- The paper develops a unified framework that augments standard regression discontinuity analysis by integrating latent variable models with multilevel data structures.
- It employs the Metropolis-Hastings Robbins-Monro algorithm to efficiently estimate parameters and average treatment effects across hierarchical and multisite designs.
- Simulation studies demonstrate minimal bias and robust ATE estimation near the cutoff, highlighting the framework's practical benefits in settings with noisy assignment variables.
Multilevel Regression Discontinuity Models with Latent Variables
Introduction
This work, "Multilevel Regression Discontinuity Models with Latent Variables" (2604.03535), develops a unified statistical framework that augments regression discontinuity (RD) analysis with both latent variable (LV) modeling and multilevel data structures. Conventional RD identifies causal effects at sharp assignment thresholds, typically assuming error-free proxy measures for assignment (the running variable, RV) and often ignoring nested structures prevalent in educational data. Recent advances introduced RD with latent variables to address noisy proxies but were limited to single-level contexts. This paper extends the latent RD paradigm to hierarchical (HRD) and multisite (MRD) experimental settings, integrating latent measurement and multilevel variance components. The proposed approach generalizes RD inferences, permitting robust estimation and extrapolation of the average treatment effect (ATE) and assessment of treatment effect heterogeneity in clustered data with noisy assignment variables.
Framework and Model Specification
Multilevel Data and RD Assignment Mechanisms
The analysis delineates two major multilevel RD designs:
- Hierarchical RD (HRD): Treatment assigned at the cluster level (e.g., all students within a school receive the program if the school's mean observed RV falls below a cutoff), with outcomes observed at the individual level.
- Multisite RD (MRD): Treatment assigned at the individual level (based on within-individual observed RV), but individuals are nested within clusters due to the sampling scheme.
Both designs necessitate modeling the hierarchical error structure to address intra-cluster correlation.
Latent Running Variable and Measurement Model
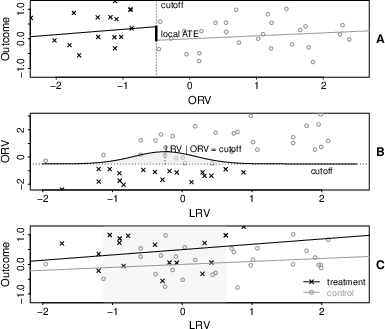
A distinguishing feature is the explicit modeling of the latent running variable (LRV) using an item response theory (IRT) measurement framework. The observed proxy (ORV, such as a summed test score) is treated as a noisy indicator of the LRV. Each individual’s LRV is decomposed into a cluster effect and an individual deviation, with observed indicators modeled via a 2-parameter logistic (2PL) item model. This construction enables unbiased recovery of treatment effects, corrected for classical measurement error, and facilitates treatment effect estimation conditional on latent constructs rather than error-laden observable proxies.
Both HRD and MRD structural models incorporate random effects to represent unobserved heterogeneity attributable to clustering. Key features include:
- Interaction terms to capture effect modification by the LRV
- Fixed and random slopes/intercepts capturing between- and within-cluster variance in both potential outcomes and treatment effects
- Potential outcomes notation reflecting the causal estimands under the Rubin causal model
Causal Estimation: ATEs and Heterogeneity
A major conceptual advance is distinguishing estimands conditional on ORV and on LRV. Classical RD only identifies the LATE at the cutoff of the observed running variable. Here, the framework enables estimation of:
- ATE conditional on the LRV: Reflects the treatment contrast for a specific value of the latent trait, not just at the cutoff.
- ATE conditional on ORV: Derived by integrating the LRV over its posterior distribution given observed data, accounting for measurement noise.
This facilitates:
Estimation via the MH-RM Algorithm
Parameter estimation is accomplished using the Metropolis-Hastings Robbins-Monro (MH-RM) algorithm, offering scalable estimation in the presence of multiple random effects and latent variables. The procedure combines stochastic imputation from the model’s joint posterior, efficient gradient approximation, and stochastic approximations for parameter updates. This is particularly advantageous over classical quadrature when the dimension of the latent space is high (e.g., >3). Standard errors are derived using Louis’ formula, approximated via posterior sampling, enabling correct uncertainty quantification for parameter and ATE inference.
Simulation Study
A comprehensive simulation study evaluates the fidelity of ATE recovery and parameter estimation under varying sample sizes, cluster structures, and effect sizes. Summary findings include:
- HRD Model:
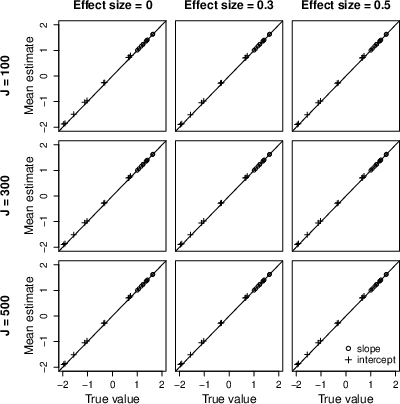
- Structural parameter bias is minimal and RMSEs decrease with increased cluster count (Figure 2).
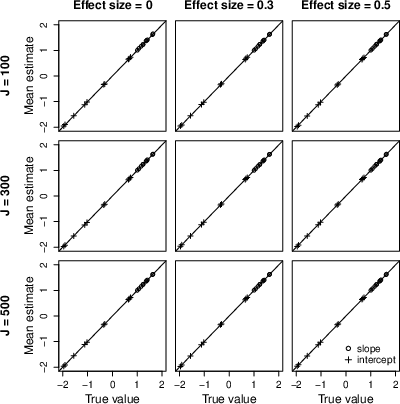
- ATE estimation is accurate at and near the cutoff (c±1), with coverage of nominal 95% CIs improving with more clusters (Figure 3).
- Estimation error increases farther from the cutoff, reflecting the attenuation of identification due to reduced overlap in LRV.

Figure 2: Bias and RMSE for key HRD structural parameters, as a function of number of clusters.

Figure 3: Bias, RMSE, and CI coverage for ATE estimation at various ORV values under the HRD model as cluster count varies.
- MRD Model:
- Parameter recovery is superior to HRD, with smaller RMSE, attributed to higher effective sample size in individual-level treatment assignment (Figure 4).
- ATE estimation is precise across a broad ORV spectrum (c±2), with stable coverage properties (Figure 5).

Figure 4: Bias and RMSE for MRD structural parameters as number of clusters increases.

Figure 5: Bias, RMSE, and CI coverage for ATE estimation at various ORV values under the MRD model.
- Measurement Parameter Estimation:
Practical and Theoretical Implications
This framework substantially broadens RD analysis for education and social sciences by allowing:
- Valid causal inference in complex multilevel structures where treatment assignment and data collection are hierarchically organized.
- Correction for measurement error in assignment variables, avoiding bias and enhancing interpretability of treatment effect estimates.
- Extrapolation of ATEs and quantification of heterogeneity: Directly addresses decision-making needs beyond the cutoff, such as policy implications for alternative assignment thresholds.
- Flexibility: Model can be extended to include additional covariates—observed or latent—and more complex latent constructs (e.g., multidimensional LVs, multiple assignment variables).
Numerical results indicate that with sufficient cluster-level sample sizes, finite sample bias is negligible and interval coverage is reliable. The method’s performance degrades as extrapolation moves far from the cutoff, emphasizing the substantive limitation on inference range imposed by RD design and measurement error model assumptions.
Future Directions
Potential extensions include generalization to models with unbalanced clusters, variable intraclass correlation (ICC), and test length heterogeneity, reflecting more realistic operational settings in education research. Employment of multidimensional latent measurement frameworks, covariate adjustment, and multidimensional assignment rules (e.g., via multiple eligibility criteria) are direct extensions that would enhance utility. More generally, the integration of this framework with Bayesian hierarchical approaches, leveraging modern MCMC or variational inference, promises further improvements in estimation under highly complex designs.
Conclusion
This study establishes a comprehensive methodology for multilevel RD with latent running variables, enabling unbiased and efficient causal inferences in clustered, error-prone assignment contexts ubiquitous in education research. The combination of flexible modeling, robust estimation, and analytic tools for effect heterogeneity and extrapolation marks a significant methodological contribution. Future research should address additional layers of complexity and practical deployment in large-scale evaluative studies.