- The paper introduces a round-aware prompt interface and collective KV cache reuse that reduces redundant compute and memory usage in multi-agent LLM serving.
- It presents a Master-Mirror caching technique with diff-based storage that achieves up to 17× compression while preserving output fidelity.
- Experimental results demonstrate enhanced agent throughput and lower latency compared to existing systems like vLLM under fixed GPU constraints.
TokenDance: Scaling Multi-Agent LLM Serving via Collective KV Cache Sharing
Large-scale multi-agent LLM applications, notably in domains like social simulation and collaborative coding, operate by organizing execution into synchronized rounds. In each round, a central scheduler aggregates agent outputs and redistributes the context, manifesting the All-Gather communication pattern. This pattern precipitates massive redundancy in KV Caches: every agent's prompt incorporates the same shared output blocks, although their positions and order may differ due to each agent’s unique private history. Existing LLM serving systems do not efficiently exploit this redundancy, resulting in linear scaling of memory requirements with agent count. This severely restricts concurrency and scalability under fixed GPU memory budgets.
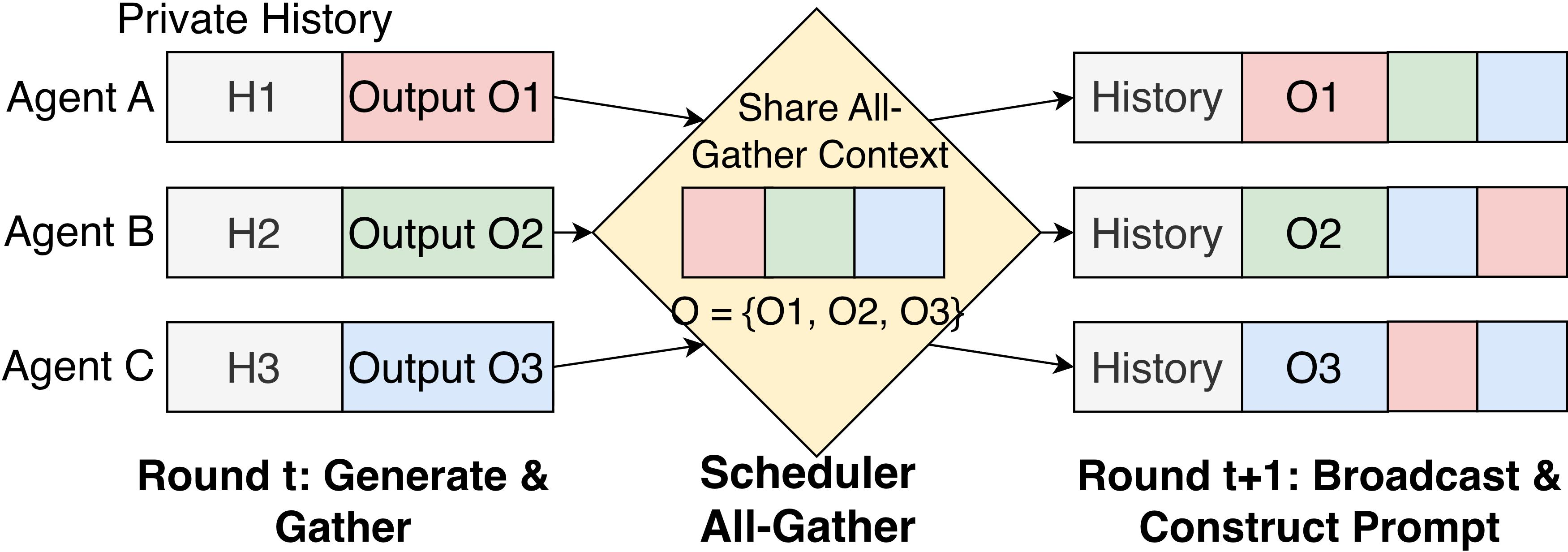
Figure 1: The All-Gather prompt structure. All agents receive the same output blocks (O), but the blocks appear at different positions because each prompt has its own private history (H) and may use a different block order. This structure arises in any multi-agent application that follows the All-Gather pattern.
TokenDance addresses two orthogonal inefficiencies in current architectures:
- Redundant reuse computation: Position-independent caching (PIC) and related methods apply block matching and positional correction per request independently, incurring multiplicative compute cost.
- Redundant KV Cache storage: After reuse, each agent still maintains an entire cache copy, although the majority of their content is identical.
System Architecture and Mechanisms
Round-Aware Prompt Interface
TokenDance introduces a round-aware prompt interface where each logical block (private history, shared output, etc.) is delimited by reserved separator tokens (e.g., <TTSEP>), rendering block boundaries explicit post-tokenization. Block-level recognition enables segment-based hashing and matching, permitting efficient identification and management of shared content irrespective of its absolute position in agent-specific prompts.
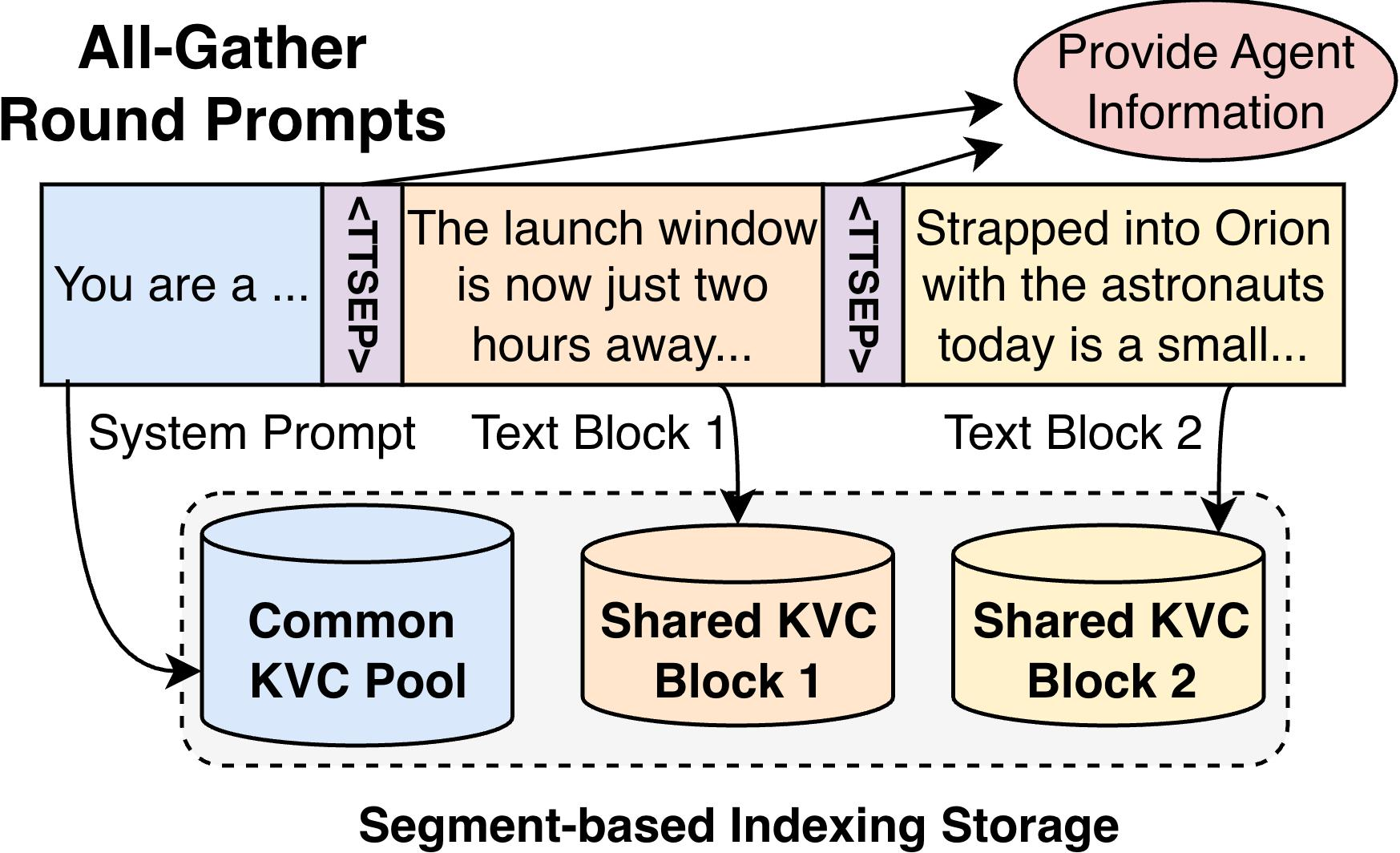
Figure 2: Example of TokenDance's round-aware prompt interface, with per-agent private history blocks and shared output blocks separated by <TTSEP> tokens.
Collective KV Cache Reuse
Traditional per-request PIC methods invoke RoPE rotation and important-position analysis for each agent, even on content-identical shared blocks—repeating computational work N times in an N-agent round. TokenDance’s KV Collector groups compatible requests (via alignment in length, visible cache span, and slot mapping), enabling collective processing:
- Shared RoPE rotation and important-position selection are executed once for the entire round.
- Only agent-specific private segments are handled individually.
- The collective reuse method is agnostic to the underlying PIC backend.
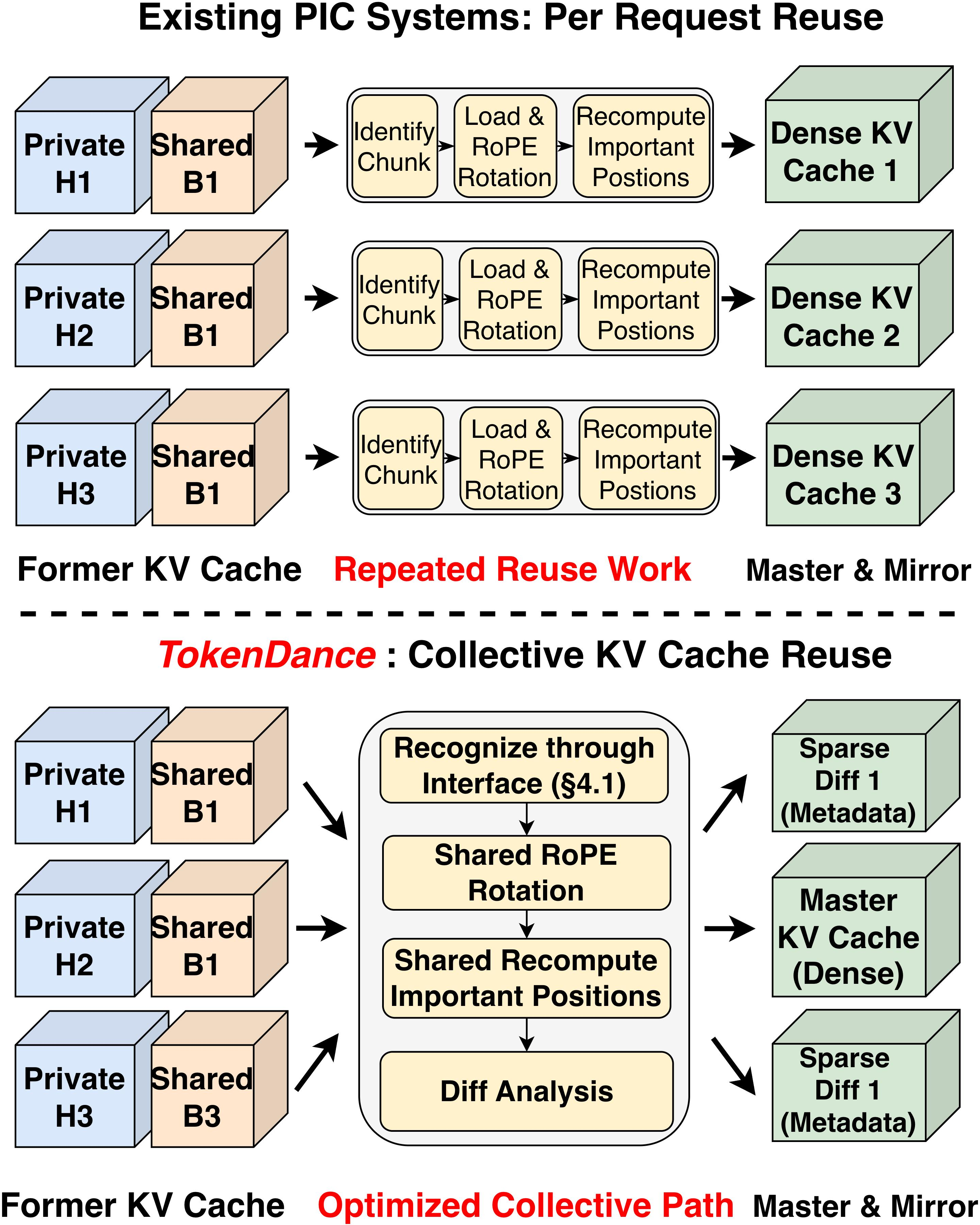
Figure 3: Per-request PIC reuse (top) vs. TokenDance’s collective reuse (bottom). TokenDance groups requests and shares RoPE/important-position selection across the group, paying reuse overhead only once per round.
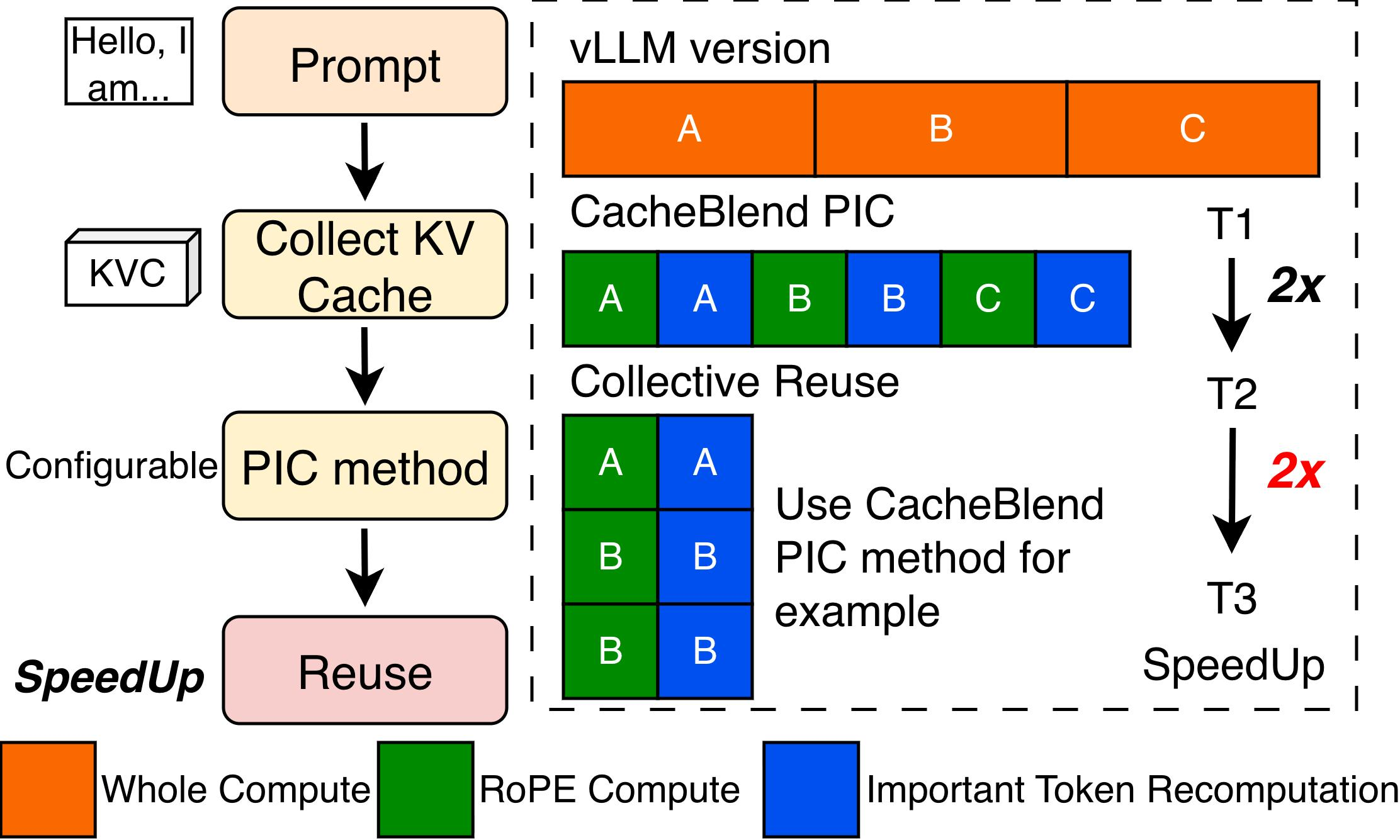
Figure 4: Collective KV Cache reuse for a three-agent All-Gather round. TokenDance shares RoPE and important-position selection tasks across the group, avoiding redundant per-request compute.
Diff-Aware Storage and Fused Restore
To compress storage, TokenDance employs a Master-Mirror layout:
- A single agent's cache (the Master) is stored densely.
- All others (Mirrors) are serialized as block-sparse differences (diffs), capturing only positions where private histories or placement cause divergence from the Master. Positions are typically clustered, supporting efficient block-sparse representation.
This design achieves $11$–17× compression, with mirrors occupying only 6%–9% of a full cache in evaluation settings.
Restoration uses Fused Diff Restore: During the cache transfer pipeline, sparse corrections are applied inline to paged memory, obviating the need for a dense intermediate buffer and minimizing critical-path latency. Block-level alignment ensures cache corrections can be integrated efficiently without degrading attention throughput.
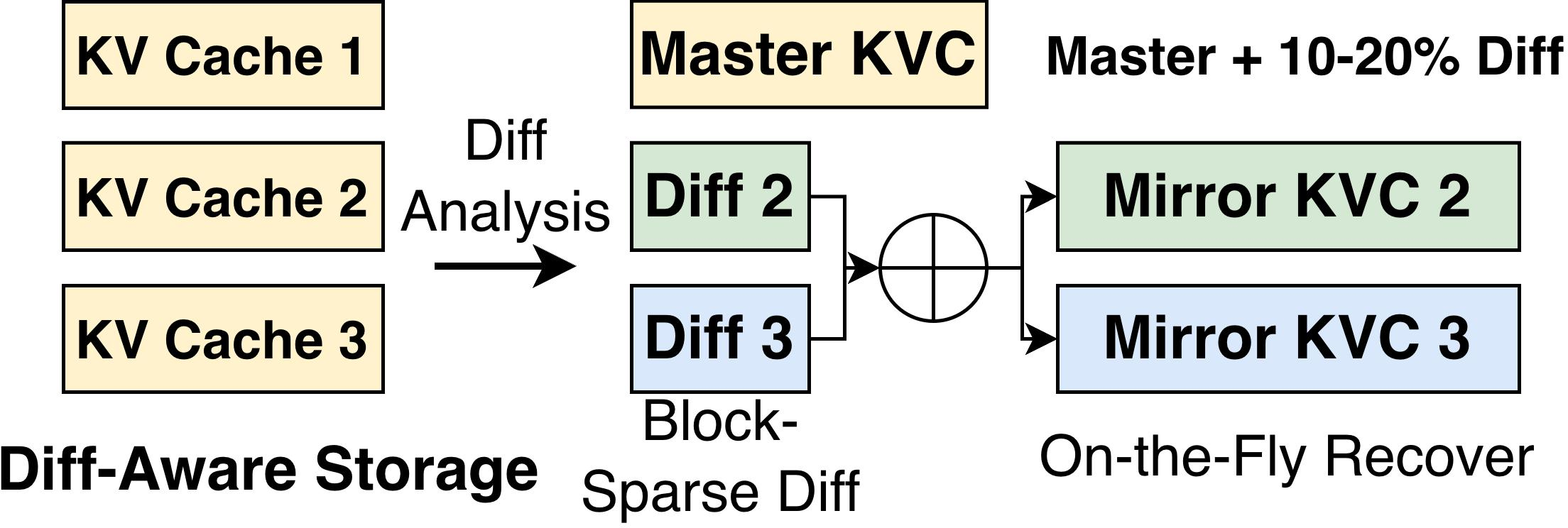
Figure 5: Diff-aware storage with the Master-Mirror layout. One Master cache is stored densely; Mirrors are represented by sparse diffs. Mirrors are reconstructed on-demand from the Master and diffs.
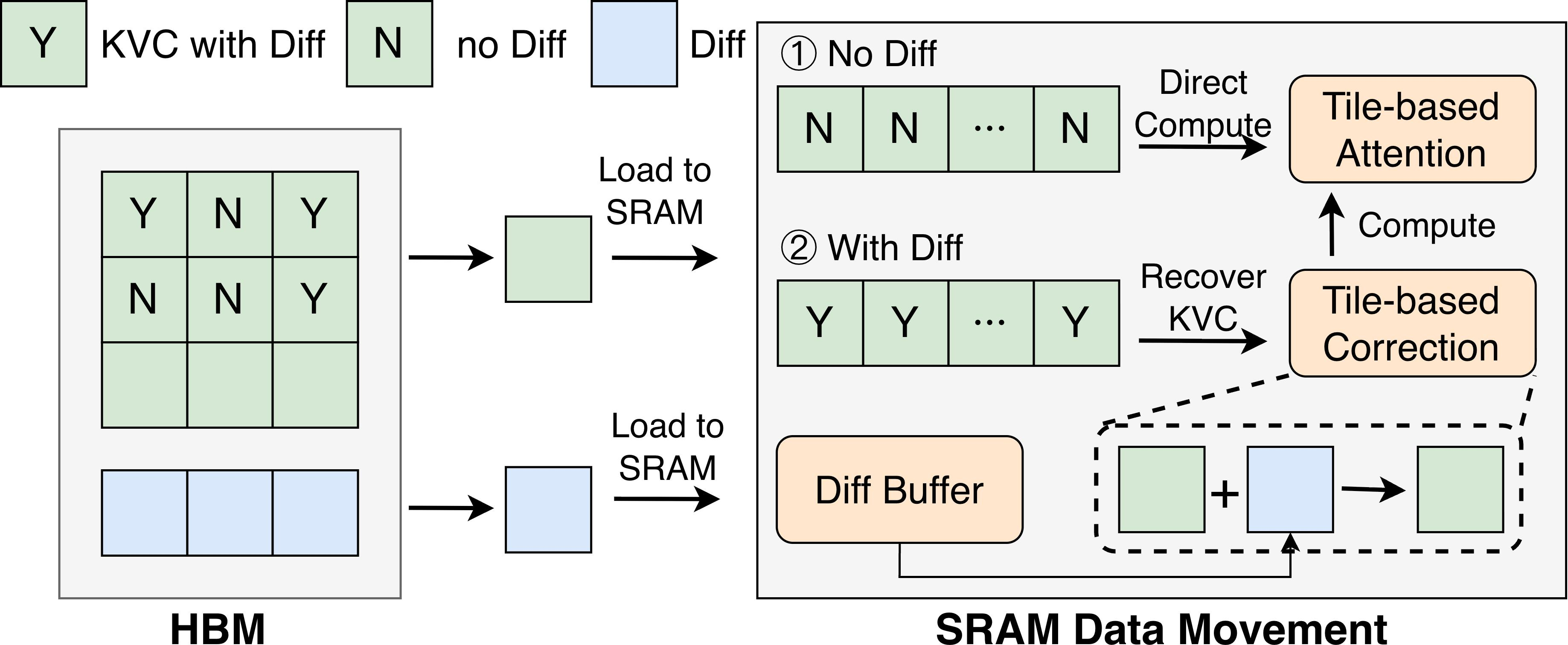
Figure 6: Fused diff restore at block granularity. Only blocks with diffs undergo correction in shared memory before attention.
Experimental Results
Scalability and Latency
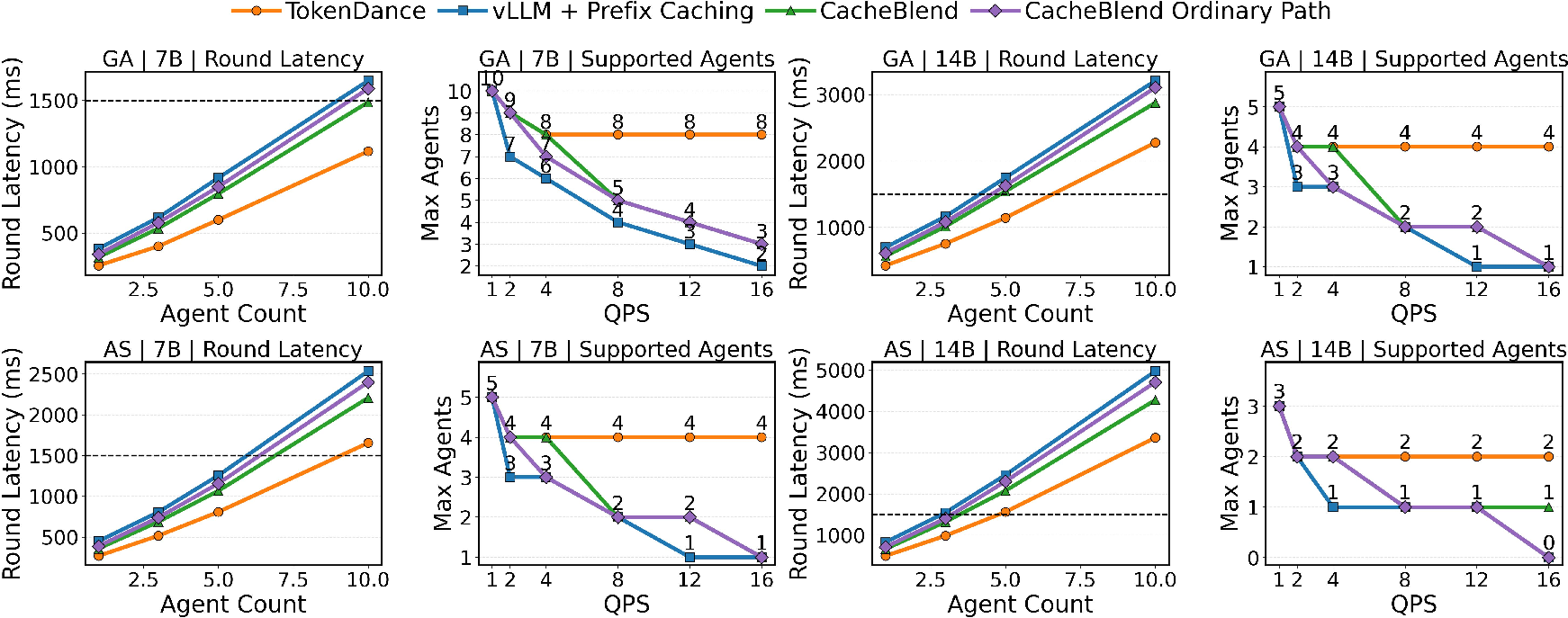
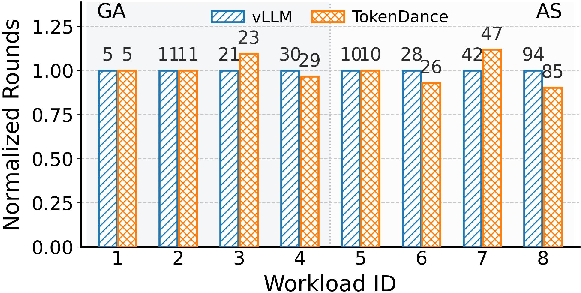
TokenDance’s principal metric of success is the number of concurrently served agents at a fixed latency or QPS SLO.
Prefill Speedup and Redundancy
- TokenDance achieves up to 1.9× prefill throughput speedup compared to per-request PIC recovery methods such as CacheBlend, with collective reuse amortizing the computational overhead across agents.
- Compression ratios for the diff-aware storage reach 17.5× on the 14B model, with most per-agent caches exhibiting only minor block-level divergence from the Master.
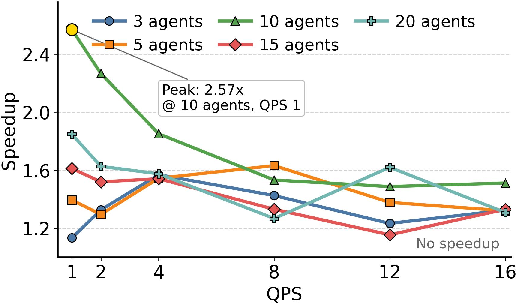
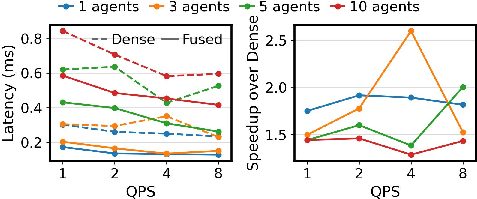
Figure 8: Collective KV Cache reuse speedup over serial PIC recovery shows consistent improvement with varying agent counts and QPS.
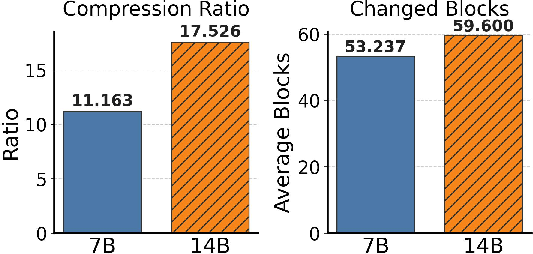
Figure 9: Redundancy characterization showing high compression ratios and modest numbers of changed blocks per Mirror.
Restore Latency
Accuracy Assessment
Implications and Future Directions
TokenDance demonstrates that communication structure (notably, the All-Gather pattern) is a valuable abstraction for system-level LLM optimization. Its architectural paradigm—collective KV Cache reuse paired with cross-cache redundancy exploitation—substantially enhances scalability and efficiency for multi-agent workloads. Practically, this allows agent-based simulations, collaborative tools, and multi-user LLM applications to accommodate significantly larger populations under fixed-memory hardware constraints.
From a theoretical perspective, the work suggests that future LLM serving systems should incorporate communication pattern awareness as a first-class system concept, generalizing beyond All-Gather to other collective and point-to-multipoint patterns as agent systems diversify. Diff-based and collective architectures are amenable to composition with further optimizations such as quantization and cross-model sharing, indicating a trajectory toward hybridized, communication-structure-aware serving stacks.
Conclusion
TokenDance presents a principled system for maximizing concurrent agent capacity in multi-agent LLM serving by exploiting collective context redundancy at both compute and memory levels. Through round-aware interfaces, collective reuse mechanisms, and diff-based cache compression with fused restoration, TokenDance delivers substantial improvements in agent scalability, operational latency, and memory efficiency without compromising output fidelity. This approach underlines the critical role of communication structure in efficient LLM serving and sets a foundation for subsequent research into broader communication-aware optimizations in AI system infrastructure.