- The paper introduces EWAD and CPDP, innovative methods that leverage token-level supervision and teacher capacity to control noise in low-resource abstractive summarization.
- The study shows that simple logit-level KD achieves near-teacher performance on short outputs while complex losses may hinder long-summary quality.
- The experiments highlight the importance of data scaling and reveal discrepancies between automatic metrics and human evaluations in summarization tasks.
Reliability-Gated Multi-Teacher Distillation for Low-Resource Abstractive Summarization: A Technical Analysis
Motivation and Problem Context
This work addresses multi-teacher knowledge distillation (KD) for abstractive summarization in low-resource settings. Large encoder-decoder models have made significant advances for sequence generation, yet their deployment faces resource constraints. Standard KD approaches are sensitive to teacher disagreement, and prior art largely ignores token-level reliability. The paper proposes and empirically dissects two main innovations: Entropy-Weighted Agreement-Aware Distillation (EWAD) and Capacity-Proportional Divergence Preservation (CPDP), which collectively form a reliability- and capacity-aware KD framework.
Framework Overview and Architectural Components
The pipeline accepts documents of variable lengths, employing length-based routing to either a multi-teacher KD branch or a MapReduce module capable of handling long documents.

Figure 1: Documents are routed by length to KD or MapReduce; three teachers provide supervision across five ablation stages.
Within the KD branch, teacher models provide supervision at both logit and pseudo-label levels. The system manages cross-architecture KD by integrating both logit-level (vocabulary-aligned) and sequence-level (tokenization-agnostic) distillation.
The standard distillation loss combines CE on gold summaries, KL divergence on soft teacher logits, and, optionally, MSE alignment of intermediate hidden states.
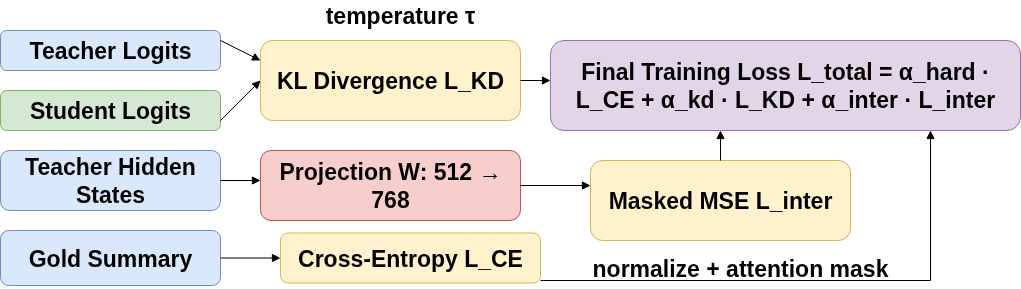
Figure 2: Standard distillation loss with three terms: softened KL divergence, projected MSE for representations, and cross-entropy to gold.
Entropy-Weighted Agreement-Aware Distillation (EWAD)
EWAD introduces dynamic, token-level supervision routing conditioned on two reliability axes: teacher confidence (normalized entropy) and inter-teacher agreement (Jensen-Shannon divergence). Specifically:
- When teachers show high confidence and strong agreement, weighted soft-label KD is prioritized.
- In cases of low agreement, the framework reverts to gold-label supervision, circumventing label noise.
Confidence is mapped via softmax to per-teacher weights; agreement is operationalized through a sigmoid-gated blending coefficient.
Capacity-Proportional Divergence Preservation (CPDP)
CPDP addresses the geometric coherence of where, in distribution space, a student should situate itself relative to heterogeneously-sized teachers. The regularization loss enforces that the student's divergence ratios reflect the teachers' mutual divergence and capacity gap, normalized by the student's output entropy. This constraint prevents the student from collapsing arbitrarily toward a single teacher or violating the intended geometric relations in KD.
Combined Training Objective
The overall loss for the student integrates both EWAD and CPDP, where EWAD governs temporal reliability (which tokens), and CPDP governs geometric regularity (where in distributional space).
Experimental Protocol
Experiments span two Bangla datasets (BTS, BanSum), the Qwen-2.5 model family, and cross-lingual adaptation to ten additional languages via mT5. Performance is benchmarked using ROUGE, BLEU, BERTScore, semantic similarity, and multi-judge LLM evaluation. An extensive set of ablations isolates the impact of each component.
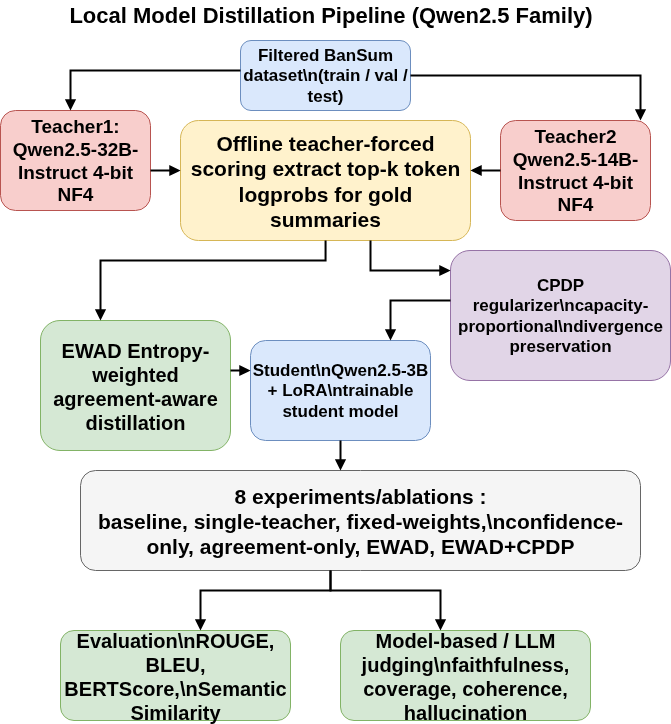
Figure 3: Dual-teacher EWAD + CPDP ablations with Qwen-2.5, systematically isolating component contributions.
Numerical Results
BanglaT5 Ablations
- On short-output datasets (BTS), logit-level KD (A2) retains 93.6% of teacher ROUGE-L and yields the highest semantic similarity among student variants. Additional regularization modestly improves semantic scores but generally depresses n-gram overlap.
- On long summaries (BanSum), further loss complexity (pseudo-labels, adaptive temperature, intermediate matching) consistently results in degraded automatic scores. Logit-level KD alone achieves 95.9% of teacher ROUGE-L, highlighting the risk of noise accumulation in extended autoregressive decoding.
Qwen-2.5 EWAD+CPDP Analysis
Direct fine-tuning of Qwen2.5-3B outperforms all distillation-based alternatives, indicating a capacity ceiling: when student and teacher quality are nearly matched, multi-teacher reliability routing introduces unnecessary variance. Both EWAD and CPDP fail to deliver positive gains in this setting.
Cross-Lingual Distillation
Offline pseudo-label KD transfers robustly to ten languages (including typologically distant ones and five scripts), achieving 71–122% teacher ROUGE-L retention at 3.2× compression. The pipeline generalizes with minimal language-specific engineering.
Data Scaling and Loss Design
Scaling training data (from 20K to 141K instances) for Qwen2.5-3B yields greater ROUGE and semantic similarity improvements than any engineered distillation loss, reinforcing the primacy of data scaling.
LLM and Human Evaluation
Multi-judge LLM evaluation reveals calibration issues: significant hallucination rate discrepancies between GPT-5.2 (0%) and Claude Sonnet 4.6 (25.5%), with human annotators generally siding with Claude. This exposes the limitation of single-LLM pipelines for summary evaluation and the value of human arbitration.
Practical and Theoretical Implications
The primary implication is that simple logit-level KD, when applied in a reliability-aware regime, offers the best trade-off in noise-robustness and compression for low-resource summarization—particularly with short outputs. EWAD and CPDP offer diagnostic tools for regimes where multi-teacher supervision is or is not beneficial, but their contribution is secondary to data scaling, especially as model expressivity increases.
The findings suggest that future advances in generative KD should focus on:
- More precise characterization and measurement of teacher reliability (beyond entropy/JSD).
- Dynamic loss schedules and length-awareness to counteract noise accumulation in long-form generation.
- Comprehensive, multi-perspective evaluation protocols involving both humans and LLMs to mitigate calibration bias in automatic scoring.
Conclusion
This study systematically dissected multi-teacher KD under reliability- and capacity-aware objectives for low-resource abstractive summarization. The experimental evidence indicates that standard logit-KD dominates, with reliability-aware extensions offering marginal improvements for short outputs and exhibiting negative returns for longer generation. EWAD and CPDP function as analytical instruments rather than universal optimizers. Strong generalization to cross-lingual transfer validates the approach’s robustness. The results emphasize the preeminent role of data scaling and the necessity for more nuanced teacher reliability diagnostics over further loss function complexity.