrected LOO-AUC excess (n7). This weighting is provably near-oracle optimal under weak conditions on the average test quality, assigning zero weight to misleading tests. ACES-C involves no hyperparameters and negligible additional cost over the majority voting baseline.
- ACES-O (Optimized): Instead of relying on the average-quality assumption, ACES-O directly maximizes a differentiable surrogate of the sum of weighted LOO-AUCs via gradient ascent. This iterative method is robust to the presence of a large fraction of misleading tests and adapts the weights jointly, recovering informative tests that ACES-C may underweight in adversarial regimes.
The complementarity of the two methods arises from their operating regimes: ACES-C is highly effective when the average test discriminative power is bounded away from zero (the typical case in practical code generation test sets), while ACES-O excels when this assumption is violated.
Empirical Evaluation
ACES is evaluated on HumanEval, HumanEvaln8, and MBPP, using GPT-3.5-Turbo-generated codes and tests, compared against established reranking methods and recent execution-based and static analysis baselines. On all benchmarks, ACES-O achieves the highest Pass@k among execution-only methods and is competitive or superior to methods exploiting static analysis or LLM-based "verifiers".
Notably, ACES achieves:
- HumanEval: 84.15% Pass@1 (ACES-O), +15.8 over GPT-3.5-Turbo zero-shot
- HumanEvaln9: 74.39% Pass@1 (ACES-O), outperforming execution-based and most hybrid methods
- MBPP: 72.37% Pass@1 (ACES-O), consistent with HumanEval, though static analysis still provides an orthogonal boost
When combined in an ensemble with static-analysis-based signals (e.g., DS3), ACES further improves absolute Pass@1 on all datasets, confirming the orthogonality and practical salience of its execution-derived test quality weights.
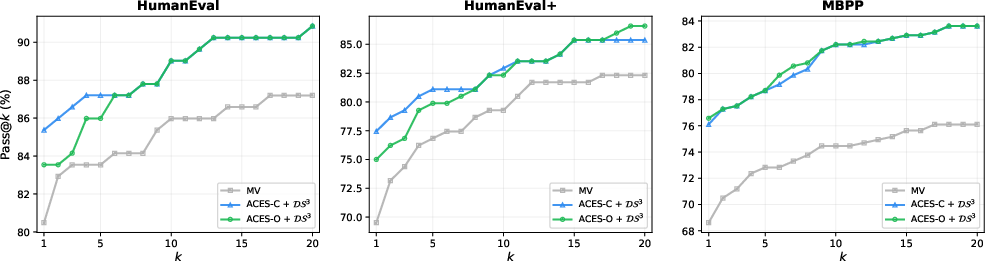
Figure 3: Pass@k versus m0 on all three benchmarks; ACES, combined with static analysis pre-filtering, yields the best results, especially at low m1 where ranking quality is paramount.
Robustness, Test Quality Detection, and Analysis
Detailed ablations reveal:
Implications and Future Directions
The ACES framework demonstrates that leave-one-out (internal) consistency is a theoretically sound and practically effective criterion for distilling discriminative signal from a pool of noisy, machine-generated tests, without access to ground-truth labels or expensive external verifier models. This principle should readily transfer to other contexts featuring noisy evaluators, such as crowdsourced labeling or LLM-as-judge ensembles, and suggests new directions for stable online test set curation, active test generation, and LLM evaluation design.
Moreover, the explicit decomposition of test quality into discriminative power offers a foundation for future adaptive test generation, dynamic test selection, and more robust model-based evaluation pipelines, particularly as code LLMs generate increasingly diverse and non-i.i.d. outputs.
Conclusion
ACES (AUC Consistency Scoring) establishes the first provable, execution-only framework for identifying both informative and misleading tests for code generation solely from binary evaluation outcomes. The LOO-AUC identity enables robust, theoretically justified test weighting that translates to strong practical code selection performance, scalable computation, and seamless integration with orthogonal selection signals. The ACES methodology opens a class of principled meta-evaluation approaches for noisy-response verification and selection in program synthesis and beyond.