An Open-Source LiDAR and Monocular Off-Road Autonomous Navigation Stack
Abstract: Off-road autonomous navigation demands reliable 3D perception for robust obstacle detection in challenging unstructured terrain. While LiDAR is accurate, it is costly and power-intensive. Monocular depth estimation using foundation models offers a lightweight alternative, but its integration into outdoor navigation stacks remains underexplored. We present an open-source off-road navigation stack supporting both LiDAR and monocular 3D perception without task-specific training. For the monocular setup, we combine zero-shot depth prediction (Depth Anything V2) with metric depth rescaling using sparse SLAM measurements (VINS-Mono). Two key enhancements improve robustness: edge-masking to reduce obstacle hallucination and temporal smoothing to mitigate the impact of SLAM instability. The resulting point cloud is used to generate a robot-centric 2.5D elevation map for costmap-based planning. Evaluated in photorealistic simulations (Isaac Sim) and real-world unstructured environments, the monocular configuration matches high-resolution LiDAR performance in most scenarios, demonstrating that foundation-model-based monocular depth estimation is a viable LiDAR alternative for robust off-road navigation. By open-sourcing the navigation stack and the simulation environment, we provide a complete pipeline for off-road navigation as well as a reproducible benchmark. Code available at https://github.com/LARIAD/Offroad-Nav.







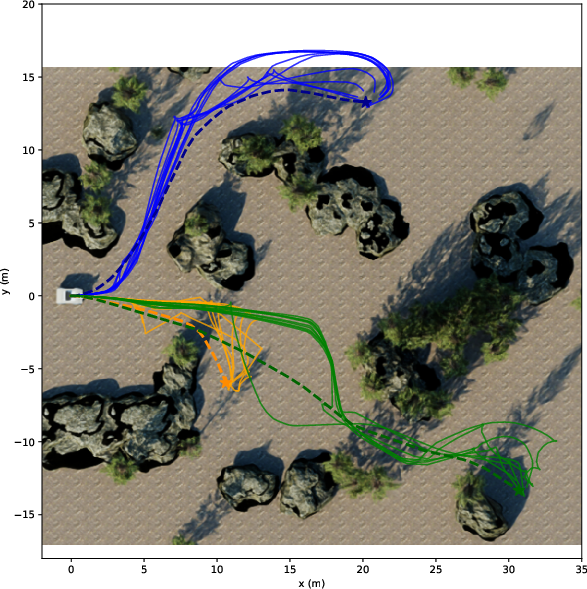
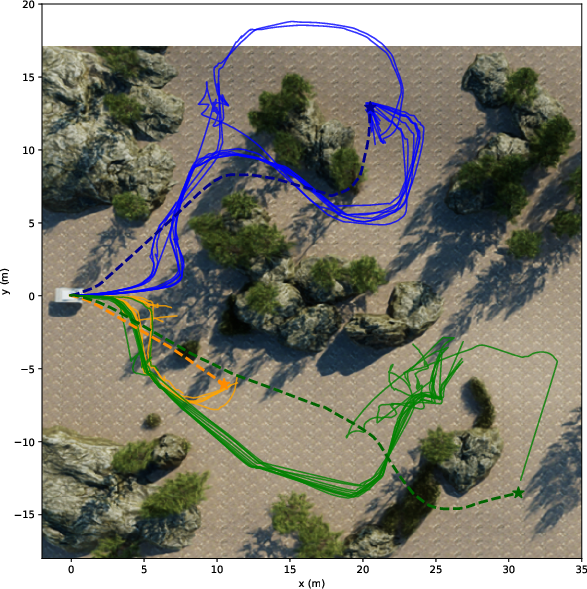
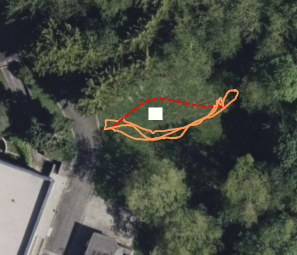
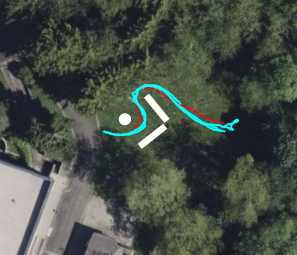

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows how to make a small off‑road robot drive itself around using either:
- a laser scanner (LiDAR), or
- a single regular camera (“monocular”)
The clever part is that the camera version doesn’t need extra training for each new place. The authors combine a big, pre‑trained AI model that guesses depth from a single photo with some smart tricks so the robot can “see” the 3D world well enough to avoid obstacles. They release all the code and a realistic simulator so others can try it.
What were the main goals?
The team wanted to:
- Build a complete, ready‑to‑use navigation system for rough outdoor terrain.
- Make it work with either LiDAR or just one camera, without training on new data.
- Fix common camera‑depth problems (like “fake” obstacles and jumpy measurements) so it’s reliable outdoors.
- Share the whole system and test worlds openly so people can repeat and compare results.
How does their system work?
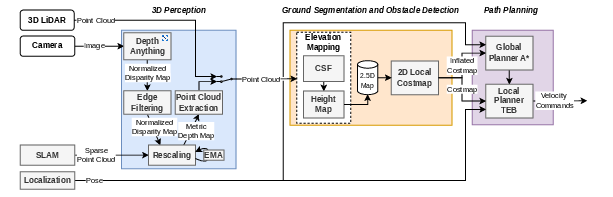
Think of the robot as a careful hiker: it looks around, builds a mental map, and plans a safe path. The system has three main parts.
1) Seeing the 3D world (Perception)
Two options:
- LiDAR: A device that spins and shoots laser beams, measuring how far things are. It’s very accurate but expensive and uses more power.
- One camera: Like seeing with one eye. A large AI model called Depth Anything V2 looks at a single image and estimates how far each pixel is. This is fast to set up (no extra training), but raw results can be messy.
To make camera depth usable:
- Metric rescaling: The AI’s depth is “relative,” not in real meters. The robot also runs a SLAM system (VINS‑Mono), which tracks a few points in 3D as it moves. It uses these “known” points to convert the AI’s depth into real‑world meters—like using a ruler in the scene to set the scale.
- Edge masking: Depth edges can be blurry, which can create “phantom” obstacles when turned into 3D. The system detects strong depth edges and ignores a thin band of pixels around them, cutting down on fake obstacles.
- Temporal smoothing: Sometimes the scale jumps around from frame to frame. The system averages the scale over time so the depth stays steady.
Result: a clean 3D point cloud (a big set of dots in space) showing ground and obstacles.
2) Building a map of safe vs. risky areas
- Ground vs. obstacles: They use a “cloth simulation filter” (CSF). Imagine flipping the world upside down and draping a tight sheet over it. Where the sheet touches is the ground; anything sticking out is an obstacle. This helps on uneven terrain.
- Elevation map (2.5D): The robot keeps a grid around itself that stores the height of obstacles. It also remembers obstacles for a while as it moves, so they don’t instantly disappear when out of view.
- Costmap: The height map is turned into a simple “cost” map of what’s safe to drive on and what to avoid.
3) Planning a path and moving
- Global path: An A* planner finds a route through the costmap.
- Local path: A Timed‑Elastic‑Band (TEB) planner refines the path in real time, adjusting smoothly around obstacles.
- Positioning: The robot’s location is estimated by fusing GPS, IMU (motion sensors), and SLAM using a Kalman filter—basically averaging trusted sources to stay on track.
How did they test it?
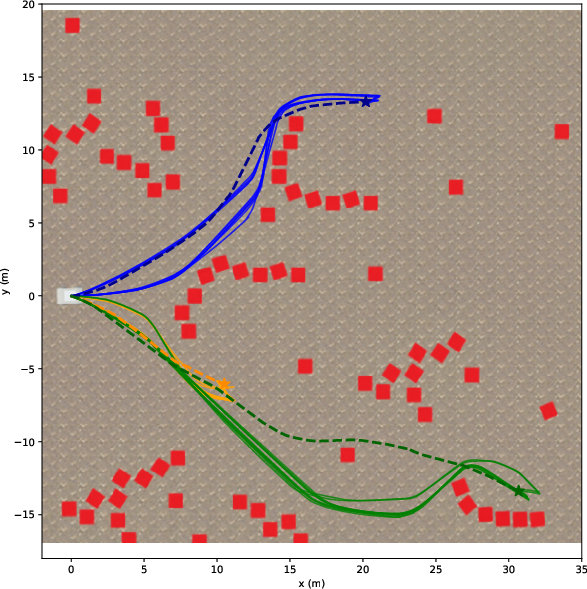
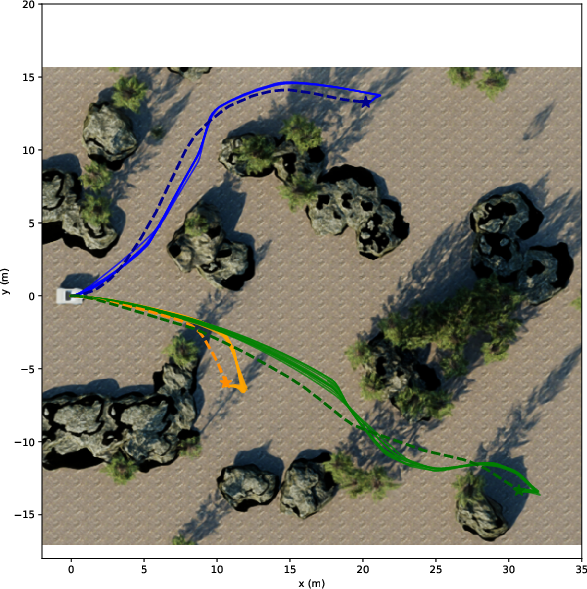
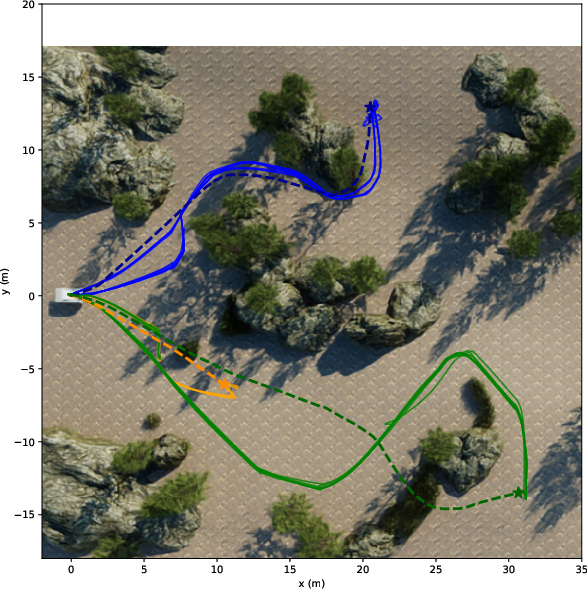
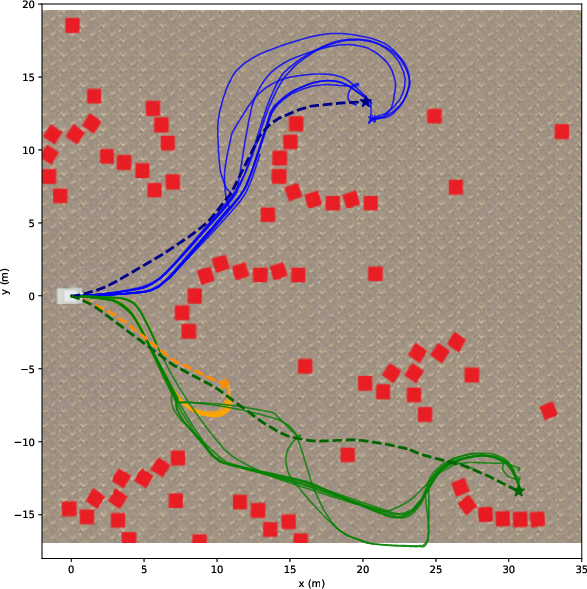
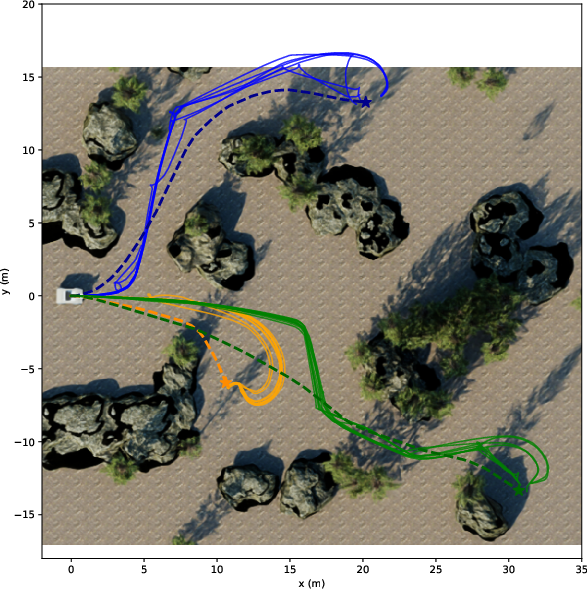
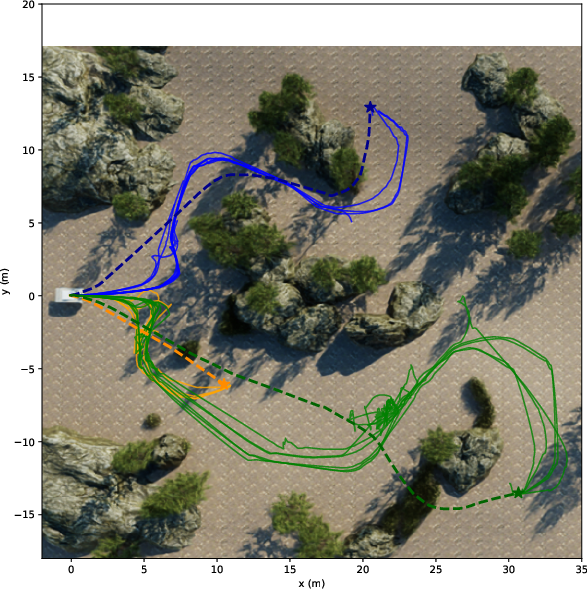
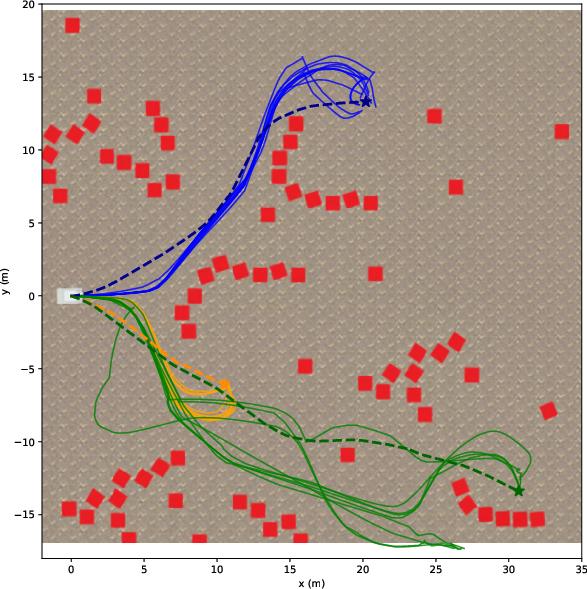
They tried both LiDAR and camera setups in:
- Photorealistic simulations (NVIDIA Isaac Sim) with three difficulty levels:
- Easy: flat ground, simple blocks.
- Medium: realistic trees and rocks.
- Hard: slopes and tall grass.
- Real outdoor tests with a wheeled robot (Barakuda) across easy, medium, and hard courses.
They measured:
- Success Rate: Did the robot reach the goal?
- Path Efficiency (SPL): How close was the path length to a good reference path?
- Distance Ratio: How far toward the goal it progressed, even if it didn’t finish.
What did they find, and why is it important?
Main takeaways:
- The camera‑only system worked nearly as well as a high‑end LiDAR in most tests.
- In real outdoor runs, both LiDAR and camera reached all goals. The camera routes were usually a bit longer and sometimes less smooth (slower processing and a narrower view can make the robot react later).
- The camera struggled with tall, fuzzy objects like high grass in the hardest simulation. Blurry edges and fine vegetation can still confuse depth, even with edge masking.
- Their two camera fixes—edge masking and temporal smoothing—improved reliability and efficiency compared to not using them.
- The camera approach uses much less power and is far cheaper than LiDAR, which is great for small or low‑cost robots.
Why this matters:
- Cheaper, lower‑power robots can navigate rough outdoor places (farms, parks, trails) without expensive sensors.
- No need to retrain models for each new robot or location: it works “out of the box” using a foundation model.
- Open code and open simulations mean others can build on this, compare fairly, and improve it.
What’s next?
The authors suggest:
- Teaching the system to recognize “soft” obstacles like tall grass as drive‑through, not solid walls (traversability learning).
- Handling “negative obstacles” (like holes or ditches) that are hard to see because they’re missing, not sticking out.
- Porting the stack to ROS2 for longer‑term support and easier adoption.
Overall, this work shows that a single camera plus smart software can be a strong stand‑in for LiDAR in off‑road navigation, making autonomous robots more affordable and accessible. The full stack and simulator are open‑source at: https://github.com/LARIAD/Offroad-Nav
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves missing, uncertain, or unexplored, to guide future research.
- Robustness of metric depth rescaling to SLAM quality: How does performance degrade with sparse-depth density, outlier rate, or scale drift from different SLAM systems (e.g., VINS-Mono vs. ORB-SLAM3) under texture-poor terrain, motion blur, rolling shutter, or dynamic scenes?
- Simulation–real gap in sparse depth: In simulation, rescaling relies on Shi–Tomasi features with ground-truth depth (STCD-only), not an actual SLAM; how representative is this of real-world conditions, and how does performance change with realistic simulated SLAM noise and failure modes?
- Temporal smoothing trade-offs: The exponential moving average for scale/shift (α=0.8) lacks sensitivity analysis—what are the latency/stability trade-offs, and how should α be adapted to scene dynamics to avoid delayed reactions or oscillations?
- Edge-masking heuristic generality: Sobel-based edge removal with a fixed five-pixel band lacks adaptivity; how to auto-tune mask width to image resolution/FOV/depth range and reduce removal of thin, safety-relevant obstacles (e.g., poles, wires)?
- Failure cases with vegetative obstacles: High grass causes persistent “phantom obstacles” due to blurred boundaries; what perception modules (e.g., semantic traversability, depth confidence weighting, multi-scale edge detection) best distinguish soft/traversable vegetation from rigid obstacles?
- Depth model and rescaling alternatives: No comparison across monocular depth models (e.g., UniDepth, Metric3D, Marigold-DC) or between rescaling vs. zero-shot metric depth vs. depth completion; which combination offers best off-road robustness vs. compute?
- Uncertainty-aware mapping: The pipeline treats depth deterministically; how to incorporate depth confidence/uncertainty into elevation maps and planning to reduce risk from hallucinations and spurious points?
- CSF parameter sensitivity and online adaptation: Ground segmentation via CSF requires environment-specific parameters; can parameters be self-tuned online, or should alternative ground filters be used that are more robust to noisy camera-derived point clouds?
- Representation limits of 2.5D elevation maps: Overhangs, tunnels, and multi-level structures cannot be represented; how to extend to 3D voxel maps or layered elevation with minimal compute overhead on embedded hardware?
- Negative obstacles (drop-offs, ditches): Not handled; what sensing/planning strategies (e.g., raycasting, stereo add-on, monocular cues, risk-sensitive planning) enable reliable detection and safe behavior around depressions?
- Traversability beyond height thresholding: A fixed 30 cm height threshold ignores slope, roughness, deformability, and robot-terrain interaction; how to integrate terrain features (slope/roughness/friction) and robot-specific capabilities into the costmap?
- Latency and control stability: The monocular pipeline reduces module frequencies (e.g., elevation mapping at ~6 Hz), causing late turns; what are acceptable end-to-end latency budgets for stable control, and which asynchronous scheduling or pipelining strategies mitigate delays?
- Compute footprint and deployment envelope: No measurements of power, thermal throttling, or behavior on lower-power platforms; how to meet real-time constraints on smaller GPUs/CPUs, and what are the runtime/energy trade-offs?
- Multi-GPU or heterogeneous acceleration: Authors suggest multi-GPU as a future improvement but do not implement it; what is the achievable throughput with model parallelism, DLA offloading, or network distillation/quantization?
- Field-of-view limitations: A single forward monocular camera reduces anticipatory planning; how much do multi-camera panoramas, fisheye lenses, or camera placement/height affect success rate and SPL in cluttered off-road scenes?
- Sensor fusion opportunities: The stack supports either LiDAR or monocular camera, not fused; can lightweight fusion (e.g., sparse LiDAR+mono depth) or radar augment robustness in vegetation, dust, fog, and glare?
- Dynamic obstacles and motion prediction: Evaluation focuses on static scenes; how does the pipeline handle moving agents, and what modules (tracking, dynamic-costmaps, predictive TEB) are needed for safe avoidance?
- Localization robustness in GNSS-denied settings: Real-world tests used GNSS+IMU+SLAM; how does the system perform under GNSS outages (e.g., forests), degraded IMU, or camera occlusion, and what fallback strategies exist?
- Map staleness and memory policies: The elevation map keeps obstacles until updated; what aging/visibility reasoning prevents stale obstacles from blocking paths when the environment changes?
- Planner sensitivity and auto-tuning: TEB and CSF parameters are hand-tuned and cause aborts in hard cases; can automatic parameter tuning or online adaptation (e.g., learning-based weights, constraint relaxation) reduce failure rates?
- Costmap inflation and discretization effects: No analysis of grid resolution/inflation parameters on narrow-gap traversals and false blockages, especially with blurred/uncertain obstacles (e.g., high grass); what settings optimize safety vs. passability?
- Safety layer and fail-safes: No discussion of emergency braking, watchdogs for perception dropouts, or conservative fallback behaviors when depth becomes unreliable or SLAM fails.
- Calibration and drift: The impact of camera intrinsics/extrinsics errors and time synchronization on metric depth accuracy is not quantified; how sensitive is navigation to small calibration or timestamp offsets?
- Benchmark breadth and statistical power: Real-world evaluation uses only 3 runs per scenario and a single robot/domain; broader datasets, varied lighting/weather (night, rain, fog, dust), and more repetitions are needed for statistically robust conclusions.
- Standardized comparisons: Aside from internal configurations, no baseline comparisons against stereo depth, learning-based traversability stacks, or other open-source pipelines; creating side-by-side benchmarks would clarify benefits and trade-offs.
- ROS2 migration and maintainability: The current ROS1 implementation hinders adoption; beyond porting, what architectural refactors (component lifecycles, DDS tuning) are needed to ensure determinism and high-rate operation?
- Formal failure analysis: Abort cases (e.g., in high grass) lack quantified causes (perception vs. mapping vs. planning); a systematic attribution framework would guide targeted improvements.
- Dataset/benchmark annotations: The released environments lack labeled traversability/obstacle ground truth for real-world runs; providing annotations would enable finer-grained evaluation (precision/recall of obstacles, depth error vs. distance, edge-mask efficacy).
- Safety implications of edge filtering: Masking edges can suppress small or thin obstacles; what safeguards (e.g., conservative dilation, confidence thresholds) ensure that safety-critical obstacles are not removed?
- Confidence-driven outlier rejection: The point cloud generation lacks a learned or probabilistic outlier filter; can depth confidence maps or geometric consistency checks reduce phantom obstacles without masking large regions?
- Camera contamination and adverse conditions: No experiments under lens dirt, water droplets, glare, or low light; what robustness measures (defogging, auto-exposure control, HDR, active illumination) are required for field deployment?
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can leverage the paper’s open-source stack, methods, and benchmarks today.
- Low-cost off-road UGV autonomy without LiDAR
- Sector: agriculture, forestry, energy utilities (solar/wind farm inspection), construction, environmental monitoring, public safety
- What: Replace or augment LiDAR with a monocular camera for 3D perception and obstacle avoidance using the paper’s Depth Anything V2 + VINS-Mono rescaling, edge masking, and temporal smoothing, feeding CSF-based elevation mapping and costmap planning (A* + TEB).
- Benefits: Significant bill-of-materials and power savings (≈20W for LiDAR vs ≈2W for cameras), lower detectability in sensitive operations.
- Tools/workflow: ROS1 stack (Offroad-Nav), Isaac Sim scenarios for rapid validation, Jetson AGX Orin or x86+GPU deployment, on-robot tuning of CSF and TEB.
- Assumptions/dependencies: Good camera–IMU calibration; visual feature-rich scenes for VINS-Mono; GNSS/IMU fusion available; compute headroom for Depth Anything V2 (≈10 Hz on Jetson Orin); parameter tuning for CSF/TEB; limited robustness to high grass and negative obstacles.
- Retrofit of existing ground robots to reduce energy and cost
- Sector: robotics OEMs, integrators, defense/security
- What: Swap high-power LiDAR for monocular perception where mission risk and environment allow (e.g., patrol, perimeter inspection, stealthy reconnaissance).
- Tools/workflow: Drop-in ROS1 node integration; side-by-side A/B testing using provided metrics (SR/SPL/DR).
- Assumptions/dependencies: Equivalent field-of-view to maintain coverage; lighting conditions suitable for monocular vision; retraining not required but parameter tuning is.
- Rapid prototyping and trade-off evaluation between LiDAR and vision-only stacks
- Sector: industry R&D, academia, procurement
- What: Use the open-source Isaac Sim environments and metrics to benchmark power, cost, and performance trade-offs when selecting sensors and compute.
- Tools/workflow: Provided simulation assets and reference trajectories; batch evaluation across easy/medium/hard terrains and 10/20/30 m goals.
- Assumptions/dependencies: Simulation-to-real gap; STCD-based reference-depth stand-in used in sim (note: in sim, VINS feature tracking is unreliable); care in interpreting sim-only results.
- Education and training in off-road autonomy
- Sector: academia, vocational programs, robotics bootcamps
- What: Course modules/labs on off-road navigation that cover monocular depth estimation, SLAM-aided depth rescaling, ground segmentation via CSF, and local/global planning.
- Tools/workflow: Reproducible stack and benchmark; ROS bag replays; parameter sensitivity exercises (CSF rigidity, TEB costs).
- Assumptions/dependencies: ROS1 familiarity; GPU access for Depth Anything V2; basic GNSS/IMU for localization exercises.
- Teleoperation assistance with on-board perception and costmaps
- Sector: public safety, mining, construction, utilities
- What: Use the monocular-derived elevation map and costmap to provide operator overlays (risk-aware teleop with persistent obstacle memory).
- Tools/workflow: Run the 2.5D elevation mapping and costmap in parallel to teleop; display via RViz or custom UI; persist obstacles via map memory buffer.
- Assumptions/dependencies: Adequate camera viewpoint; compute budget for simultaneous inference and mapping.
- Open-source benchmarking for perception and planning components
- Sector: software and robotics research
- What: Swap in alternative monocular depth models, SLAM backends, ground filters, and local planners and compare fairly using the released metrics and scenarios.
- Tools/workflow: Plug-and-play modules in ROS1; Isaac Sim maps; SR/SPL/DR reporting templates.
- Assumptions/dependencies: Consistent calibration and coordinate frames; rigorous baselining; compute constraints comparable across variants.
- Energy-optimized long-duration missions
- Sector: environmental monitoring, agriculture, conservation
- What: Extend mission time by replacing LiDAR with camera-based perception on battery-limited platforms.
- Tools/workflow: Power budgeting with module frequencies (3D perception 10 Hz, elevation mapping 6 Hz in Mono); mission planning optimizing compute duty cycles.
- Assumptions/dependencies: Acceptable navigation performance with reduced sensor power; daylight or assisted lighting.
- Stealthy operations where active sensors are undesirable
- Sector: defense, wildlife monitoring, anti-poaching
- What: Camera-only navigation to minimize active emissions and sensor detectability.
- Tools/workflow: Monocular pipeline with tuned edge masking to reduce hallucinated obstacles; conservative TEB inflation for safety.
- Assumptions/dependencies: Visual conditions adequate for depth inference; constraints in dense vegetation remain.
Long-Term Applications
These opportunities require additional research, scaling, or engineering maturation.
- Robust traversability in dense vegetation and deformable terrain
- Sector: agriculture, forestry, planetary exploration, construction
- What: Integrate semantic traversability modules to classify high grass vs solid obstacles, improving passability decisions and path quality.
- Potential tools/products: Vision-language or segmentation foundation models fused with monocular depth; learned traversability cost layers; adaptive CSF parameters.
- Assumptions/dependencies: Additional sensor training or zero-shot semantics; real-time performance on embedded hardware; robust data for edge cases.
- Negative obstacle detection (ditches, holes, drop-offs)
- Sector: mining, construction, defense, safety-critical robotics
- What: Extend the stack to detect and plan around terrain depressions without explicit returns.
- Potential tools/products: Multi-view depth fusion, temporal height consistency checks, complementary sensing (stereo, radar, lightweight depth).
- Assumptions/dependencies: Enhanced perception beyond monocular depth; careful false-negative mitigation for safety certification.
- ROS2, safety, and reliability-grade releases
- Sector: industrial robotics, OEMs
- What: Migrate to ROS2 for long-term maintainability, real-time QoS, and ecosystem adoption; pursue functional safety pathways for certain use cases.
- Potential products: ROS2 packages, Docker images, CI-tested releases; diagnostics and failover modules; watchdogs for SLAM/perception health.
- Assumptions/dependencies: Engineering resources for migration; certification processes; integration with standardized sensor drivers.
- Heterogeneous compute optimization and multi-GPU scaling
- Sector: embedded AI, autonomy platforms
- What: Improve runtime by distributing Depth Anything V2 and elevation mapping across GPU/DLA/CPU; pipeline parallelism; model distillation.
- Potential tools/products: TensorRT pipelines with operator placement; distilled depth models; HALO schedulers for Jetson.
- Assumptions/dependencies: Maintained accuracy at higher FPS; hardware availability; thermal and power envelopes.
- Sensor fusion variants for harsher conditions
- Sector: defense, all-weather operations, autonomous maintenance
- What: Fuse monocular depth with low-power 2D LiDAR or radar to handle adverse lighting, dust, rain, or texture-poor scenes.
- Potential tools/products: Lightweight radar cost layers; probabilistic costmap fusion; adaptive sensor weighting based on confidence.
- Assumptions/dependencies: Additional hardware; calibration and synchronization; fusion algorithm development.
- Scaled deployment in multi-robot fleets
- Sector: agriculture, utilities, environmental monitoring
- What: Centralized monitoring and map sharing for numerous camera-only UGVs; cost-effective fleet operations over large off-road sites.
- Potential tools/products: Fleet management software; map-merging for 2.5D elevation layers; edge-cloud offloading for heavy inference.
- Assumptions/dependencies: Robust comms; synchronization and localization consistency; cloud security.
- Policy and standards for vision-first off-road autonomy
- Sector: regulators, public agencies, insurers
- What: Define test protocols, benchmarks, and acceptance criteria for camera-only off-road robots using reproducible, open simulation suites.
- Potential tools/products: Standardized evaluation harnesses; SR/SPL/DR adoptees; procurement templates emphasizing cost/energy trade-offs.
- Assumptions/dependencies: Multi-stakeholder engagement; traceability and documentation; alignment with safety frameworks.
- Cross-domain extensions: legged robots, micro-rovers, and drones near-ground operations
- Sector: legged robotics, research, exploration
- What: Adapt monocular depth rescaling and edge masking to locomotion planners or near-ground aerial inspection where LiDAR is impractical.
- Potential tools/products: Interfaces to elevation mapping for foothold planners; specialized edge filters for thin structures; lighter models for NPUs.
- Assumptions/dependencies: Different dynamics and planner requirements; control loop latency budgets; re-tuning of CSF and TEB analogs.
- Data generation and self-supervised learning pipelines
- Sector: autonomy R&D, academia
- What: Use the stack to generate aligned image–depth–elevation datasets for self-supervised depth/traversability research in off-road settings.
- Potential tools/products: Logging and labeling tools; benchmark leaderboards; synthetic-to-real domain adaptation workflows.
- Assumptions/dependencies: Data quality controls; consistent calibration; privacy/usage compliance.
- Commercial products: camera-first off-road nav kits
- Sector: robotics OEMs, integrators
- What: Turn the stack into a productized module—sensor, compute, and software bundle—for small to mid-size UGVs in rugged terrain.
- Potential tools/products: Ruggedized camera + IMU kit; pre-tuned CSF/TEB profiles by terrain class; support contracts; cloud analytics.
- Assumptions/dependencies: Support and maintenance; clear performance envelopes (terrain/lighting); upgrade path to ROS2.
These applications hinge on key dependencies observed in the paper: the efficacy of Depth Anything V2 for zero-shot depth; reliable sparse depth from VINS-Mono; proper calibration and parameter tuning; sufficient compute (especially GPU); and acknowledged limitations around high grass, negative obstacles, and execution frequency on embedded platforms.
Glossary
- 2.5D elevation map: A height-coded grid representation of terrain where each cell stores a single elevation value relative to the robot; "The resulting point cloud is used to generate a robot-centric 2.5D elevation map for costmap-based planning."
- Back-projection: The process of projecting depth image pixels into 3D space to form points; "the 3D back-projection of the depth map may result in an environment containing large phantom obstacles that may block the robot."
- Cloth Simulation Filter (CSF): A ground-segmentation algorithm that simulates a cloth draped over an inverted point cloud to separate ground from obstacles; "a cloth simulation filter (CSF)~\cite{zhang2016CSF} is applied in order to segment the ground from the positive obstacles."
- Costmap: A grid where cells encode traversal cost or obstacles for planning paths; "converted into a costmap used for path planning and generating the robot commands."
- Depth Anything V2: A foundation-model-based monocular depth estimator used without task-specific training; "For the monocular setup, we combine zero-shot depth prediction (Depth Anything V2) with metric depth rescaling using sparse SLAM measurements (VINS-Mono)."
- Depth completion (zero-shot): Inferring a dense metric depth map by fusing an image with sparse depth inputs without task-specific training; "Zero-shot depth completion methods~\cite{viola2024marigolddc, lin2025prompting} fuse an input image with sparse depth measurements to generate a metric depth map."
- Depth rescaling: Recovering metric depth by estimating global scale and shift for normalized monocular depth predictions; "Depth rescaling techniques~\cite{marsal2025simple, guo2025monocular} estimate scaling and shift parameters to recover metric depth from normalized predictions produced by zero-shot monocular foundation models."
- Disparity map: An image where pixel values encode relative disparity (inverse depth) used by stereo/monocular models; "We apply a Sobel filter to the disparity map returned by the depth estimation model so as to only detect edges caused by depth discontinuities, especially those due to close objects."
- Edge-masking: Postprocessing that removes pixels near depth discontinuities to avoid false obstacles; "Two key enhancements improve robustness: edge-masking to reduce obstacle hallucination and temporal smoothing to mitigate the impact of SLAM instability."
- Exponential moving average: A recursive smoothing technique that weights recent estimates more heavily; "we smooth these parameters with the ones obtained at previous rescaling iteration using an exponential moving average:"
- Extended Kalman filter (EKF): A nonlinear state estimation method that fuses multiple sensors for localization; "The localization is given by a classical data fusion through an extended Kalman filter based on GNSS, IMU data and SLAM pose estimates."
- FP16 quantization: Using 16‑bit floating-point precision to speed up and reduce memory for neural network inference; "the normalized depth map is estimated using Depth Anything V2 \cite{yang2024DAV2} accelerated through FP16 quantization and TensorRT optimization."
- Foundation model: A large, pre-trained model used zero-shot for downstream tasks without additional training; "Monocular depth estimation using foundation models offers a lightweight alternative, but its integration into outdoor navigation stacks remains underexplored."
- GNSS: Global Navigation Satellite System, providing absolute positioning for the robot; "The localization is given by a classical data fusion through an extended Kalman filter based on GNSS, IMU data and SLAM pose estimates."
- IMU: Inertial Measurement Unit, providing acceleration and rotation measurements for state estimation; "The localization is given by a classical data fusion through an extended Kalman filter based on GNSS, IMU data and SLAM pose estimates."
- Isaac Sim: NVIDIA’s photorealistic robotics simulation environment used for evaluation; "Evaluated in photorealistic simulations (Isaac Sim) and real-world unstructured environments"
- LiDAR: A laser-based 3D ranging sensor producing accurate point clouds; "Most approaches rely on LiDAR for this task due to its high accuracy."
- Metric depth: Depth values expressed in real-world units (e.g., meters); "Zero-shot monocular metric depth estimation~\cite{piccinelli2024unidepth, hu2024metric3d} consists in inferring a metric depth map directly from a single camera image."
- Monocular depth estimation: Predicting scene depth from a single RGB image; "Monocular depth estimation using foundation models offers a lightweight alternative, but its integration into outdoor navigation stacks remains underexplored."
- Nav2 stack: A ROS2 navigation framework for path planning and control that can be adapted to off-road use; "It is worth noting that a more generic navigation stack such as the Nav2 stack \cite{macenski2020marathon2} can also be leveraged but it must be adapted for off-road navigation."
- Negative obstacles: Depressions or holes in terrain that appear as missing data and are difficult to detect; "Then, we plan to handle negative obstacles that are a significant challenge due to the absence of information."
- Obstacle hallucination: Falsely detected obstacles caused by perception errors, e.g., at object edges; "Two key enhancements improve robustness: edge-masking to reduce obstacle hallucination and temporal smoothing to mitigate the impact of SLAM instability."
- Point cloud: A set of 3D points representing the environment acquired via sensors or reconstruction; "Most off-road autonomous navigation approaches perform 3D perception using a LiDAR \cite{elnoor2024amco, ruetz2024foresttrav, frey2024roadrunner} to generate an accurate point cloud of the surrounding environment."
- Robot-centric (map): A map maintained in the robot’s local coordinate frame and updated as the robot moves; "The height of the obstacles, corresponding to the distance between the points and the cloth surface, is stored in a robot-centric $2.5$D grid map, the elevation map."
- ROS Noetic: A ROS1 distribution used as the middleware framework for the stack; "Our navigation stack has been implemented with the ROS Noetic framework."
- Shi-Tomasi Corner Detector (STCD): A feature detector used to select salient image points for tracking or depth sampling; "we sample points in the camera image with the Shi-Tomasi Corner Detector (STCD) \cite{shi1994good} used by VINS-Mono and leverage the ground-truth depth at these locations as reference in the rescaling module."
- SLAM: Simultaneous Localization and Mapping, estimating robot pose while building a map; "the 3D perception module takes as input either a LiDAR point cloud or an image from a monocular camera and the sparse point clouds returned by a SLAM."
- Temporal smoothing: Filtering estimates over time to reduce fluctuations from sensor/algorithm instability; "Two key enhancements improve robustness: edge-masking to reduce obstacle hallucination and temporal smoothing to mitigate the impact of SLAM instability."
- TensorRT: NVIDIA’s inference optimizer/runtime used to accelerate deep models on GPUs; "the normalized depth map is estimated using Depth Anything V2 \cite{yang2024DAV2} accelerated through FP16 quantization and TensorRT optimization."
- Timed-Elastic-Bands (TEB) local planner: A trajectory optimization-based local planner that deforms elastic bands to produce feasible paths; "It provides the high-level path to follow for the Timed-Elastic-Bands (TEB) local planner \cite{Rsmann2027teb} which computes a flexible path planning for better robustness to perception errors."
- Traversability: The property of terrain being safely passable by a robot; "A first improvement step would be to integrate traversability modules capable of classifying high grass as traversable."
- VINS-Mono: A monocular visual-inertial SLAM system providing sparse metric structure and pose; "The reference point cloud used for rescaling is given by VINS-Mono \cite{qin2018vins} and the temporal smoothing parameter is set to ."
- Visual-inertial SLAM: SLAM that fuses camera and IMU data to estimate motion and sparse structure; "The sparse depth used for estimating the scaling and shift parameters is given by a visual-inertial SLAM approach (see \cref{sec:implementation} for details on the algorithm used)."
- Zero-shot (learning): Applying a pre-trained model to new tasks or domains without task-specific training data; "Numerous zero-shot learning-based monocular depth estimation models have been developed thanks to extensive training on huge datasets."
- Zero-shot monocular metric depth estimation: Directly predicting metric depth from a single image without additional training on the target domain; "Zero-shot monocular metric depth estimation~\cite{piccinelli2024unidepth, hu2024metric3d} consists in inferring a metric depth map directly from a single camera image."
Collections
Sign up for free to add this paper to one or more collections.

