- The paper introduces SMTPO, a simulator-guided multi-turn RL framework that mitigates feedback bias in LLM-based conversational recommendations.
- It leverages multi-task SFT-trained user simulators, dual-view retrieval, and fine-grained RL reward design to iteratively refine user preferences.
- Empirical evaluations on ReDial and INSPIRED datasets show significant improvements in ranking quality and recommendation accuracy over state-of-the-art baselines.
User Simulator-Guided Multi-Turn Preference Optimization for LLM-Based Conversational Recommendation
Motivation and Problem Statement
The paper "User Simulator-Guided Multi-Turn Preference Optimization for Reasoning LLM-based Conversational Recommendation" (2604.03671) addresses the fundamental limitations in conventional Conversational Recommender Systems (CRSs), including information-scarce dialogue histories and the inadequacy of single-turn recommendation paradigms for modeling complex, multifaceted user preferences. The integration of LLMs into CRS frameworks increases semantic expressiveness and reasoning capabilities, but brings new challenges: standard LLMs lack robust alignment mechanisms for collaborative filtering signals, and the reliance on user simulators introduces feedback bias, leading to error accumulation over multi-turn interactions.
The paper identifies two principal obstacles: the need to align simulated feedback with true user preferences (in the absence of explicit labels), and the necessity for robust recommender optimization under dynamic, potentially biased simulator-generated feedback. The proposed framework, SMTPO (Simulator Multi-Turn Preference Optimization), systematically addresses these multi-turn interaction challenges by leveraging fine-tuned user simulators, a dual-view retriever, and a two-stage SFT + RL policy optimization for the Reasoning LLM-based recommender.
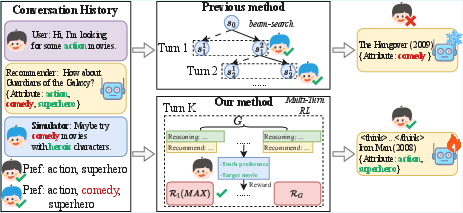
Figure 1: Comparison of previous CRS methods—sensitive to feedback bias due to frozen parameters and beam search filtering—versus SMTPO’s RL-trained recommender for robust, accurate preference modeling.
SMTPO Framework: Architecture and Algorithms
The SMTPO framework decomposes into three modules:
- User Simulator: An LLM-trained via multi-task SFT generates feedback on recommendations, simulating realistic user preference expression in natural language. The multi-task SFT approach encompasses feedback generation, attribute alignment, and target prediction, enhancing output specificity and informativeness.
- Retriever: Implements a collaborative-semantic dual-view modeling. Semantic encoders process conversation history and simulator feedback, while collaborative encoders leverage entity relationships in Knowledge Graphs (e.g., movie-attribute pairs). Feature fusion occurs via spatial adapters and cross-attention, producing item representations tightly constrained within the global item space.
- Reasoning LLM-based Recommender: The core recommendation engine is initialized with SFT for task warm-start. Interaction proceeds as multi-turn RL (GRPO algorithm), optimizing with fine-grained reward decomposition—including format, recommendation, and preference rewards—to iteratively align recommendation outputs to true user preferences despite simulator bias.
The multi-turn interaction process is organized as follows: initial retrieval, preference inference, recommendation, feedback generation, dynamic candidate set update, and further interaction. Training is staged for module isolation and stability; simulator and retriever are pre-trained before recommender RL.
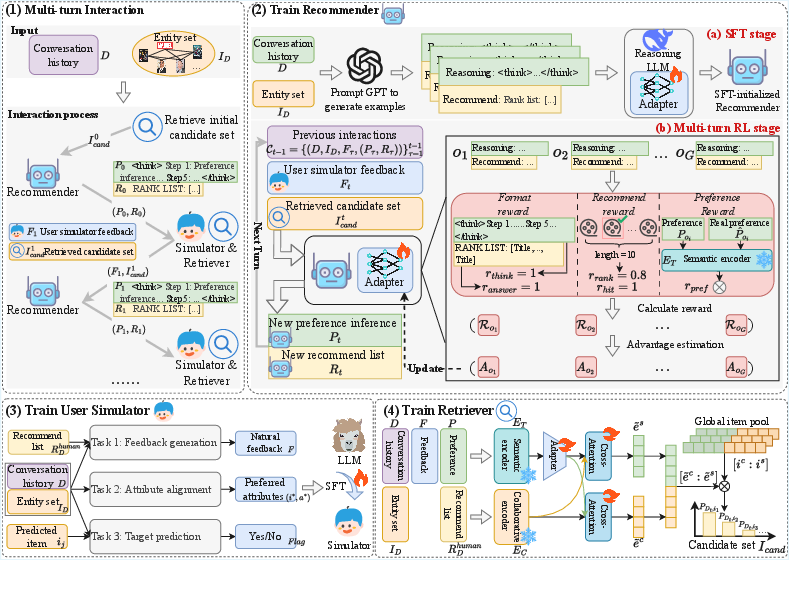
Figure 2: SMTPO training and operation: multi-turn recommender-simulator-retriever interaction, module SFT/RL training protocols, and dual-view candidate generation.
Empirical Evaluation and Numerical Results
Experiments are conducted on established CRS datasets, ReDial and INSPIRED, employing a diverse suite of baselines: conventional recommenders (Popularity, BERT), zero-shot LLMs (L3.1-8B-I, GPT-3.5, GPT-4o), and state-of-the-art CRS models (KBRD, TREA, MSCRS, UniCRS, DCRS). Evaluation metrics include Recall@1/10, NDCG@10, and MRR@10.
SMTPO achieves strong, statistically significant improvements across all metrics, as evidenced by Recall@10 and NDCG@10, outperforming both specialized CRS models and zero-shot LLMs. Notably, SMTPO’s multi-turn optimization delivers robust gains in recommendation quality, with progressive improvements over interaction turns. Ablation studies confirm the necessity of multi-task SFT for simulator fidelity, and highlight the critical contribution of SFT/RL stages in the recommender.
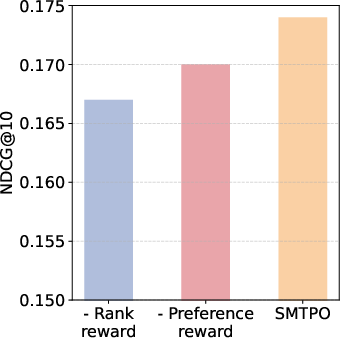
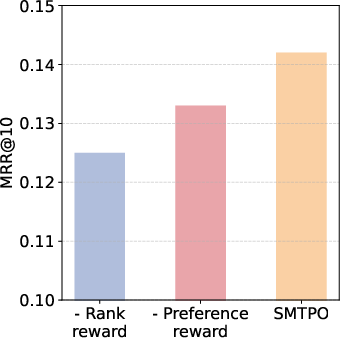
Figure 3: NDCG performance—SMTPO consistently outperforms ablated variants and baselines, demonstrating superior ranking quality.
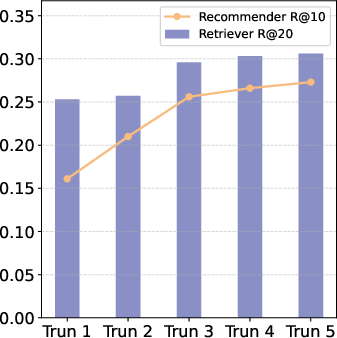
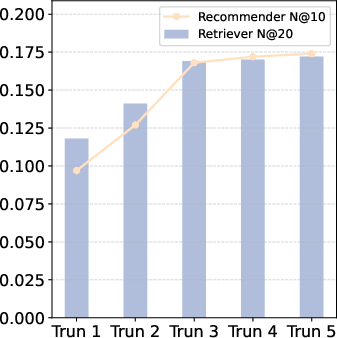
Figure 4: Recall performance—SMTPO yields elevated recall through multi-turn RL policy adjustment, evidencing dynamic preference refinement.
Analysis of Optimization and Robustness
Multi-turn RL with reward engineering is central to SMTPO’s recommendation robustness. The format reward ensures correct reasoning chain and answer structure. Recommend reward (Hit, Rank) precisely guides ranking behavior, while preference reward directly aligns inferred preferences via semantic similarity metrics. Ablation reveals the rank reward’s disproportionately strong impact on MRR and NDCG, substantiating the value of fine-grained reward design.
Dynamic feedback from a multi-task SFT simulator—integrating conversational context and prior recommendations—enables continuous refinement, mitigating bias propagation. Blind and noise-injection experiments confirm performance degradation when dynamic feedback is absent or irrelevant, ruling out gains due to pretraining memorization or prompt engineering.
Case studies show iterative improvement: as turns progress, the recommender increasingly aligns outputs with latent user preferences and elevates the target item in ranking, exploiting attribute-level feedback, and collaborative entity signals. SMTPO’s dual-view retriever consistently recalls relevant candidates, further stabilizing multi-turn optimization.
Practical and Theoretical Implications
SMTPO demonstrates that LLM-based CRS frameworks can achieve robust, generalizable preference modeling via simulator-guided, multi-turn RL optimization, even under feedback bias. This approach is transferable to other knowledge-centric dialogue personalization domains, where multi-turn interaction and dynamic feedback are paramount.
Theoretically, SMTPO substantiates the efficacy of hybrid LLM architectures combining language understanding, collaborative filtering, and explicit reward-driven sequential policy optimization for personalized recommendation. Practically, SMTPO provides a blueprint for integrating RL post-training into LLM conversational recommenders, advancing both robustness and accuracy under real-world, information-scarce scenarios.
Future developments in AI-enabled CRS will likely pursue further refinement in user simulator construction (e.g., human-involved simulation, adversarial feedback generation), richer reward decomposition, and scaling dual-view retrieval to multi-modal item spaces. SMTPO’s architectural modularity supports these directions.
Conclusion
SMTPO introduces a principled simulator-guided, multi-turn RL optimization framework for LLM-based conversational recommendation, effectively resolving the challenges of preference alignment and robustness under biased feedback. Empirical evidence demonstrates significant improvements in accuracy, ranking quality, and generalization over state-of-the-art baselines. The architecture—anchored in multi-task SFT, dual-view retrieval, and fine-grained RL reward design—enables continuous preference refinement across conversational turns. SMTPO represents a rigorous, extensible model for future CRS research, offering both practical and theoretical advancement in the use of LLMs for multi-turn personalized recommendation (2604.03671).