- The paper presents a two-phase pipeline that integrates attention U-Net segmentation with CycleGAN-based synthetic augmentation, achieving a Dice score of 0.932.
- It uses attention gates to dynamically focus on salient nanoparticle boundaries, enhancing accuracy under complex imaging conditions.
- The approach enforces cycle-consistency with online augmentation, outperforming baselines by 7.25% in Dice and 9.25% in F1 score.
SAGE-GAN: Segmentation of Spatially Ordered Nanoparticles via Attention-Guided GANs
Introduction and Motivation
Automated segmentation of nanoparticles in SEM images is essential for characterizing nanomaterials, impacting domains such as materials science, drug delivery, and energy applications. Traditional segmentation approaches—ranging from thresholding and watershed algorithms to recent U-Net-based DL models—are severely limited either by robustness to complex imaging artifacts or their heavy dependence on large, expertly annotated training datasets. Existing synthetic augmentation pipelines introduce scalability at the expense of domain realism. The "SAGE-GAN: Towards Realistic and Robust Segmentation of Spatially Ordered Nanoparticles via Attention-Guided GANs" (2604.03637) directly addresses these core problems by combining self-attention-enhanced segmentation with a generative framework grounded in cycle consistency, thus ensuring structural fidelity between real and synthetic data.
Architecture and Methodology
The SAGE-GAN pipeline proceeds in two phases: attention-guided segmentation and segmentation-aware synthetic image generation. In Phase 1, an Attention U-Net is trained on real, annotated SEM images. Attention Gates dynamically modulate the feature flow along skip connections, spatially accentuating nanostructure-relevant information and attenuating background clutter.
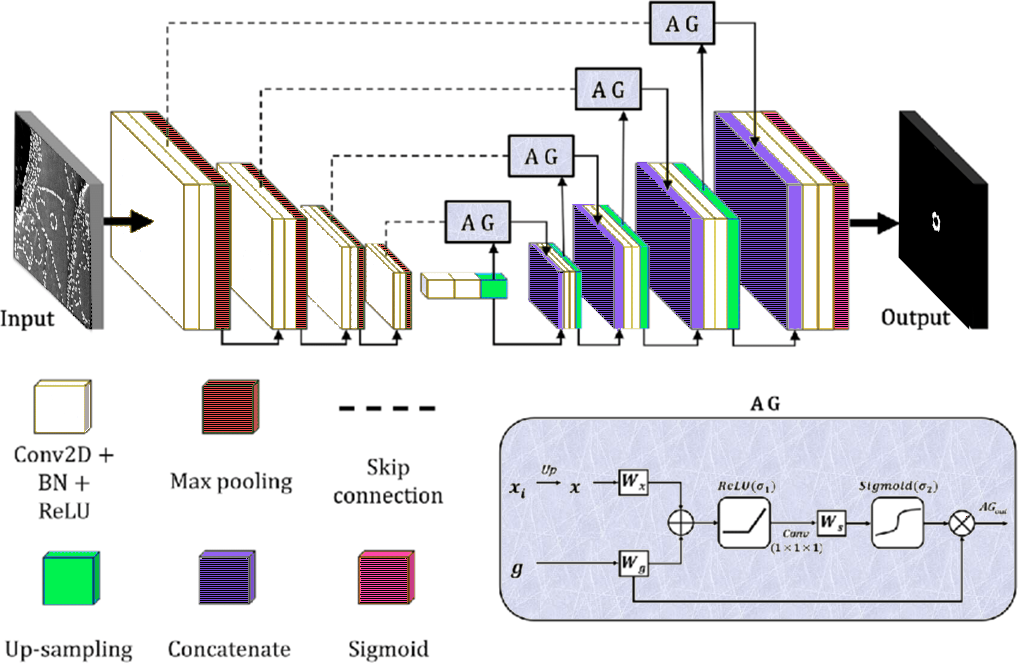
Figure 1: The Attention U-Net leverages spatial Attention Gates to focus on salient nanoparticle features, efficiently suppressing irrelevant image context.
In Phase 2, the pretrained Attention U-Net is embedded within a CycleGAN framework, inspired by cGAN-Seg, to enforce bidirectional structural correspondence between synthetic images and ground-truth masks.
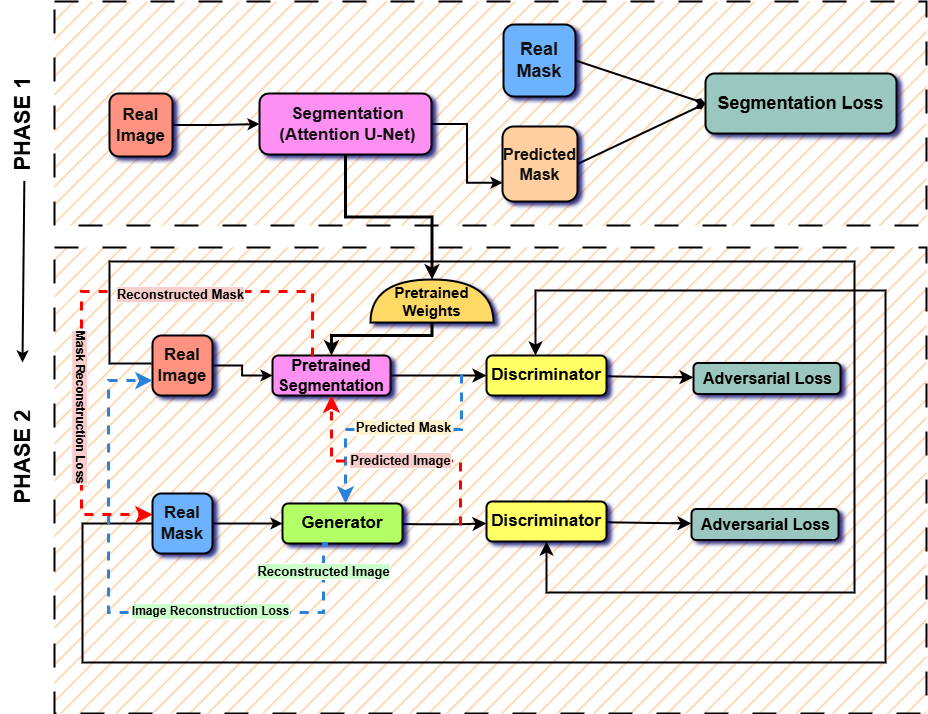
Figure 2: Schematic of the two-phase pipeline; self-attention-based pretraining is coupled with cycle-consistent adversarial generation, forming the foundation for robust synthetic augmentation and segmentation.
Here, the generator must produce SEM images from binary masks such that, when passed through the segmentation network, the resulting prediction is cycle-consistent with the originating mask. Adversarial losses are coupled with cycle-consistency and segmentation-specific objectives, ensuring that synthetic images are indistinguishable from real SEM data with respect to both textural realism and morphologically critical features.
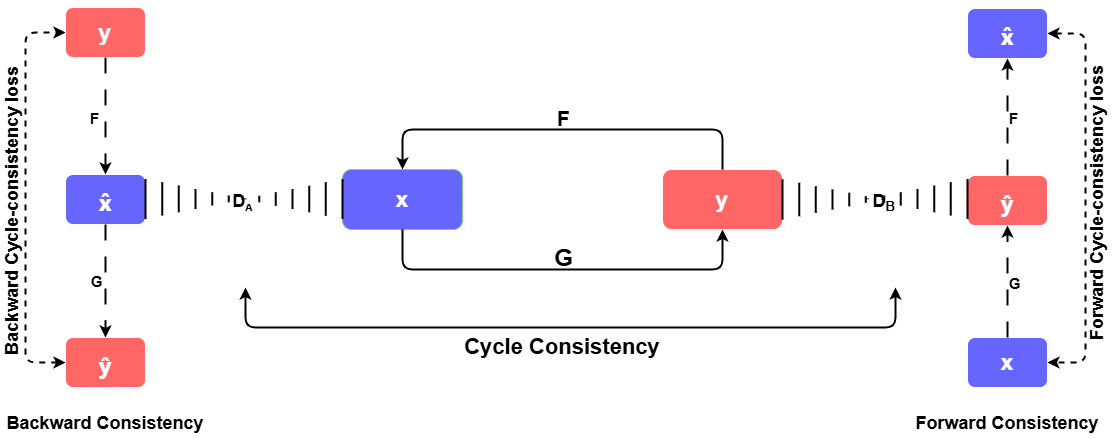
Figure 3: Standard CycleGAN architecture used, augmented here with segmentation feedback through the pretrained Attention U-Net.
An important innovation is the continual, online augmentation strategy: instead of statically populating the training set with synthetic pairs, the generator produces fresh examples at each training epoch, maintaining both diversity and exposure to rare structures.
Dataset and Preprocessing Strategy
The dataset comprises 140 authentic SEM images (annotated, loop-like S1 nanoparticles) and 400 synthetic images created in K-3D—however, only the authentic set is used for training and validation to avoid domain shift or overfitting to artificial regularities. Images undergo rigorous preprocessing (scaling, normalization, CLAHE, random crops, geometric flips) to maximize generalization. Notably, synthetic data only enters the training indirectly via the CycleGAN pipeline, preventing overdependence on nonphysical features, in contrast to prior approaches.


Figure 4: Typical image-mask pair from the original S1 dataset, serving as ground truth for both segmentation and structure-aware generation.
Experimental Evaluation
Exhaustive experimental validation is performed using an 80:20 split on the 140 authentic images. The two-phase training is operationalized as 200 epochs for U-Net pretraining (segmentation) and 500 epochs of generator-adversarial (CycleGAN) co-training. SAGE-GAN achieves a Dice score of 0.932 and F1 score of 0.956 on held-out validation, outperforming all contemporary baselines—including Half U-Net, DC U-Net, U-Net++, cGAN-Seg, and Attention U-Net—by a significant margin (notably, a 7.25% uplift in Dice and 9.25% in F1 over pure Attention U-Net).









Figure 5: Segmentation predictions (right) align closely with manual ground truth masks (center) and the input SEM images (left), preserving nanoparticle boundaries, topology, and intricate detail.
The effectiveness is primarily attributed to the hybrid loss function—Cross Entropy plus Focal Tversky—which robustly addresses class imbalance and small-object segmentation, yielding a 4.25% and 11.68% performance gain in Dice and F1 relative to Dice-only loss.
Attention Mechanism Visualization
The evolution of spatial focus in Attention Gates is visualized across training epochs, displaying a progressive specialization: from an initial broad, noisy activation to a crisp localization at nanoparticle boundaries. This measurable adaptation demonstrates that the embedded attention mechanism is not only interpretable but directly responsible for improved edge localization and robustness to background artifacts.




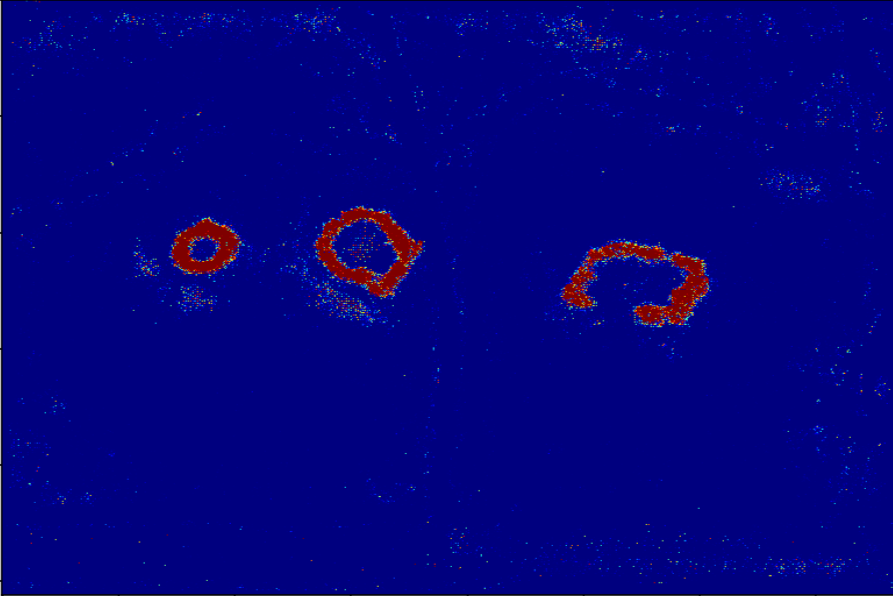

Figure 6: Evolution of attention coefficients reveals the model’s increasing ability to localize salient regions; red depicts high attention, blue background suppression.
Qualitative overlays further confirm close alignment between high-attention regions and annotated masks—even on validation samples with challenging morphologies or low contrast.

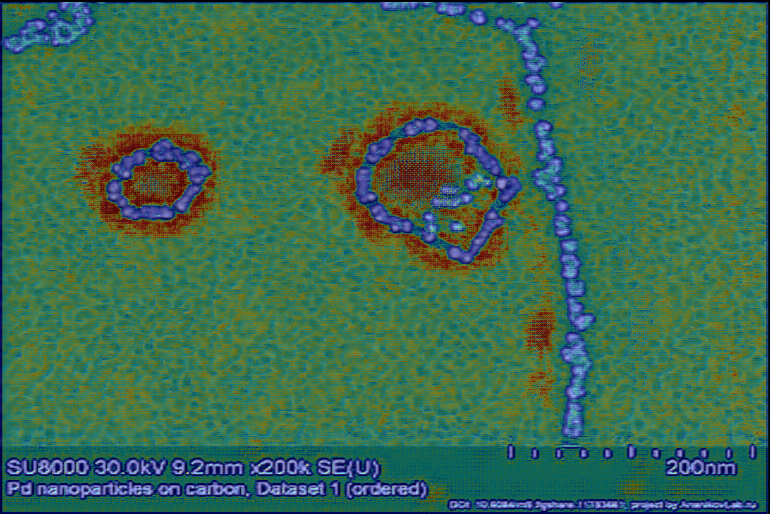
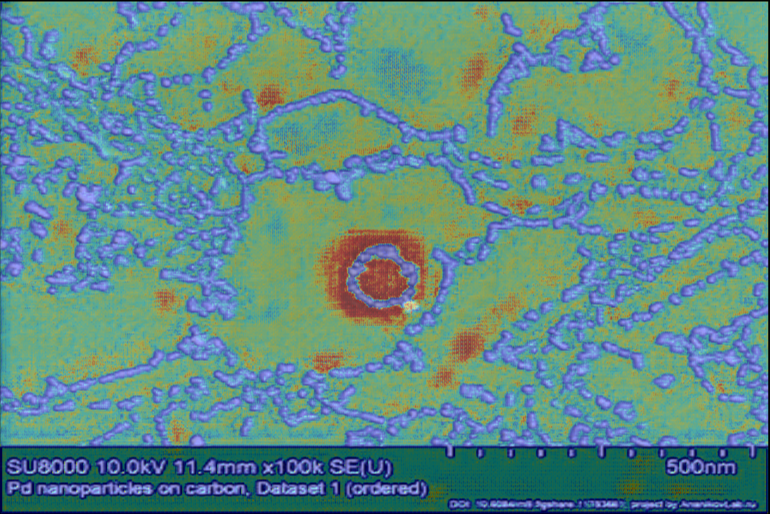
Figure 7: Superimposed attention maps on real SEM images underscore the model’s capacity to focus on nanoparticle boundaries and structurally relevant morphologies.
Practical and Theoretical Impact
SAGE-GAN redefines data augmentation in the context of limited labeled nanoparticle data by coupling segmentation-aware generative modeling with attention-guidance. The pipeline produces structurally consistent, physically meaningful synthetic data while enabling robust transfer to downstream segmentation. The architecture natively resolves the trade-off between large-scale synthetic augmentation and the preservation of domain realism, a recurrent issue for prior purely graphics- or GAN-based strategies. The attention-guided mechanism introduces a scalable way to leverage context and focus in small-structure, low-contrast environments—a scenario prevalent in microscopy.
SAGE-GAN’s framework is adaptable to new materials systems, supports rapid re-training for emerging morphologies, and minimizes annotation burden. It thus offers a deployable solution for throughput-limited or “few-shot” regimes in nanomaterial imaging.
Future Directions
Extension of SAGE-GAN to 3D volumetric inputs (e.g., tomography), multimodal imaging (TEM, AFM), and unsupervised or weakly-supervised regimes is a direct avenue for further research. Model interpretability, supported by attention overlays, could be leveraged for physicochemical feature discovery and automated quality control pipelines. As generative models continue to match real-data distributions, combinations with physics-informed priors or uncertainty modeling could further mitigate domain adaptation gaps and propagate this approach into broader, high-impact materials science and nanotechnology applications.
Conclusion
SAGE-GAN introduces a rigorously structured, attention- and segmentation-aware generative pipeline that achieves robust, high-fidelity nanoparticle segmentation with minimal labeled data. This is substantiated by substantial numerical gains over SOTA models and qualitative visualizations of morphologically correct predictions and interpretable attention maps. The segmentation-guided generative approach addresses both practical and theoretical limitations of prior methods, constituting a highly deployable and extensible toolkit for automated nanoscale imaging analysis.

