- The paper introduces a transformer-based multi-head attention architecture that effectively handles Russian morphological tagging.
- The paper employs subtoken aggregation via byte-pair encoding and intra-word attention to robustly manage out-of-vocabulary words.
- The paper achieves 98–99% accuracy on key grammatical features using only 48M parameters, providing a lightweight alternative to larger BERT systems.
Multi-Head Attention Architecture for Open-Vocabulary Russian Morphological Tagging
Introduction
This paper introduces a morphological tagging system for Russian grounded in a multi-head attention (MHA) architecture, emphasizing compatibility with open dictionaries—that is, the model efficiently handles previously unseen or fictional words, a necessity for robust natural language understanding in Russian. The model discards both RNNs and heavy transformer pretraining (such as BERT), offering a solution with markedly reduced computational demands, fast training, and competitive or superior accuracy on core grammatical tagging tasks.
Architectural Overview and Data Pipeline
The primary innovation is a multi-stage architecture that processes linguistic segments (sentences), where each word is decomposed into subtokens via Byte Pair Encoding (BPE). This forms the basis for a pipeline facilitating open-vocabulary support. The model then leverages hierarchical encoding: within-word token attentions produce compositional word vectors, which are subsequently passed through transformer encoder blocks. Morphological classification is performed per word using a feedforward neural classifier.
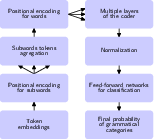
Figure 1: The data processing pipeline, including BPE-based segmentation, within-word attention, transformer encoding, and final classification.
Tokenization is not restricted to dictionary words; words are partitioned into subtokens, ensuring the model’s vocabulary dynamically accommodates neologisms and out-of-vocabulary terms. The design opts for BPE over n-gram approaches owing to its flexibility and marginal influence on down-stream tagging accuracy.
Word Representation and Attention Mechanism
Each word is capped at six subtokens (sufficient for covering 98% of cases in the datasets). Within each word, dot-product attention computes token importances, aggregating subtoken embeddings via weighted sum informed by a learned network. This hierarchical attention lifts the representation to the word level, where standard positional encoding is applied before processing with four transformer encoders. The resulting representations fuel a classifier predicting grammatical categories.
Notably, the system avoids RNN-related drawbacks—sequential bottlenecks and context imbalance at sequence boundaries—and obviates pretraining on large unlabeled corpora.
Datasets and Experimental Details
The model is trained and evaluated on the union of two major treebanks: UD SynTagRus and UD Taiga. This merged dataset encompasses over 2.9 million words for training, with test sets capturing a wide range of Russian grammatical and lexical phenomena. Model training is conducted on a single consumer-grade GPU (nVidia RTX 4090), with convergence achieved within 8–12 hours using approximately 48 million parameters.
Numerical Results and Comparative Analysis
Experiments assess accuracy, recall, precision, and F1 per morphological category. The architecture attains 98–99% accuracy on most grammatical categories. Overall, the mean accuracy across categories approaches 99.05%. Full-category accuracy per word reaches approximately 95.36% for a selected canonical set, comparative to, and on some categories exceeding, results from heavy-weight BERT-based taggers and substantially surpassing RNN- or GRU-based systems. For instance:
- UPOS accuracy: 98.46% (vs. 98.33% for state-of-the-art RNN-based models)
- Average model size: 48M parameters (vs. >400M for BERT-based models)
- Training runtime: under 12 hours on a single consumer GPU
The model demonstrates clear efficiency gains: smaller parameter footprint, reduced hardware requirements, and faster training and inference, without sacrificing accuracy for core categories.
Implications and Future Directions
The results have significant implications for scalable, resource-efficient NLP systems addressing morphologically rich languages. In practical deployments, the model's open-vocabulary handling is critical for real-time applications (e.g., voice assistants, machine translation, or digital linguistic tools) operating on dynamic or out-of-domain text where dictionary closure is infeasible.
Theoretically, the findings suggest that full transformer-scale pretraining is not strictly necessary for high-accuracy morphological tagging when appropriate subtokenization and local attention mechanisms are exploited. Situations prioritizing deployment cost or rapid adaptation to new domains will benefit particularly.
Potential extensions involve integrating richer n-gram features, applying the architecture to abbreviated or non-standard forms (where context weighting becomes pivotal), and extending the model to related morphological analysis tasks in similarly complex languages.
Conclusion
The presented system leverages multi-head attention without full transformer pretraining, achieves near state-of-the-art accuracy in Russian morphological tagging, and is operationally efficient on commodity hardware. Its explicit subtoken design promotes robust open-dictionary handling. The work suggests a promising direction for practical, deployable linguistic models for morphologically complex languages, balancing accuracy and efficiency, and lays a foundation for further exploration of lightweight yet expressive encoder architectures for sequence labeling.