- The paper introduces CresOWLve, a bilingual benchmark assessing creative integration of real-world knowledge through annotated puzzles.
- It employs detailed annotations on knowledge domains, creative reasoning strategies, and cultural contexts to compare factual and creative questioning.
- Results reveal state-of-the-art models struggle with metaphorical and abstract connections, highlighting gaps in synthesizing non-obvious, cross-domain insights.
CresOWLve: A Benchmark for Creative Problem-Solving Grounded in Real-World Knowledge
Motivation and Contributions
The CresOWLve benchmark addresses a fundamental gap in the evaluation of LLMs: current benchmarks either focus on isolated components of creative reasoning (e.g., lateral thinking tasks, divergent idea generation, factual recall) or use contrived puzzles that lack real-world context. CresOWLve introduces a suite of creative problem-solving questions requiring integration of broad, real-world knowledge with multiple creative thinking strategies (vertical/lateral reasoning, abstract and analogical connections), extracted from the “What? Where? When?” intellectual game. Each problem is annotated for difficulty, domains, creative reasoning strategies, and cultural context, after rigorous filtering and bilingual translation.
Key contributions:
- A manually validated, bilingual dataset (English/Russian) with 2,061 creative and 352 factual questions spanning diverse knowledge and creativity domains, incorporating real-world puzzles with unique single-answer solutions.
- Fine-grained annotation of required knowledge domains, creative thinking types, and cultural backgrounds, enabling multidimensional analysis of LLM performance.
- Comprehensive evaluation of frontier non-thinking and thinking LLMs, revealing substantial gaps in creative reasoning, especially integration of non-obvious knowledge connections.
Benchmark Construction and Diversity
The benchmark leverages 50 years of curated puzzles, filtered for accessibility, cultural dependence, and answerability. Multiple stages of LLM and human validation eliminate questions requiring external materials or irreducible Russian-specific knowledge, ensuring cross-lingual utility.
CresOWLve questions are annotated across three major axes:
- Knowledge Domains: Each question involves multiple domains (average 2–4 per question), with a final set of 34 broad categories (e.g., Literature, History, Linguistics, Environmental Sciences).
- Creative Reasoning Concepts: Lateral thinking dominates, supplemented by abstraction, analogy, and figurative language requirements (poems, puns, metaphors, jokes, etc.)
- Culture/Demographic Diversity: While Russian and English are the primary cultures, many questions reference French, German, Italian, Greek, and other cultural contexts.
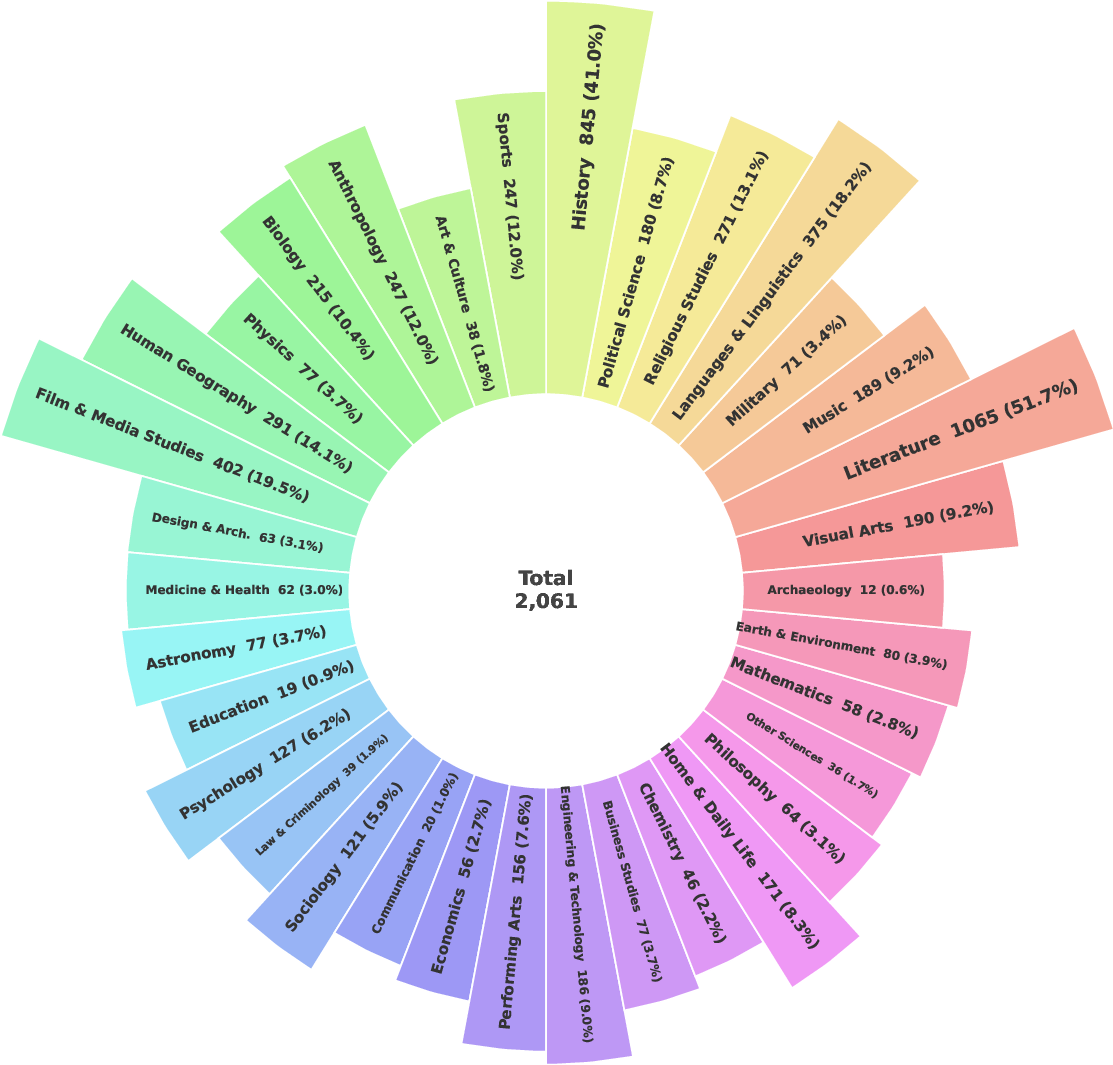
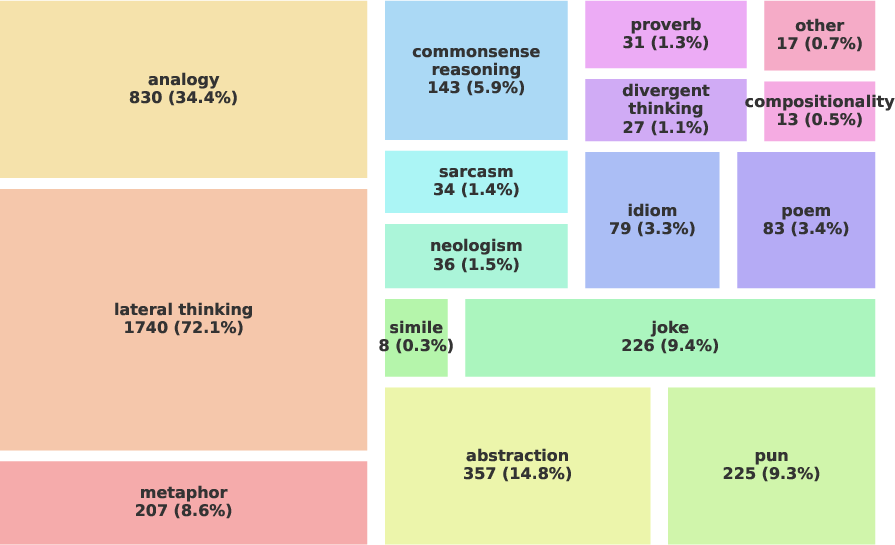
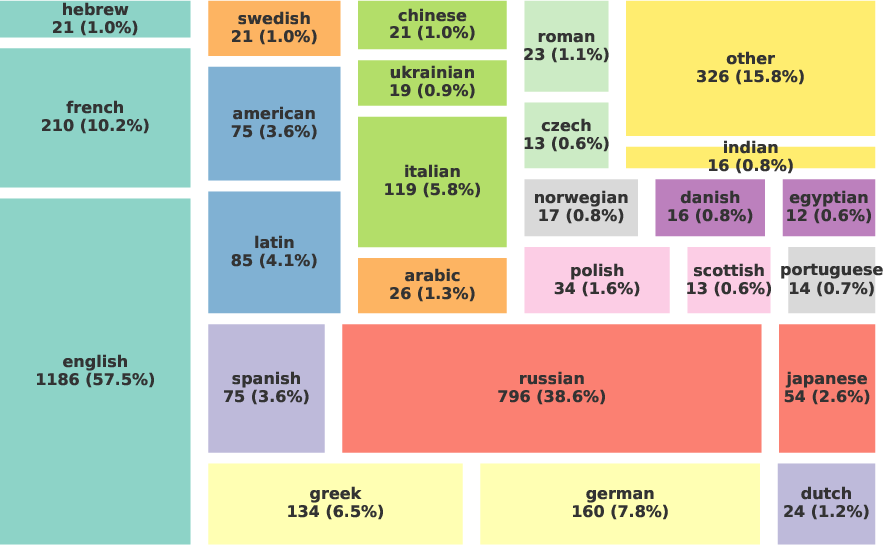
Figure 1: Diversity of real-world knowledge, creative language constructs, and cultures represented in the CresOWLve benchmark.
Additionally, the factual/creative split enables controlled comparison of straightforward retrieval versus synthesis-intensive reasoning.
Experimental Setup
LLMs are evaluated via open-ended question answering, using either Chain-of-Thought (CoT) prompting (for non-thinking models) or “thinking mode” prompts (for models trained to reason explicitly). Performance is assessed with both Exact Match and LLM-as-a-Judge metrics, the latter employing GPT-4o to allow for benign divergences in form and semantics.
Models are categorized into:
- Non-Thinking Models: Direct generation, optionally with CoT (e.g., OLMo, Llama-3, Qwen3, GPT-4.1 mini)
- Thinking Models: Explicit reasoning processes (adaptive effort), including proprietary (Gemini-3, GPT-5.4, GLM-5, DeepSeek-V3.2) and open-weight models
Results
Non-thinking models achieve below 30% accuracy (Exact Match), with GPT-4.1 leading the group. Thinking models outperform non-thinking models substantially (e.g., Gemini-3.1-Pro reaches 51.29% Exact Match at high effort), and increased reasoning effort correlates with improved accuracy, most notably in GPT-5.4, which nearly doubles its performance with medium effort. Closed-source thinking models dominate, particularly Gemini-3, which outperforms all open-weight models even at minimal effort.
Difficulty Gradient
Model accuracy declines monotonically as question difficulty increases. Strong models lose over 20% accuracy from “Very Simple” to “Very Hard” categories, demonstrating substantial headroom for progress especially in higher complexity questions.
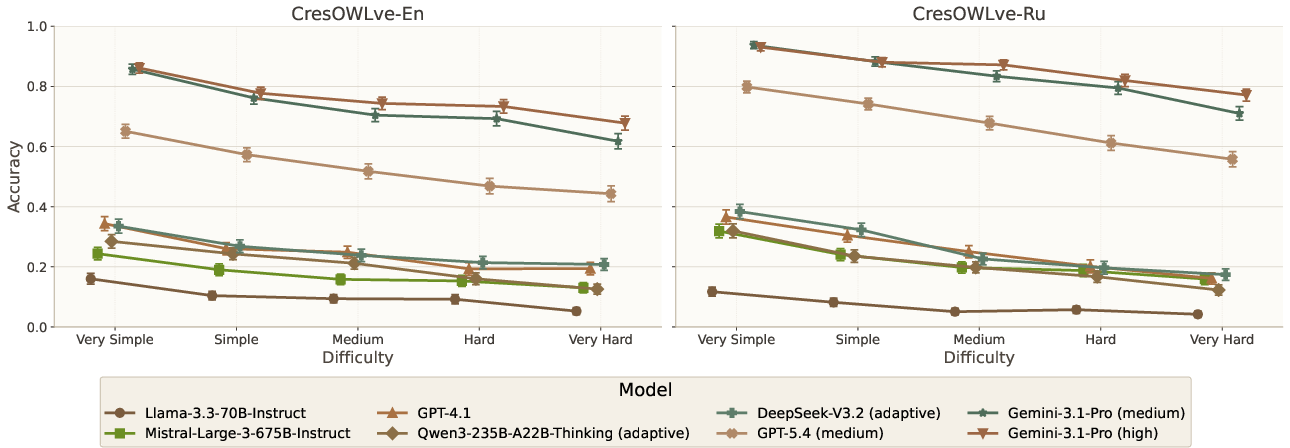
Figure 2: LLM-as-a-judge performance by difficulty level, revealing monotonically decreasing accuracy with increasing question complexity.
Domain, Creativity, and Cultural Sensitivity
Performance is largely uniform across domains and creative concept stratifications. Notable exceptions include better performance in Earth/Environmental Sciences (Qwen3, DeepSeek) and worse performance on metaphorical/poetic questions. Cultural context affects results: Gemini excels with American references, GPT-4.1 with Japanese, DeepSeek with Latin.
Creative vs. Factual Reasoning
Models consistently exhibit a substantial accuracy gap (up to -17.21%) between factual and creative questions. Even state-of-the-art thinking models show difficulty with creative synthesis, implying that problem-solving bottlenecks reside in the ability to combine knowledge, not simply retrieve it.
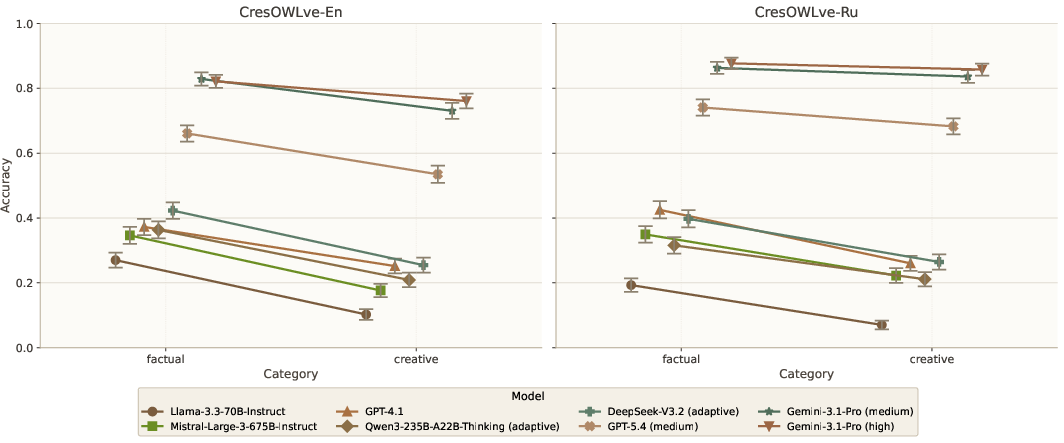
Figure 3: Model accuracy drops when shifting from factual retrieval to creative reasoning, across both English and Russian benchmarks.
Complexity Analysis
There is no significant correlation between measurable complexity features (number of domains, semantic distance, number of atomic facts) and model performance or question-assigned difficulty. This result indicates that surface complexity does not explain difficulty; the challenge lies in creative integration of heterogeneous knowledge.
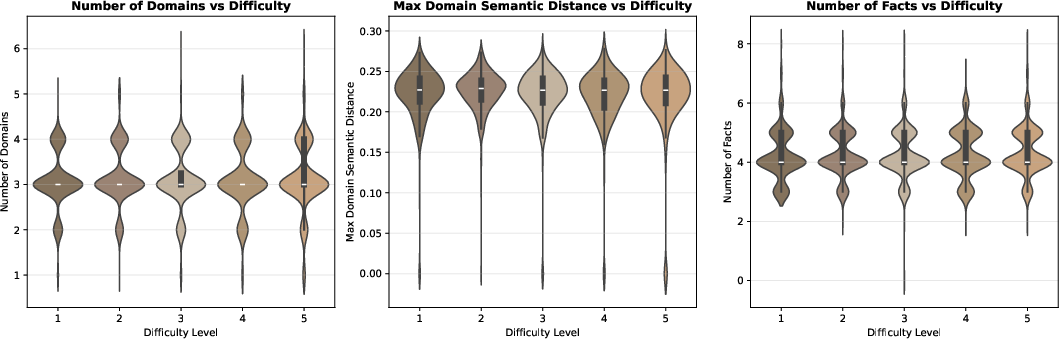
Figure 4: No significant correlation between question difficulty and complexity features (domain count, semantic distance, atomic facts).
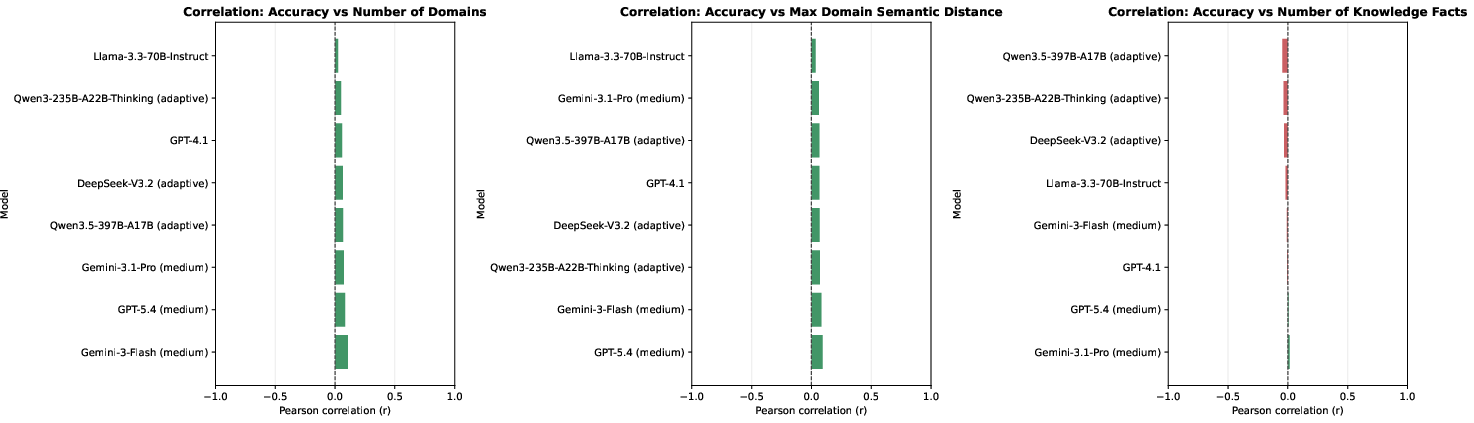
Figure 5: No significant correlation between model performance and complexity features.
Error Taxonomy
Manual analysis of Gemini-3-Flash errors reveals dominant categories:
- Missing creative connection: Failure to recognize associative or metaphorical links
- Clue misinterpretation: Correct general reasoning, but incorrect specific element selection
- Incorrect anchoring, hallucination, overthinking, wrong hypothesis/reference
Most errors involve creative connection failures, not knowledge retrieval or factual recall, further confirming the benchmark’s focus on creative integration.
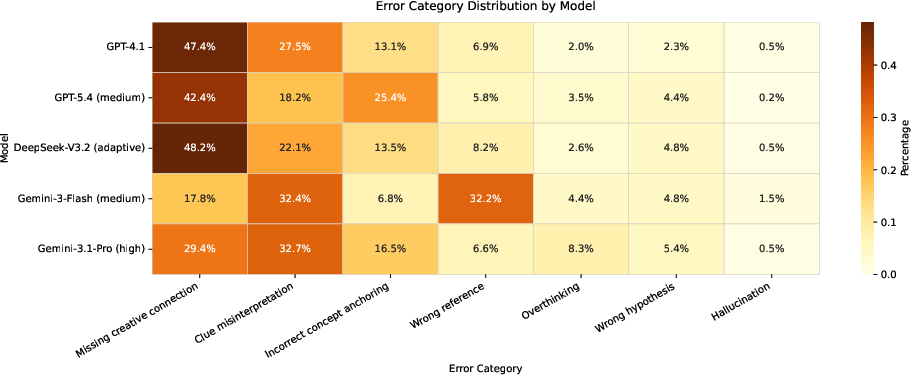
Figure 6: Distribution of error categories for top-performing models, dominated by missing creative connection and clue misinterpretation.
Implications and Future Directions
The systematic gap in creative problem-solving performance across all LLMs, especially in creative integration, exposes fundamental limitations in current model architectures and training paradigms. Despite exhaustive factual knowledge, models fail to synthesize non-obvious connections between disparate domains—a hallmark of genuine creative intelligence.
CresOWLve provides a robust testbed for evaluating and advancing creative reasoning in LLMs, highlighting the need for new approaches that go beyond brute-force retrieval and conventional stepwise inference. Techniques that enhance analogical mapping, lateral synthesis, and abstract reasoning will be essential for progress. Practical implications extend to real-world domains such as science, legal reasoning, and strategic planning, where creative insights are indispensable.
Future research should explore architectural innovations, training objectives targeting creative leaps, and integration of external symbolic reasoning modules. Multilingual and multicultural benchmarks will further interrogate cross-lingual creative reasoning, mitigating data contamination and cultural biases.
Conclusion
CresOWLve sets a new standard for evaluating creative problem-solving in LLMs, establishing the need for advanced reasoning architectures capable of integrating real-world knowledge across domains in non-obvious ways. Current models, even those employing sophisticated reasoning modes, fall short on creative synthesis, underscoring open challenges in AI. The benchmark’s multidimensional analysis and error taxonomy inform future directions in both practical LLM deployment and theoretical cognitive modeling.