- The paper demonstrates that advanced LLMs, particularly Gemini 3.0 Pro, can generate optimal plans in complex combinatorial domains via serial algorithmic simulation.
- It employs a graph-rewrite abstraction to isolate genuine topological reasoning, validating plan optimality across multiple scaling axes such as width, depth, and compositionality.
- Comparative analysis reveals that the LLM outperforms classical planners until computational limits induce an abrupt failure mode, underscoring its structured reasoning capabilities.
Analysis of Optimality of LLMs on Planning Problems
Introduction
This work rigorously examines the optimality and reasoning boundaries of LLMs in solving structured combinatorial planning problems. Departing from standard coverage-based benchmarks, the study investigates whether frontier LLMs pursue optimal strategies or resort to suboptimal heuristics when plan space complexity escalates. The principal focus is the Blocksworld domain and its generalized P∗ (Path-Star) graph formalization, enabling systematic manipulation of planning depth, width, and compositionality. Notably, the analysis isolates genuine topological reasoning by obfuscating semantic priors via a graph-rewrite abstraction.
The Blocksworld domain is reformulated as a generalized P∗ graph, where the table corresponds to the root node, and each stack of blocks forms a disjoint branch. This structural isomorphism frames the planning challenge as a multibranch path-traversal problem requiring dependency chain reconstruction, branch identification, and sequential clearing/stacking operations.
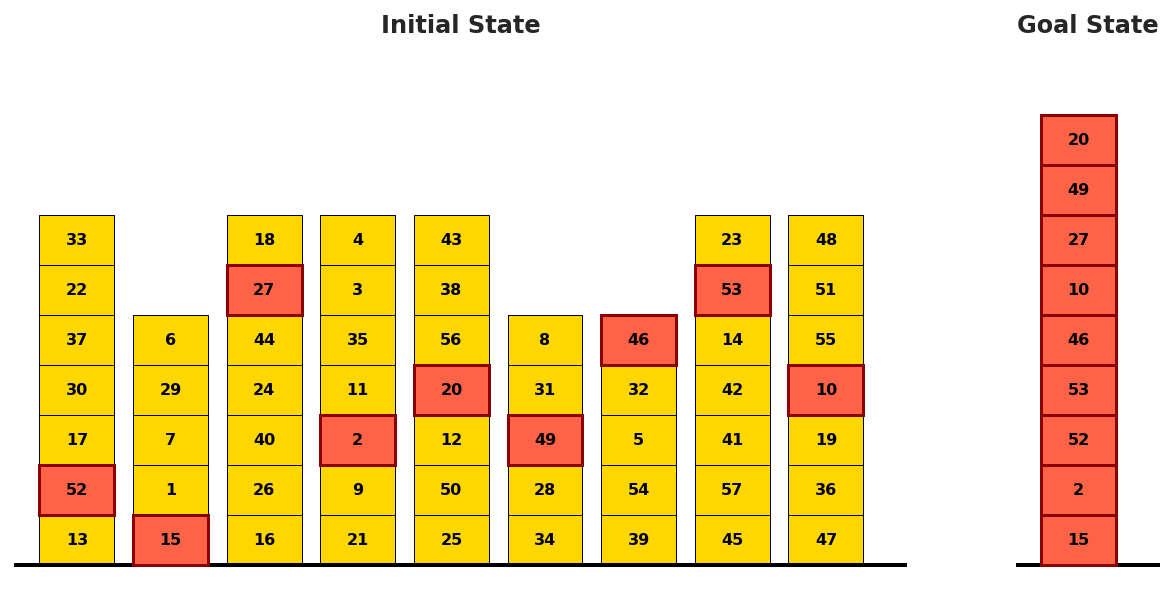
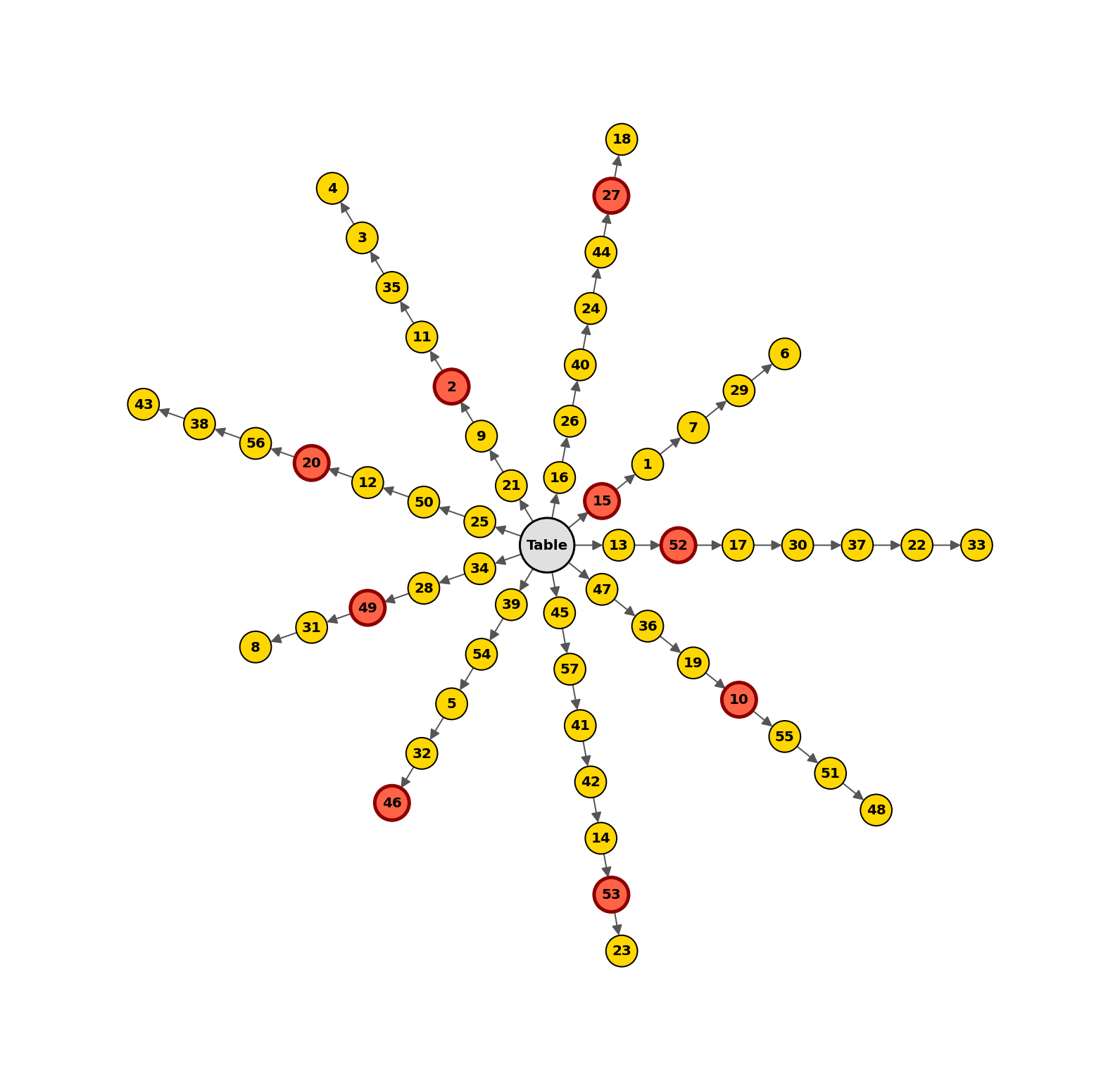
Figure 1: Structural correspondence between Blocksworld's physical configuration and P∗ graph topology, establishing plan composition as structured traversal.
Experimental Methodology
A synthetic benchmark grid is constructed along four complexity axes:
- Harvest: Increasing number of goal blocks (width scaling)
- High Towers: Deepest tower extraction (depth scaling)
- Interleaved Harvest: Entangled goal dependencies (compositionality)
- Grand Challenge: Simultaneous, holistic scaling
To rigorously stress reasoning, the LLM is provided with only a single-instruction demonstration, the full PDDL domain, and the query (no chain-of-examples). Plans are validated using the VAL validator, and optimality is measured via analytical cost decompositions. Critically, graph-rewrite versions strip all semantic cues present in Blocksworld, isolating structure-driven reasoning.
Strong Empirical Results and Comparative Analysis
The reasoning-enhanced LLM (Gemini 3.0 Pro) is benchmarked against classical planners: A*/LM-Cut (guaranteed optimal, but computationally infeasible) and LAMA-2011 (satisficing, suboptimal in hard regimes).
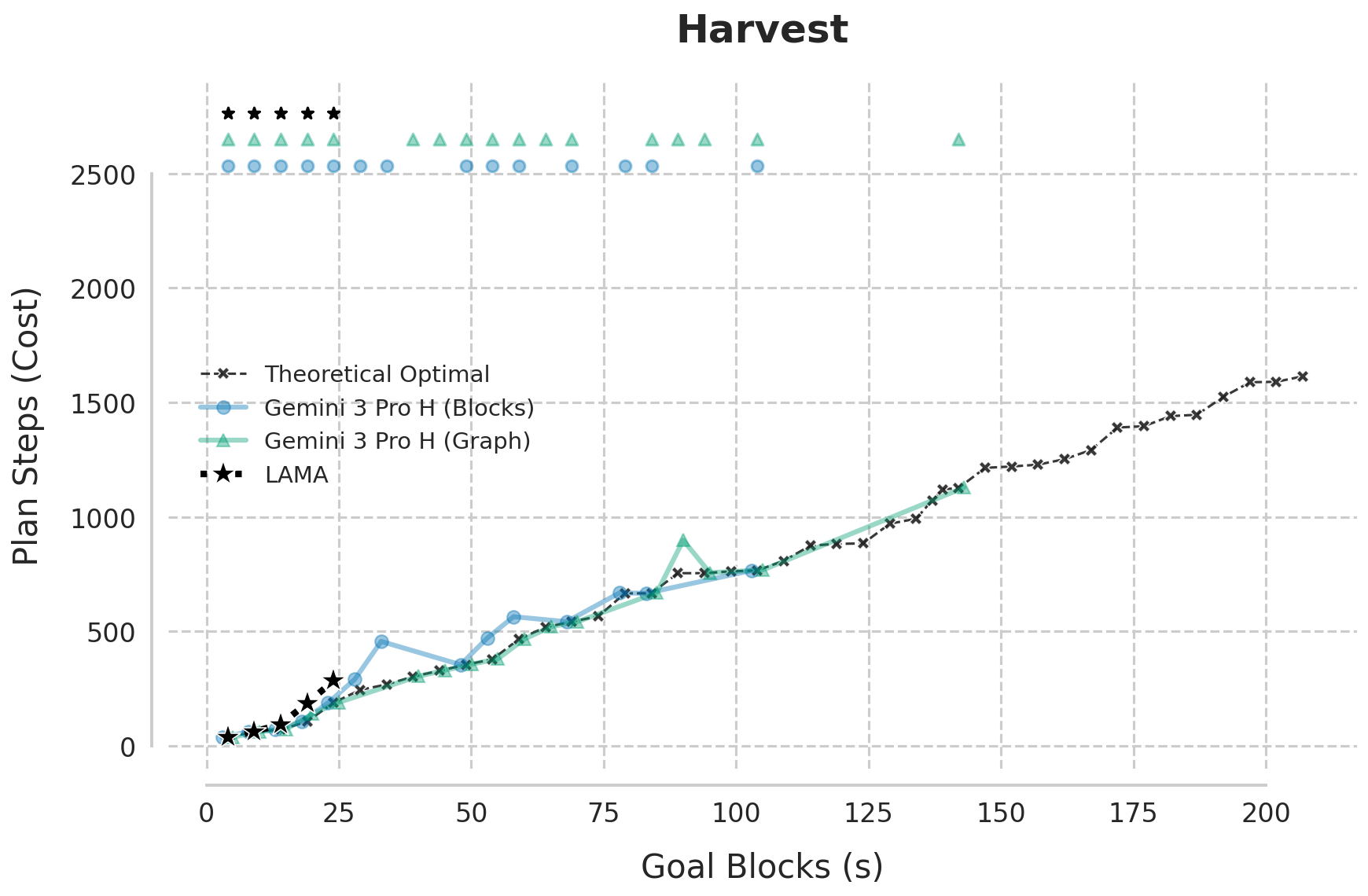
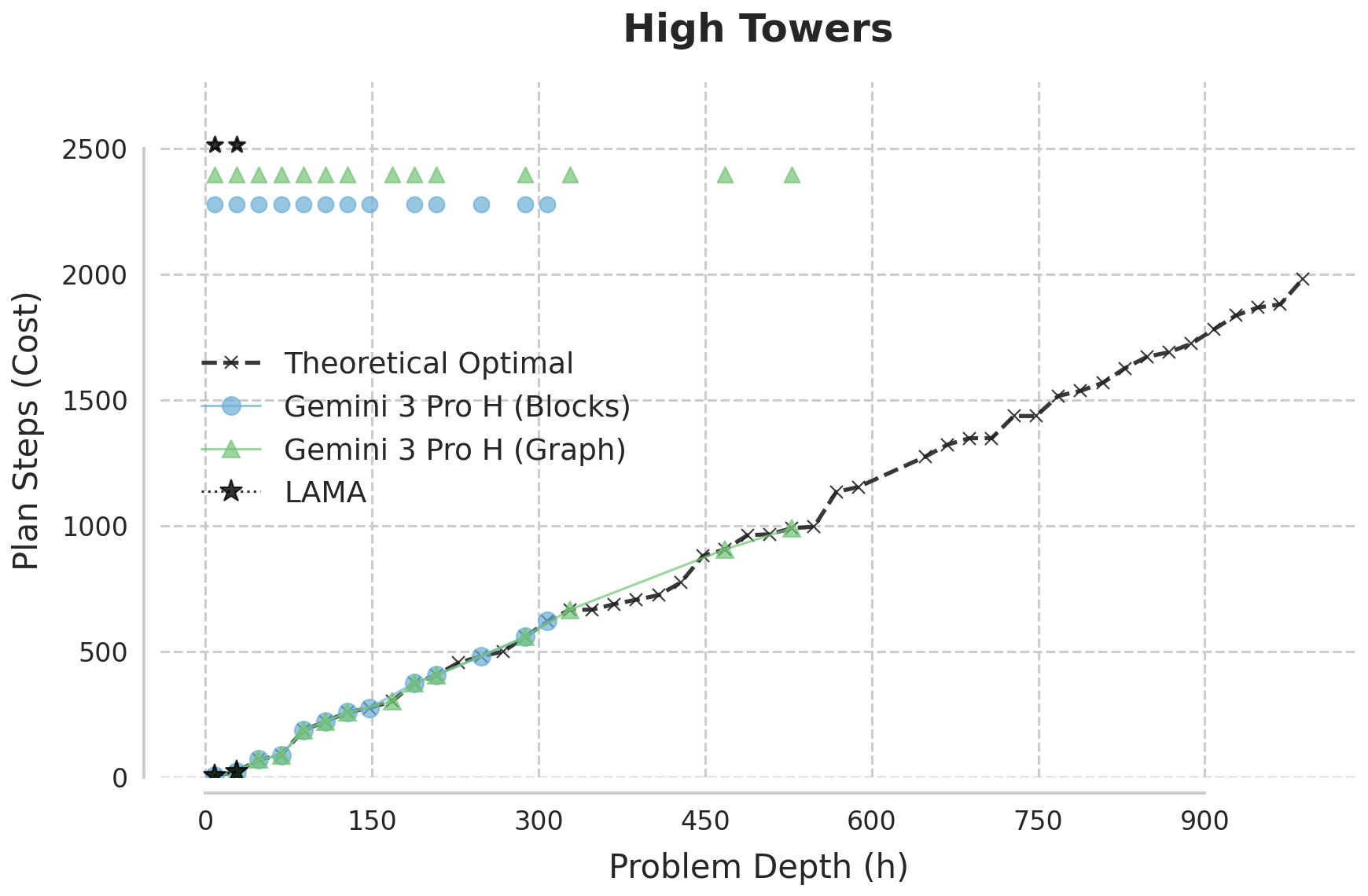
Figure 2: Plan cost curves as goal block count and tower height increase, highlighting the LLM's ability to track theoretical optimality well beyond classical planner breakdown.
Across all scenarios, Gemini 3.0 Pro consistently generates optimal solutions up to complexity regimes where both A*/LM-Cut and LAMA either fail or become arbitrarily suboptimal. In the width-scaling Harvest curriculum, Gemini maintains optimality beyond 100 goal blocks/towers, unlike LAMA, which breaks at ~25. In depth-intensive High Towers and the combinatorially extreme Grand Challenge, the LLM sustains near-perfect optimality with a sharp transition to a "zone of instability," where it fails abruptly, rather than gradually degrading.
Presenting the results on compute allocation:
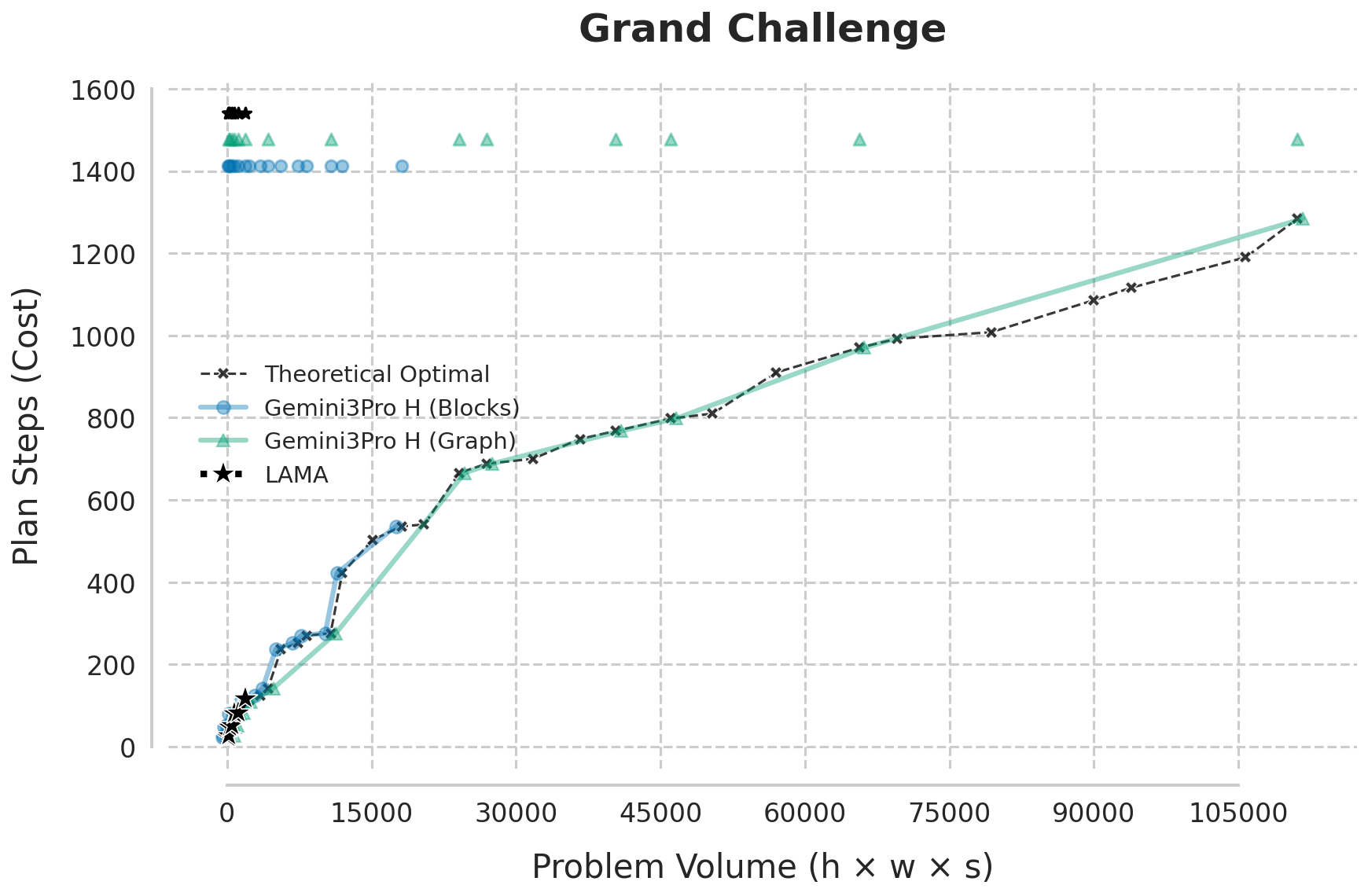
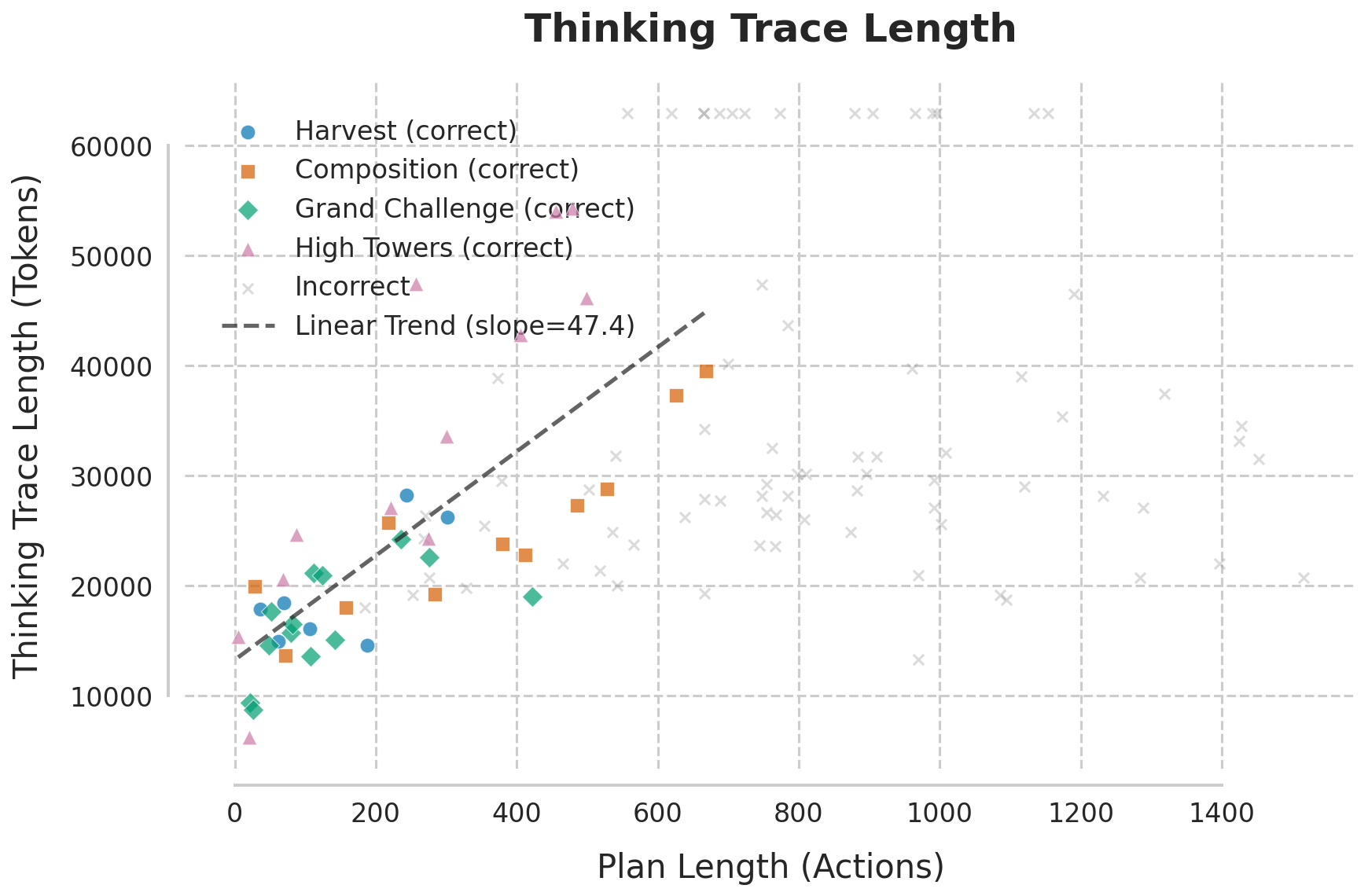
Figure 3: (a) Plan cost vs. problem volume—the LLM sustains optimality as classical planners collapse; (b) Linear scaling of reasoning token utilization with optimal plan length until inference-time failure boundary.
A striking linear proportionality is observed between the number of "thinking tokens" (inference-time reasoning steps) and optimal plan length—roughly 47 tokens per optimal step. No evidence is found that the model trades optimality for reduced reasoning: it either successfully simulates an optimal plan or fails catastrophically due to compute/service constraints.
Mechanistic Analysis: Serial Algorithmic Simulation versus Geometric Memory
Analysis of Gemini's internal thought traces reveals explicit enumeration of dependency chains for target blocks and systematic procedural decomposition—clear evidence of a stepwise Serial Algorithmic Simulation. The model identifies the correct branch of the P∗ structure, recursively traverses up the dependency chain, sequentially clears obstacles, and performs stacking operations, all represented in structured intermediate summaries.
Nonetheless, unexplained retrieval efficiency—how the correct dependency chain is extracted from a randomly permuted predicate context—hints at latent geometric or topological representations (Geometric Memory). While these may enable O(1) lookup of target branches in latent space, current evidence predominantly supports a serial, simulation-driven modus operandi.
Robustness to Semantic Decoupling: Graph-Rewrite Experiments
A key aspect is obfuscating domain semantics. In the graph-rewrite formalization, where all physical/semantic cues are stripped, the LLM continues to operate near the optimal bound, albeit with increased instability at higher scales. The model demonstrates authentic topological reasoning, not mere template memorization.
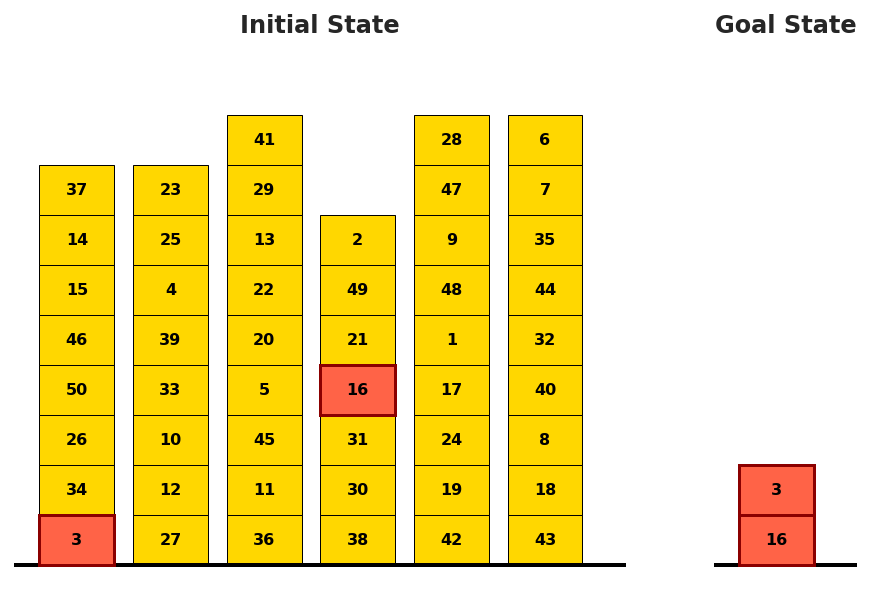
Figure 4: Example of a Grand Challenge plan with scrambled predicate encoding, evidencing resilience to domain obfuscation.
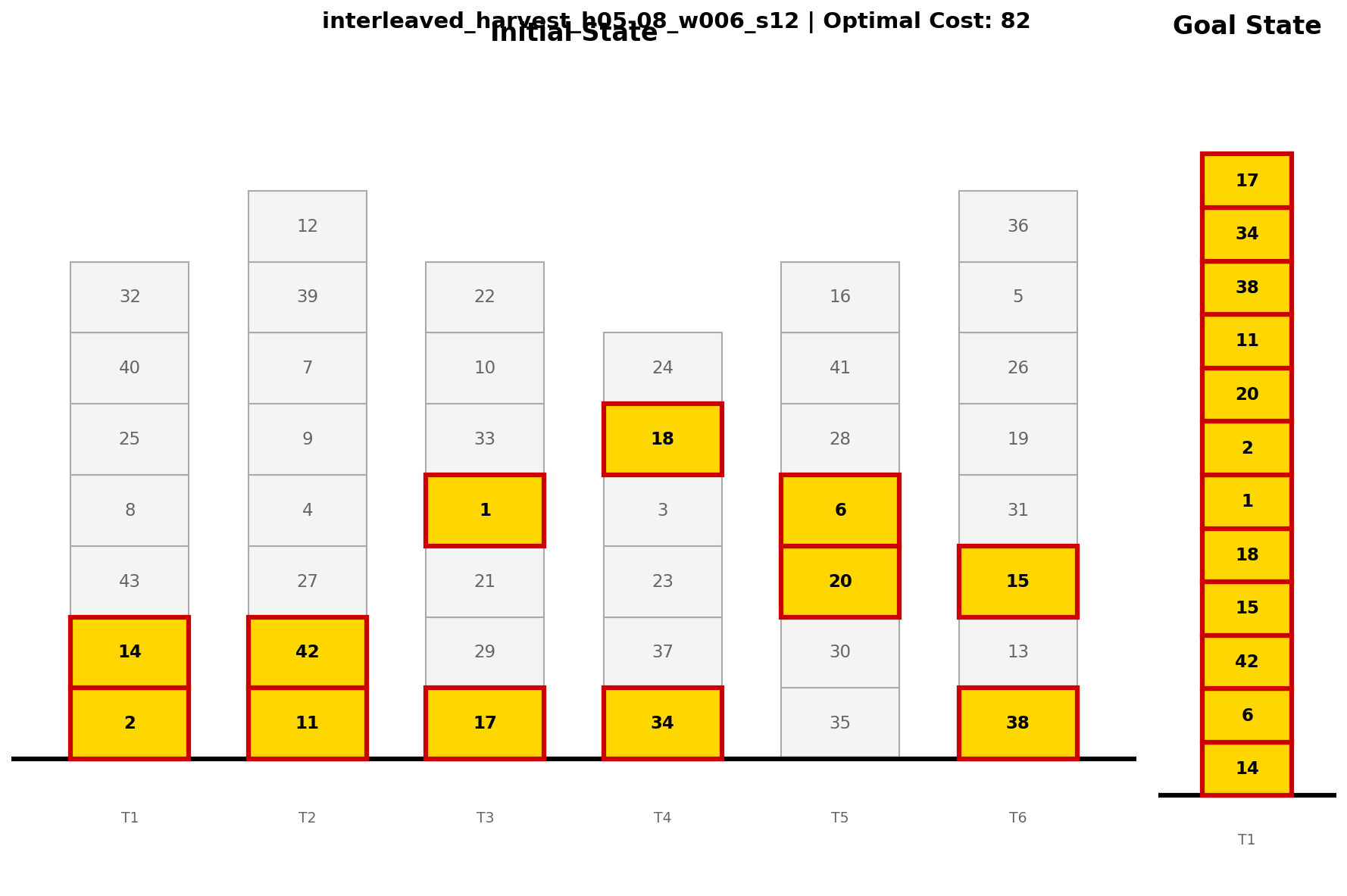
Figure 5: Interleaved Harvest illustrates successful planning with deep cross-tower dependencies, far surpassing classical search feasibility.
Implications for Planning, LLM Capabilities, and AI
The research provides strong evidence that reasoning-augmented LLMs are capable of systematic symbolic plan search at scales where classical, even optimal, planners collapse under combinatorial pressure. The ability to decompose the planning graph, isolate independent subproblems, and simulate optimal strategies strictly serially blurs previous assumptions that LLMs cannot handle true reasoning or must rely on shallow pattern completion. The findings contradict earlier claims about the lack of generalizable planning skills in LLMs even when deprived of domain-specific training priors.
Practically, this work underwrites the feasibility of deploying LLMs in combinatorially intensive planning domains where symbolic search methods become intractable, given sufficient (and dynamically allocated) inference-time compute. Theoretically, it motivates re-examining the internal architectures of deep sequence models to interrogate the interplay of serial processing, latent topological representations, and memory bottlenecks in supporting advanced reasoning.
It also exposes the abrupt, rather than gradual, failure modes of LLMs: as serial simulation exhausts compute, the transition is from strict optimality to outright plan generation failure, not to decline into heuristic suboptimality.
Future Directions
Several new questions arise for the research community:
- Extending the P∗ structural taxonomy to non-trivial, non-decomposable topologies (e.g., loopy, highly entangled graphs)
- Generalizing findings to other state-of-the-art LLMs to ascertain universality of serial token scaling and structural failure boundaries
- Probing internal attention, activation, or latent geometry for direct evidence of geometric navigation or O(1) branch retrieval
- Designing adaptive compute allocation strategies for planning during inference-time
Conclusion
This study demonstrates that advanced LLMs equipped for reasoning not only rival but often surpass classical planning methods on structurally complex domains, maintaining optimality until hard computational limits are met. The combination of topological generalization, robustness to semantic obfuscation, and systematic simulation provides new insights into the representational and computational capabilities of modern generative models in planning-centric contexts.
Figure 1: Structural isomorphism between Blocksworld and P∗ graph; planning reduces to path traversal in a generalized dependency graph.
Figure 2: Gemini 3 Pro matches or beats LAMA on both goal-count and tower-height scaling, with errors only at extreme instance sizes.
Figure 3: LLM sustains linear compute scaling with plan length, failing only at strict inference-step limits; classical planners become immediately intractable as complexity grows.
Figure 4: Grand Challenge initial/goal configuration—Gemini 3 Pro generates plans in regimes unreachable by classical planners.
Figure 5: Interleaved Harvest instance with extensive goal dependencies, highlighting complexity that is challenging for non-LLM planners.