- The paper introduces RoFSL, combining server learning and loss-based filtering to counter Byzantine adversaries in federated learning.
- It employs geometric median aggregation and novel filtering to maintain robust accuracy even when over 50% of clients are malicious.
- Empirical results on EMNIST and CIFAR-10 validate strong convergence and resilience under non-IID and adversarial conditions.
Robust Server Learning in Federated Learning under Byzantine Adversaries
Introduction and Motivation
The paper "Enhancing Robustness of Federated Learning via Server Learning" (2604.03226) addresses a central challenge in Federated Learning (FL): ensuring robustness against Byzantine adversaries, particularly when client data is non-IID. Traditional FL relies on aggregating decentralized client updates, but is highly vulnerable to adversarial model poisoning attacks, especially in heterogeneous distributions. Existing robust aggregation mechanisms—such as coordinate-wise median, trimmed mean, or geometric median—are constrained by the assumption that fewer than 50% of participants are malicious. The investigated approach in this work circumvents this limitation by exploiting an auxiliary server dataset for both filtering and server-local learning, leveraging geometric aggregation and novel filtering strategies to achieve strong performance even when the malicious client fraction exceeds 50%.
The paper formulates FL as minimizing the weighted sum of client losses, potentially regularized by a server-side loss f0(x) on a small, synthetic (or otherwise mismatched) dataset. The key setting considers N clients, some fraction β of which are Byzantine, with arbitrary adversarial update injection. The server possesses dataset D0 that is not necessarily aligned with the global distribution and uses it to steer aggregation through both filtering and local optimization. The principal objective is to achieve robust global convergence even in highly adversarial and non-IID circumstances.
Algorithmic Approach
The proposed algorithm, RoFSL, integrates server learning (SL), robust aggregation via geometric median, and incremental filtering.
- Aggregation: The server applies geometric median aggregation to client updates, which is optimal for up to 50% adversarial corruption but insufficient beyond this threshold. Filtering precedes aggregation to reduce the adversarial impact.
- Filtering:
- Angle-based (AF): Uses cosine similarity between a client’s update and the server gradient direction, filtering out updates deviating from the server’s honest loss landscape.
- Loss-based (LF): Adapts a loss decrease score based on the server’s model improvement, penalizing outliers and large deviations, and discarding a fixed bottom fraction of updates.
- Server Learning: After aggregation, the server executes several local optimization steps on its own dataset, regularized with a tunable weight γ, and applies norm clipping to prevent overfitting and control correction magnitude.
This process allows SL to mitigate aggregation errors induced by adversaries, forcibly injecting an "honest majority" component to the update even when client honesty is not guaranteed.
Empirical Evaluation
Extensive experiments on EMNIST and CIFAR-10 datasets (partitioned with Dirichlet non-IID splits) validate the approach:


Figure 1: Comparison of EMNIST training examples with the server's synthetic data highlights domain disparity.


Figure 2: CIFAR-10 client data versus STL-10 server examples, illustrating substantial distribution mismatch.
Filtering and server learning parameters are systematically ablated to characterize their effects under varying attack fractions. The key empirical observations are:
- Robustness with Small Server Datasets: Even with highly mismatched, synthetic server data and high malicious client fractions (β≥0.6), correct tuning of filtering (especially LF) and SL weight γ achieves strong accuracy and aggressive adversary mitigation.
- Filtering Alone Insufficient for High Malicious Fraction: Without SL, neither AF nor LF filters suffice when β>0.5, even with geometric median aggregation; accuracy drops precipitously.
- Strong Numerical Results: The algorithm maintains high test accuracy on EMNIST and CIFAR-10 for γ in [0.05,1.0] and N0 up to N1, with loss-based filtering outperforming angle-based filtering.
- Server Learning and Filtering Synergy: Combination of SL and filtering achieves robust model convergence with effective learning even when a majority of clients are adversarial—a strongly contradictory claim to the conventional wisdom of robust aggregation’s 0.5 breakdown point (cf. "honest majority" achieved with N2).
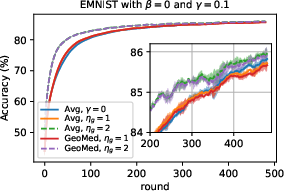
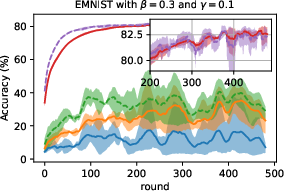
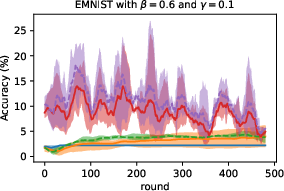
Figure 3: Average accuracy evolution on EMNIST-Dir(N3), contrasting SL hyperparameters and aggregation methods.
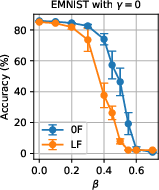
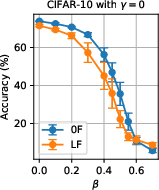
Figure 4: Sensitivity of accuracy to malicious fraction N4 with geometric median, no SL.
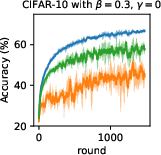
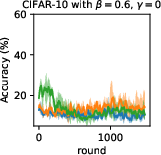
Figure 5: Test accuracy progression on CIFAR-10 with varying filter schemes in the absence of SL.
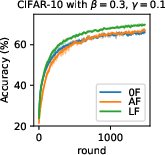
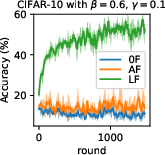
Figure 6: Influence of SL (N5) on convergence and robustness with geometric median aggregation.
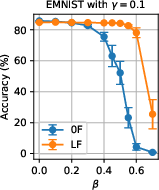
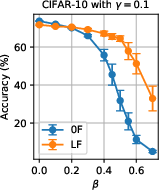
Figure 7: Robustness across malicious fractions N6 for multiple filtering and SL configurations.
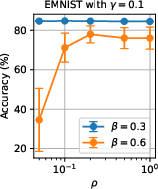
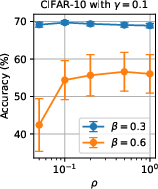
Figure 8: Effect of the loss-based filter’s parameter N7 on final accuracy.
Sensitivity analysis confirm stable performance across reasonable filter parameter settings, and the ablation of server aggregation variants further underscores the superiority of geometric median plus filtering. Distributional mismatch in server data does not substantially impair robustness gains, indicating generality.
Practical and Theoretical Implications
Practically, the demonstrated approach offers a mechanism for robust FL deployment in highly untrustworthy and heterogeneous environments, as encountered in real-world federated scenarios (e.g., mobile, IoT, or cross-silo data). The major implication is that the "honest majority" condition is no longer strictly necessary for robust aggregation; server-side learning, judicious filtering, and norm clipping can compensate for adversarial dominance. The algorithm is compatible with small, imperfect server datasets and does not require prior knowledge of adversarial fractions or distributional alignment.
Theoretically, this stands in bold contradiction to the classical robustness limit of geometric median aggregation. By combining SL as an active participant in filtering and correction, the "breakdown point" barrier is effectively bypassed. This raises considerable interest for future work on formal convergence guarantees, adaptively estimating adversarial fractions, and integrating dynamic client sampling mechanisms. Furthermore, the approach is complementary to personalization, clustering, and hybrid semi-supervised FL paradigms.
From an AI perspective, server learning could serve as a bridge for knowledge distillation, regularization, and even detection of adversarial drift. As server datasets evolve (e.g., synthetic or collected from trusted nodes), their role in distributed optimization may further expand.
Conclusion
The paper establishes that Byzantine-robust FL can be substantially improved via a synergy of server-side learning on mismatched data, robust geometric aggregation, and loss-based filtering. Notably, the method achieves high accuracy and robust convergence even when a majority of participating clients are adversarial, with only a small synthetic server dataset. The approach is practical, parameter-stable, and extensible; future development can include theoretical foundations, adaptive filtering, dynamic client selection, and integration with recent personalization and distillation frameworks.