- The paper demonstrates that patterns of AI agent disagreement can proxy human cognitive pluralism in moderation decisions.
- It employs a structural taxonomy (CA, DA, CD, DD) based on reasoning similarities and verdicts to guide human escalation.
- Experimental results show improved F1 scores and interpretability over divergence-only methods in contested cases.
Reasoning Trace Analysis for Human-AI Collaborative Moderation
Problem Context and Motivation
Automated content moderation faces foundational challenges rooted in value pluralism and subjective interpretation, particularly in domains like hate speech where cultural context and individual value weightings drive legitimate disagreement among human annotators. Existing multi-agent LLM moderation architectures widely apply consensus-seeking mechanisms—weighted voting, Byzantine fault tolerance, agent filtering—positioning inter-agent disagreement as noise to be engineered away. However, such approaches discard the signal hidden in disagreement itself, failing to recognize cases where contested semantic regions reflect genuine value tensions also present among human reasoners.
The explored hypothesis is that patterns of disagreement arising from perspective-differentiated AI agents can proxy human cognitive pluralism. Specifically, convergent disagreement—where agents reason in similar semantic spaces but reach diverging judgments—is indicative of value conflict rather than error, paralleling legitimate human disagreement.
Framework and Methodology
The presented framework instantiates five DeepSeek-V3 agents differentiated via system prompts, each encoding a distinct moderation perspective: harm prevention, contextual interpretation, community norms, free expression, and legal standards. These agents generate explicit reasoning traces for each content decision—REMOVE or KEEP—with accompanying confidence scores and articulated value priorities.
Reasoning traces are embedded using all-mpnet-base-v2 sentence embeddings, enabling quantitative cosine similarity comparisons across agent outputs. This semantic embedding supports structural trace analysis. The core taxonomy distinguishes content items along two axes: reasoning similarity and conclusion agreement, yielding four mutually exclusive categories:
- Convergent Agreement (CA): High similarity, same verdict
- Divergent Agreement (DA): Low similarity, same verdict
- Convergent Disagreement (CD): High similarity, conflicting verdicts
- Divergent Disagreement (DD): Low similarity, conflicting verdicts
This taxonomy allows routing cases to either automated resolution or human escalation based not just on divergence magnitude, but on the structural patterns of agent discord. The system design is presented below.
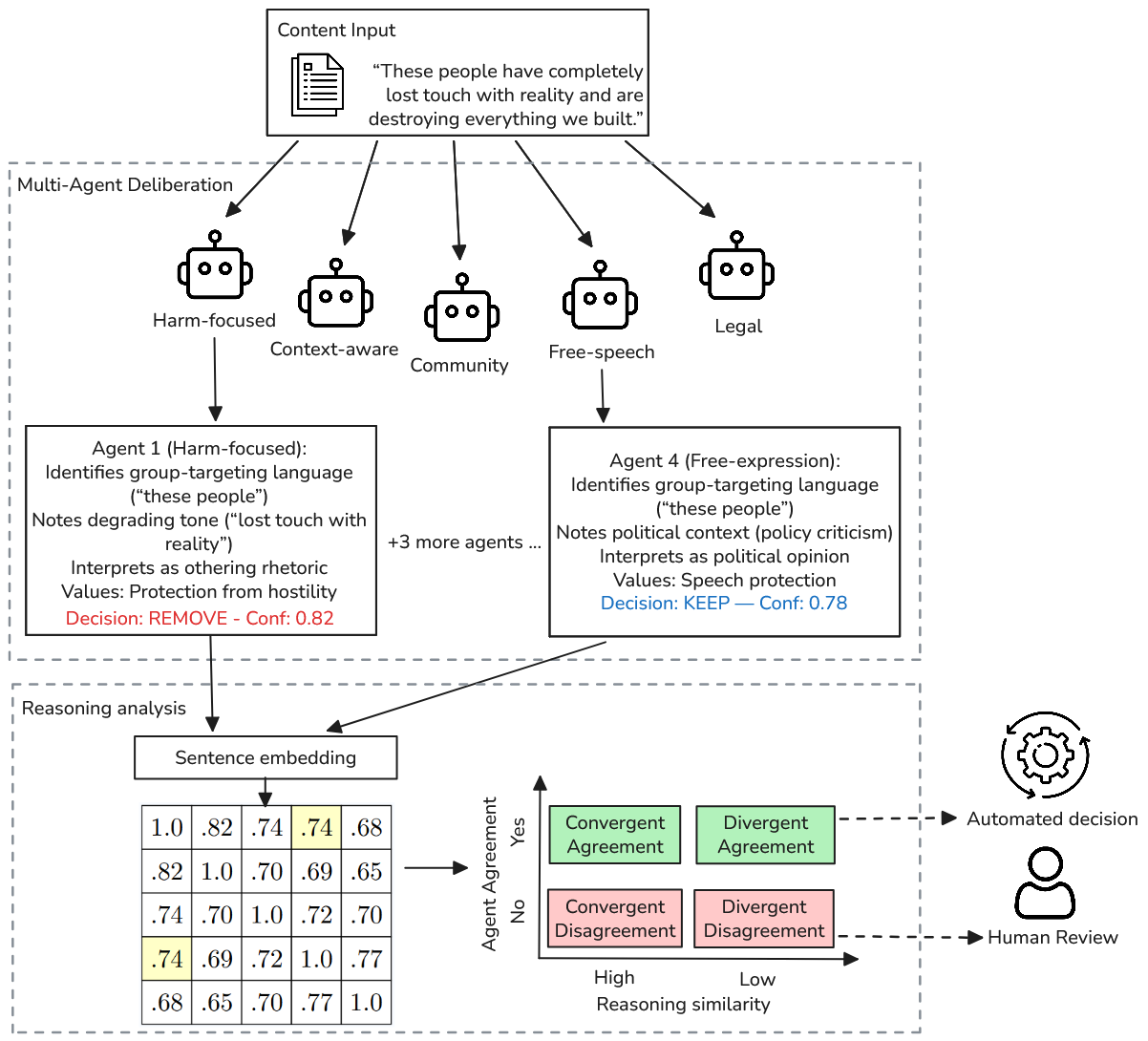
Figure 1: Framework overview—content processed by N perspective-differentiated agents, reasoning traces embedded and compared for structural disagreement analysis; taxonomy guides escalation.
Experimental Validation and Numerical Results
Evaluation employs the Measuring Hate Speech corpus, comprising annotated social media comments stratified by human annotator disagreement (standard deviation across ordinal ratings). For each comment (n=600), agent decisions and reasoning traces are collected, embedded, and analyzed. Reasoning similarity threshold θs is empirically selected.
Agent reasoning divergence demonstrates weak negative correlation with human annotator disagreement (r=−0.19): cases where agents reason more differently are not those with high human disagreement. Instead, the taxonomy delivers substantive signal. Kruskal-Wallis testing across categories (H=54.0) shows a significant separation:
- Both Convergent Disagreement (CD) and Divergent Disagreement (DD) exhibit high mean human disagreement ($0.813$, $0.763$), distinctly above Convergent Agreement and Divergent Agreement.
- The primary effect is between agreement and disagreement categories (Cohen's d>0.8 for DA vs. CD/DD).
- Category-based escalation achieves highest F1 (0.548) over divergence-only (0.503) and random (0.401), though divergence-only predictor yields higher recall.
Analysis is robust across similarity thresholds (ρ∈[0.25,0.30]), confirming structural disagreement remains informative under reasonable parameter choices. The taxonomy’s principal operational benefit is interpretability in escalation justification.
Theoretical and Practical Implications
Empirical results substantiate that disagreement structure between multi-agent LLMs captures dimensions of human value pluralism, and that structural taxonomy analysis is diagnostically superior to raw divergence metrics. This shifts the moderation paradigm from consensus optimization to collaborative sense-making—where uncertainty and value conflict are surfaced for human adjudication rather than suppressed.
The model operationalizes insights from judgment aggregation theory and collective intelligence, recognizing the discursive dilemma: premise-level consensus may mask conclusion-level pluralism. Architecturally, the study’s limitation is the use of single-model agents, with perspective-induced vocabulary variation potentially inflating semantic divergence. Diverse agent instantiations could further refine taxonomy distributions.
Practically, structural disagreement analytics enable improved escalation of contested cases, which is highly desirable in safety-critical moderation. Taxonomy-based routing supports interpretable decision pipelines, especially relevant as moderation scales and human oversight resources are increasingly constrained.
Future Directions
Key developments will include scaling evaluation to larger, more diverse corpora, incorporating architecturally heterogeneous agent collectives, and empirically validating whether taxonomy-based escalation demonstrably improves real-world moderation quality and fairness. There remains unexplored potential in aligning disagreement taxonomies with nuanced ground-truth pluralism, leveraging trace analytics for domain-general uncertainty detection, and integrating reasoning trace analysis into broader human-AI collaborative workflows.
Conclusion
This research reframes multi-agent disagreement in AI moderation as a diagnostic signal for value pluralism, proposing structural reasoning trace analysis as a means to distinguish genuine contested content requiring human judgment. The taxonomy guides appropriate escalation and supports a transition from consensus-driven systems to uncertainty-surfacing collaborative architectures. The approach offers practical interpretability gains and advances theoretical understanding of collective intelligence in moderation, motivating continued exploration of disagreement-informed decision-making in AI content moderation systems.