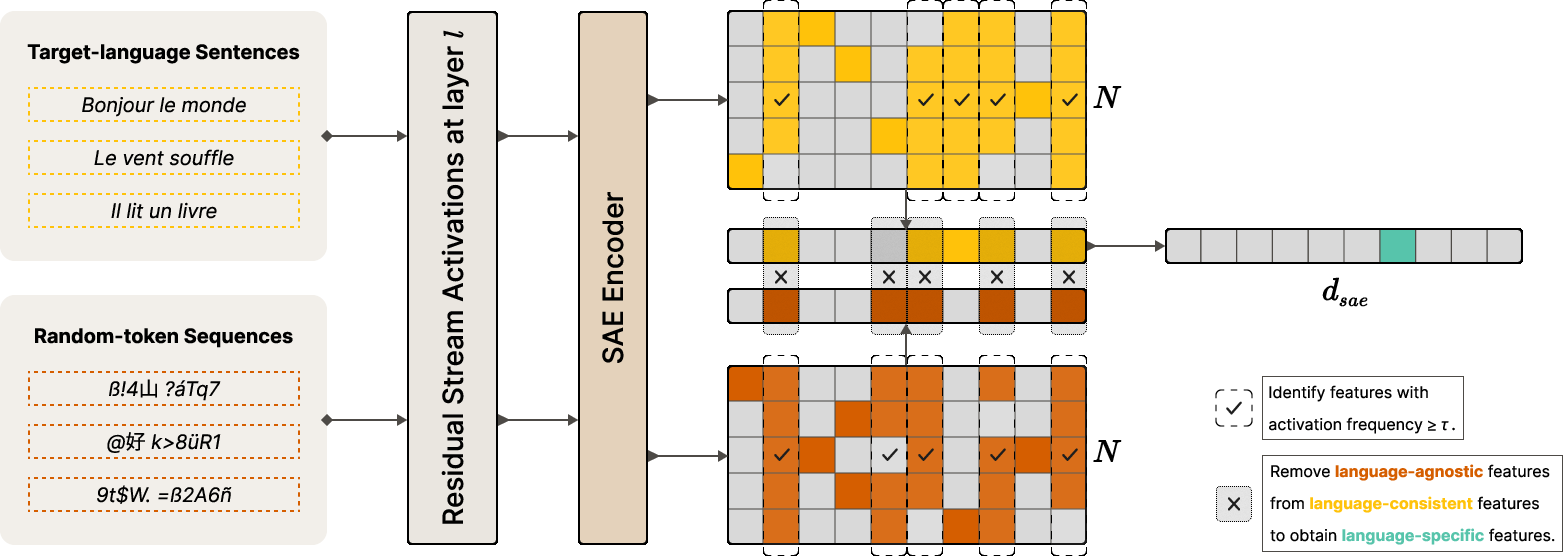
- The paper introduces a novel sparse autoencoder approach combined with random-token filtering to isolate highly selective language-specific features.
- It demonstrates that less than five features per language consistently emerge, ensuring robust language steering across diverse multilingual LLMs.
- Ablation studies show that removing key features sharply increases cross-entropy loss, confirming their causal role in language-specific processing.
LangFIR: Discovering Sparse Language-Specific Features from Monolingual Data for Language Steering
Motivation and Context
Reliable language control in multilingual LLMs remains unsolved—existing models can generate text in many languages but often fail to consistently adhere to a desired target language, especially outside high-resource settings. Prior steering techniques largely depend on extensive multilingual or parallel corpora and often lack interpretability, limiting their applicability. LangFIR addresses this by leveraging sparse autoencoder (SAE) representations and a novel random-token filtering mechanism to extract highly selective, causally impactful language-specific features using only small monolingual samples.
Methodology
The LangFIR pipeline is composed of three key stages: (1) random-token generation, (2) SAE-based activation analysis, and (3) random-token filtering.
The key innovation is the deployment of random-token sequences to empirically surface features encoding generic (language-independent) patterns, which are then systematically excluded—prior approaches are confounded by entanglement among shared features.
Analysis of Language-Specific Features
Sparsity and Sample-Efficiency
LangFIR consistently yields extreme sparsity—typically less than five features per language are retained after filtering, with both language-specific set stability and overlap converging within ∼100 samples (see Figure 2 and related discussion). Importantly, the method is robust—feature count and composition stabilize as sample size and threshold increase, with results consistent for τ≥0.8.
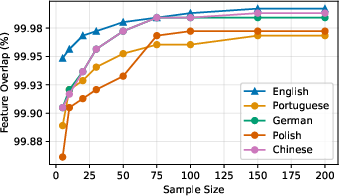
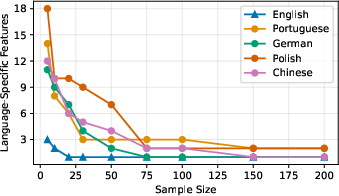
Figure 2: Feature set overlap versus sample size, demonstrating stability and convergence; nearly all language-consistent features overlapping with random-token features are eliminated.
Selectivity and Causal Importance
The remaining features exhibit highly language-selective activation patterns. Activation of the top-ranked feature for each language is sharply peaked: strong on in-language data, near zero otherwise (Figure 3). In contrast, non-language-specific features activate uniformly across all languages, with a consistent English elevation due to English-centric training data in most models (Figure 4).
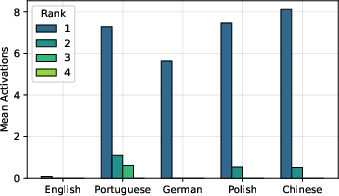
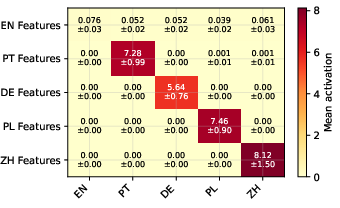
Figure 3: Mean activations of top-ranked language-specific features, peaked on their respective language.
Ablation of only the top-2 identified features for a given language yields a substantial and selective increase in cross-entropy loss for that language but negligible effect for others, establishing these features as causally necessary for language-specific processing (Figure 5).
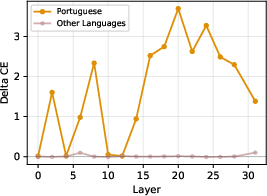
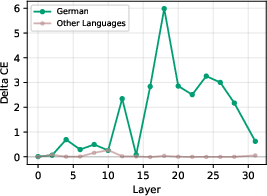
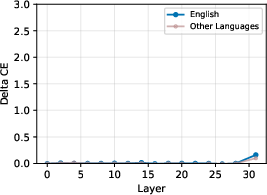
Figure 5: Cross-entropy loss increases specifically for Portuguese after ablating its top language-specific features, with minimal impact on other languages.
Feature counts by layer (Figure 6) show both an early- and late-layer concentration, but activity magnitudes and ablation effects peak in late layers, aligning with known representations of language identity at that model depth.
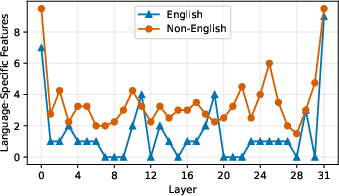
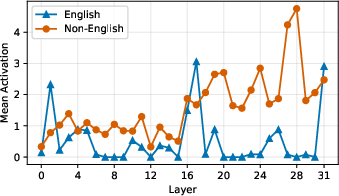
Figure 6: Language-specific feature density across layers, with peaks at model boundaries.
Feature-Guided Language Steering
LangFIR features are used to construct steering vectors for controlled generation. For each target language, the top-k language-specific SAE features (by mean activation) are decoded to form an ℓ2-normalized steering direction, applied additively to the residual stream at a late layer.
Comprehensive experiments encompass three SOTA multilingual LLMs (Gemma 3 1B, Gemma 3 4B, Llama 3.1 8B), twelve typologically diverse languages, and three translation datasets. ACC × BLEU, integrating language identification accuracy and translation quality, is the principal metric.
LangFIR achieves highest average ACC × BLEU on all three models, outperforming even parallel-data-based baselines (including DiffMean) by significant margins (up to 2.7 points), and outdistancing the strongest monolingual baseline by up to 4.7× (see main results table).
Ablation studies demonstrate robustness: as few as 10 monolingual sentences suffice for near-optimal steering, and removal of the random-token filtering step degrades both language control and translation quality by more than an order of magnitude (Figure 7).
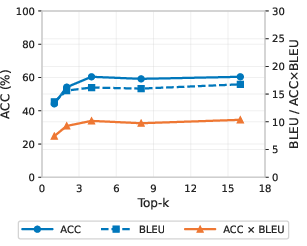
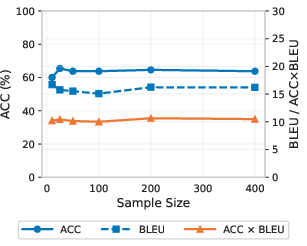
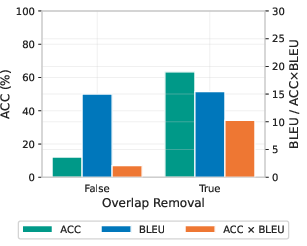
Figure 7: Steering performance as a function of the number of top-k features; performance saturates at Sspec=Slang∖Srand0.
Theoretical and Practical Implications
LangFIR’s results strongly support the hypothesis that language identity in multilingual LLMs is encoded as a small, extremely sparse subset of feature directions in late model layers, both causally necessary and efficiently activatable. The methodology’s sharp selectivity and data efficiency extend the practical scope of steering—LangFIR can be deployed in settings devoid of high-quality parallel corpora, massively lowering the resource barrier for language control in deployed models.
The clean separation of language identity from language-agnostic features, via random-token filtering, addresses a longstanding entanglement problem for representation-based intervention methods. This approach paves the way for more interpretable, robust, and modular control over model internal mechanisms.
Future Directions
The work invites further investigation into the structure of SAE features across language families, model size scaling, and the interplay of SAE variants with feature interpretability. Extension to other forms of generative control (style, dialect, author imitation), as well as precision diagnosis of language entanglement—particularly for English—present rich future research opportunities.
Conclusion
LangFIR delivers an efficient, interpretable, and causally validated method for extractive language steering in multilingual LLMs, requiring only monolingual samples. By leveraging random-token filtering in conjunction with sparse autoencoding, the method isolates highly selective and manipulable language-specific features, leading to state-of-the-art monolingual steering performance exceeding even parallel data-based competitors. This marks a shift towards resource-light, analysis-driven control over LLM output domains, with significant implications for both LLM deployment and interpretability research.
Reference:
"LangFIR: Discovering Sparse Language-Specific Features from Monolingual Data for Language Steering" (2604.03532)