- The paper introduces a camera-only BEV instance prediction model that leverages spatio-temporal attention and gated transformer layers for improved motion forecasting.
- It employs a difference-guided module and attention-based BEV projection to enhance feature extraction and achieve robust segmentation and flow estimation.
- Empirical results on nuScenes show that the model yields superior VPQ and IoU scores, especially in long-range and complex urban scenarios.
BEVPredFormer is a camera-only BEV instance prediction model designed for robust perception in autonomous driving. The architecture integrates attention-based temporal processing modules to effectively capture spatio-temporal dependencies. It operates without recurrences in its temporal modeling, leveraging gated transformer layers for both spatial and temporal attention, as well as a multi-scale prediction head for future vehicle segmentation and motion prediction in BEV space.
The input consists of multi-camera sequences and vehicle localization information. Feature extraction is achieved via EfficientViT, maximizing attention efficiency with cascaded group attention. Image features are projected into BEV using BEVFormer, an attention-based cross-view method that mitigates the need for explicit depth estimation. Temporal consistency and fine-grained motion patterning are enhanced by a difference-guided feature extraction module, and spatio-temporal attention blocks inspired by PredFormer.
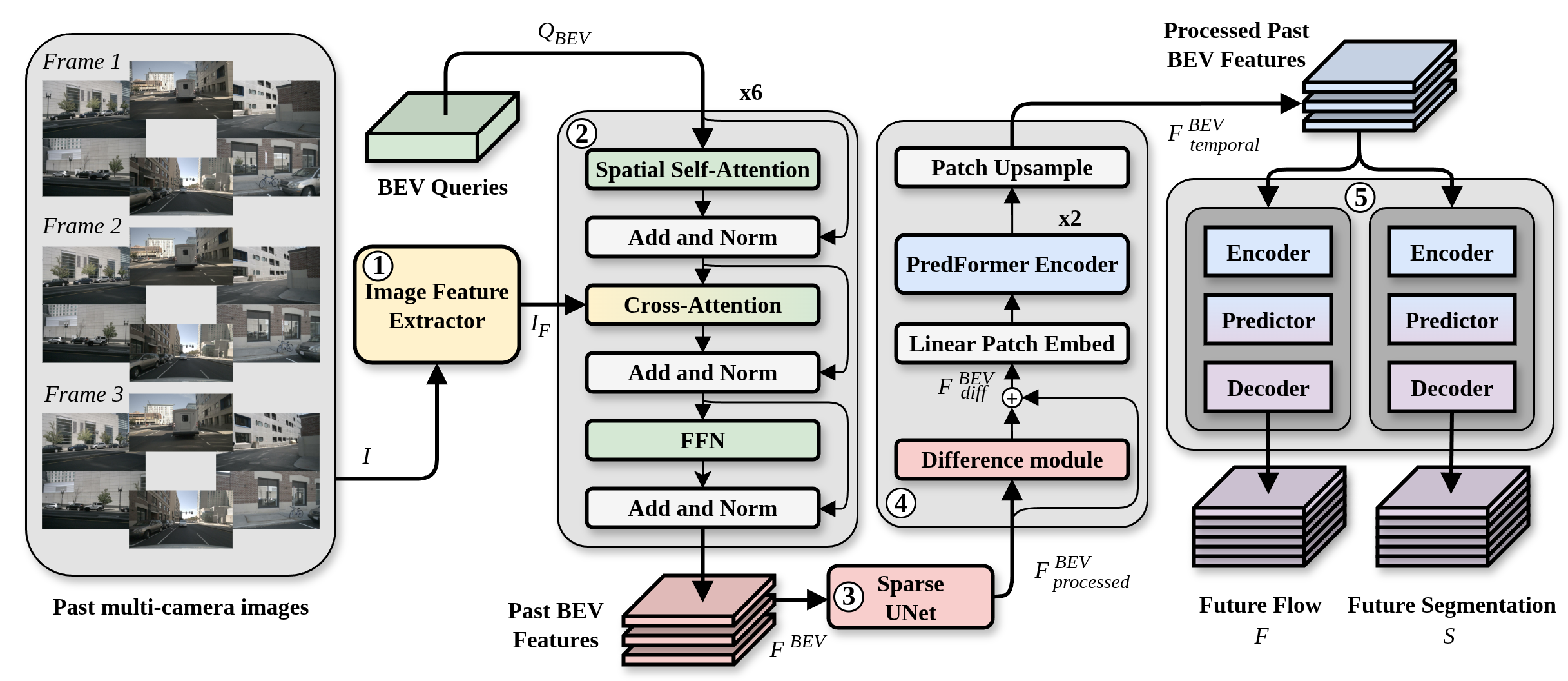
Figure 1: BEVPredFormer architectural flow: efficient feature extraction, BEV projection, temporal attention, and multi-scale predictive decoding.
Temporal Modeling and Difference-Guided Enhancement
The temporal module is a core innovation, comprising two main stages: the difference module and transformer-based spatio-temporal blocks. The difference module performs frame-wise subtraction between consecutive BEV feature maps, assigning additional weights to regions with high temporal variation, thereby amplifying motion-specific features for subsequent prediction tasks.
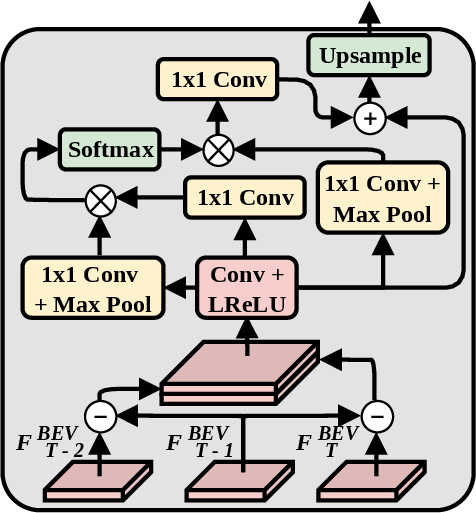
Figure 2: Difference module architecture captures temporal variances in BEV features for enhanced flow representation.
PredFormer-based blocks receive difference features and employ patch-wise embedding, gated transformer encoding, and divided spatial-temporal attention. Absolute positional encoding is incorporated to retain spatial coherence. Multiple attention configuration patterns are evaluated (Binary-TS, Triplet-TST, Quadruplet-TSST), with experiments confirming the advantage of temporal-first attention ordering for improved accuracy in forecasting.
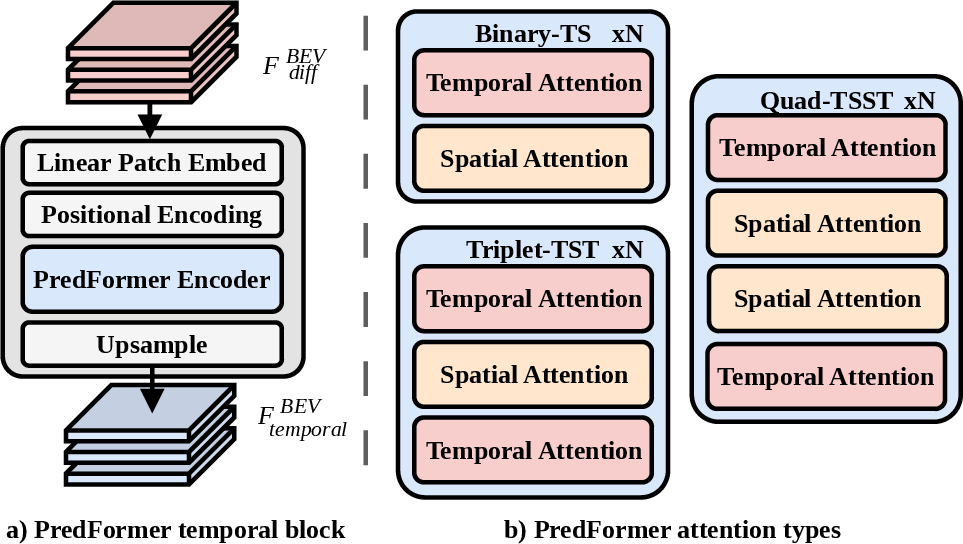
Figure 3: PredFormer temporal attention—diagram of spatio-temporal processing and differentiated attention block patterns.
Instance Prediction: Flow and Segmentation
BEVPredFormer produces two principal outputs: backward optical flow maps in BEV (for pixel-wise displacement tracking) and BEV semantic segmentation maps (for occupancy and classification). A multi-scale prediction head encodes temporally enriched BEV features, decodes future states, and fuses outputs for instance ID propagation.
Crucially, backward flow formulation mitigates propagation errors typically induced by fast-moving objects and occlusions. Auxiliary supervision is applied to centerness and offset maps, refining BEV instance segmentation.
Evaluation on nuScenes adheres to standardized metrics: Intersection over Union (IoU) for per-frame segmentation, and Video Panoptic Quality (VPQ) for temporal instance tracking consistency. The model achieves superior segmentation accuracy and competitive VPQ scores, especially notable in long-range prediction scenarios.
Key numerical observations:
- Long range: VPQ = 33.3, IoU = 40.9
- Short range: VPQ = 54.9, IoU = 63.9
Comparative ablation shows that adoption of temporal attention and difference modules consistently improves both VPQ and IoU. Two temporal blocks (Triplet-TST) optimize the tradeoff between computation and accuracy. Image resolution is tightly coupled with performance, with increases yielding greater spatial detail but incurring additional computational latency.
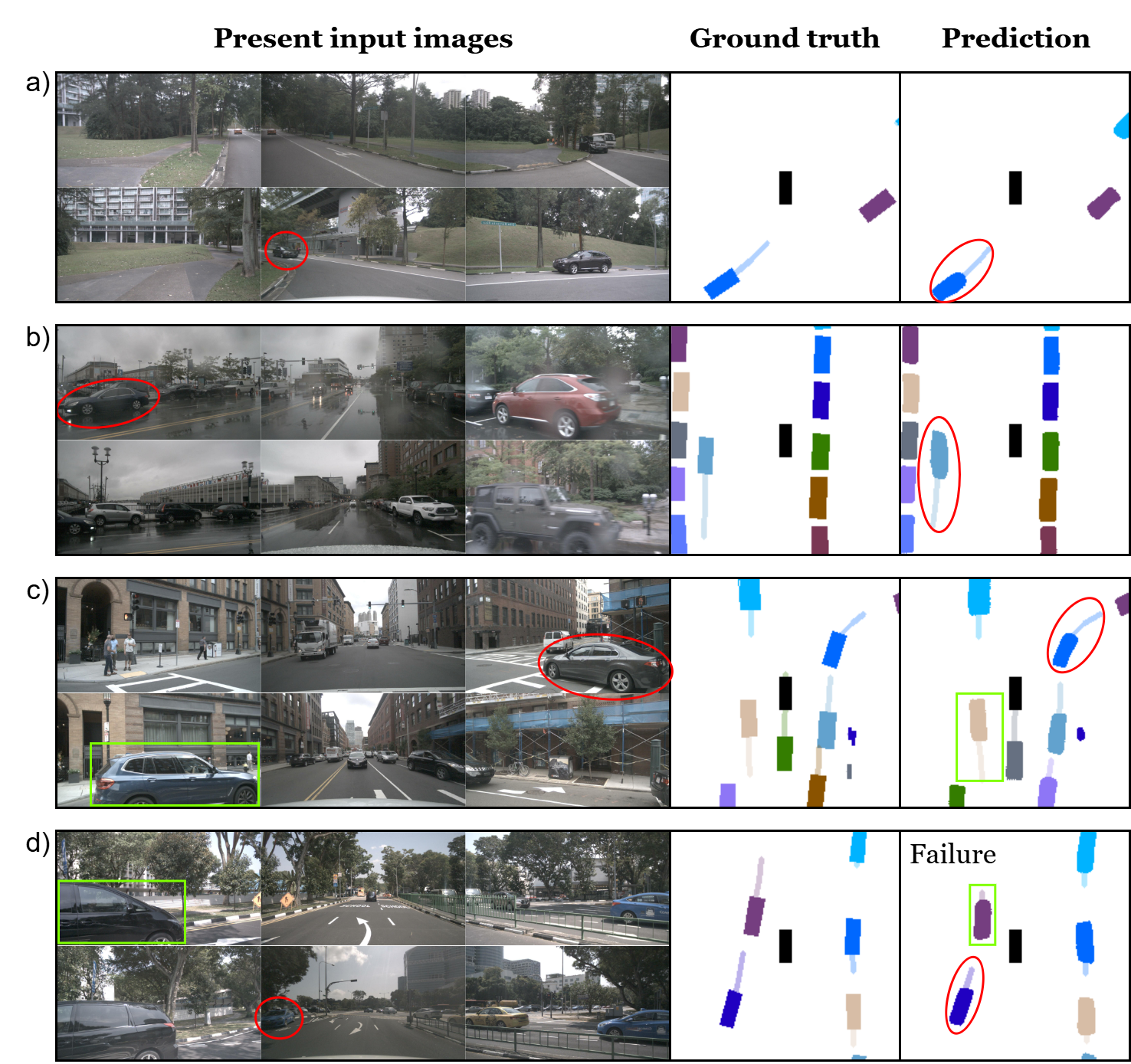
Figure 4: Short-range results—consistent object correspondence between camera view and BEV prediction.

Figure 5: Long-range results—accurate vehicle predictions across varying distances and complex scene layouts.
Qualitative visualizations demonstrate robust detection and forecasting of vehicles in diverse scenarios, including urban intersections and adverse weather. While future motion accuracy is high, some degradation is observed in extended temporal horizons, particularly for objects distal from the ego vehicle.
Implications, Limitations, and Future Research Directions
Practically, BEVPredFormer's attention-driven, recurrent-free architecture offers improved computational efficiency and parallelization, supporting real-time operation. Its reliance on attention-based cross-view BEV projection obviates the need for depth estimation, allowing streamlined sensor fusion and compensation for ego-motion.
Theoretically, the model exemplifies the application of transformer-based—especially spatio-temporal—architectures to dense, structured instance forecasting from raw sensor data. Unlike multi-stage pipelines with sequential tracking, instance prediction enables end-to-end representation learning for joint detection and motion modeling.
Further development should explore:
- Integration of non-camera sensors (LiDAR, RADAR) for multi-modal fusion
- Extension of input temporal horizon for improved long-term motion prediction
- Adaptive attention mechanisms to handle sparse BEV occupancy
- Continual learning in dynamic environments with online updates
Conclusion
BEVPredFormer introduces a robust, efficient spatio-temporal attention framework for camera-based BEV instance prediction in autonomous driving. Its unified, attention-centric design outperforms depth-based models in segmentation and maintains comparable temporal instance quality. The architecture's adaptability signals promising directions for scalable, dense perception in future autonomous systems, setting a foundation for temporally consistent, scene-aware, semantics-guided BEV modeling.

