- The paper introduces an asynchronous, training-free multi-agent architecture for agile UAV navigation that decouples high-level cognitive reasoning from low-level control.
- It employs a novel Impression Graph for sparse scene memory and look-ahead reasoning, significantly enhancing interaction availability and reducing hovering time.
- The system demonstrates superior success rates, reactive vision-based obstacle avoidance, and adaptability in dynamic, cluttered environments.
QuadAgent: Asynchronous Vision-Language Agent Architecture for Agile Quadrotor Flight
Motivation and Context
The increasing integration of LLMs and VLMs into autonomous systems has spurred advances in vision-language navigation (VLN) for aerial platforms. However, existing methods in UAV navigation often rely on either fine-tuned, data-intensive end-to-end models or manually structured serial pipelines. These design choices typically entail significant trade-offs in responsiveness, memory integration, and flexibility. Serial agent systems, including those built atop ReAct, suffer from blocking behaviors—hindering real-time interaction and fluidity during flight—while end-to-end approaches lack explicit, persistent scene representations necessary for long-horizon reasoning and agile 3D navigation.
QuadAgent seeks to explicitly address these limitations by introducing a training-free, asynchronous multi-agent architecture. Its key contributions include strict decoupling of high-level cognitive reasoning from low-level control, the introduction of a lightweight yet expressive Impression Graph as scene memory, and the adoption of a vision-based physical safety layer for robust obstacle avoidance.
System Architecture
Asynchronous Multi-Agent Workflow
QuadAgent leverages two distinct agent categories at its cognitive layer: Foreground Workflow Agents and Background Agents. Foreground agents—spanning an orchestrator, planner, and executor—manage event-driven workflows, routing tasks and responding to aperiodic user or environmental events without blocking ongoing physical actions. Notably, the use of a suspend-and-resume protocol allows the system to remain responsive to mid-flight queries and dynamically modify trajectories in real time.
Immediately upon invoking a navigation skill, control is yielded to the physical layer, with Foreground agents transitioning to an idle, event-monitoring state. This interaction model facilitates "chatting-while-flying," resolving queries and preemptively adapting behaviors during ongoing navigation.
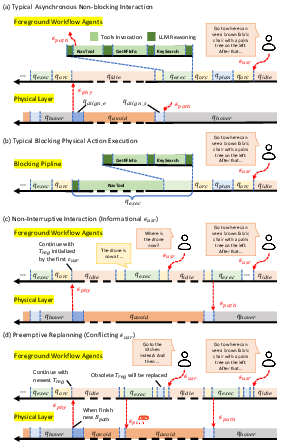
Figure 2: Timeline comparison demonstrates non-blocking suspend-and-resume interaction versus the blocking baseline, enabling dynamic response and fluid user interaction during flight.
Complementing this, Background Agents perform look-ahead reasoning and context retrieval for upcoming sub-tasks, masking the inference latency that otherwise plagues sequential or blocking systems. Retrieved context is injected into sub-task execution prompts, further minimizing hovering and wait times.
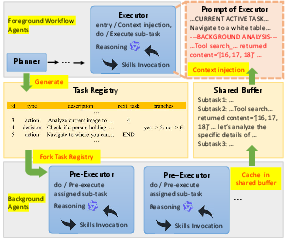
Figure 4: Data flow architecture for asynchronous background pre-execution, enabling context caching and prompt injection for Foreground agent execution.
Skill Library
The agent's skill library is organized into mnemonic, perceptual, and navigation modules, abstracting high-level reasoning from implementation details. Mnemonic skills support dynamic querying of the Impression Graph for semantic and spatial context. Perceptual skills offer on-demand analysis of UAV state or real-time VLM-based image interpretation, ensuring grounding in physical reality. Navigation skills compute paths over the Impression Graph, projecting topological waypoints into world coordinates, and triggering non-blocking execution events at the physical layer.
Impression Graph: Sparse Topological Scene Representation
Unlike dense 3D scene graphs that incur considerable overhead and struggle with dynamic environments, QuadAgent adopts the Impression Graph: a sparse, multimodal topological map where nodes encode scene keyframes (with pose, CLIP embedding, and VLM-based semantic captions) and edges reflect traversable connectivity derived via depth-based pyramidal frustum intersection. This construction enables the agent to discover and utilize novel shortcuts unavailable to human demonstrators or path-based baselines, providing efficient and flexible spatial reasoning with minimal memory and computation.
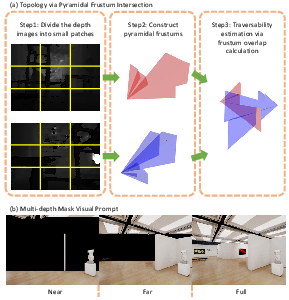
Figure 1: Impression Graph construction pipeline using patch-based depth frustum analysis for connectivity and multi-depth segmentation for robust node semantics.
A multi-depth segmentation and VLM-based captioning mechanism is deployed for semantic node enrichment, reducing hallucination and improving spatial reasoning capabilities across diverse visual contexts.
Physical Layer: Differentiable Vision-Based Obstacle Avoidance
The physical layer employs a convolutional recurrent neural policy πθ, trained via differentiable physics, for high-frequency, reactive obstacle avoidance and trajectory tracking. This policy operates independently of the cognitive layer's reasoning cycle and is robust to dynamic, unmapped obstacles and network-induced latency.
Experimental Results
Simulation Benchmarks
QuadAgent was evaluated in three AirSim environments with 60 complex missions (25% conditional logic), using rigorous baselines: Serial Plan-ReAct, Scene Graph Agent (ConceptGraphs-based), and Traj NavGraph (topologically-derived navigation). Key assessment metrics include Success Rate (SR), Oracle Success Rate (OSR), Success weighted by Path Length (SPL), Progress, Total Execution Time (TET), Hovering Time (HT), and non-blocking Interaction Availability (IA).
QuadAgent achieves the highest SR (80.0%) and OSR (86.7%), outperforming all baselines in navigation success and efficiency. Notably, IA increases from 0.0% (blocking Serial Plan-ReAct) to 58.3%, with a corresponding reduction in HT from 249.9s to 118.0s. Traj NavGraph, although achieving a competitive OSR, demonstrates significantly lower SPL due to inefficient routing—whereas QuadAgent, via Impression Graph-induced shortcuts, attains the highest SPL (58.6). Removal of look-ahead reasoning or on-demand retrieval modules leads to substantial deterioration in these metrics, underscoring the necessity of both architectural features for system performance.
Real-World Evaluation
Deployed on an onboard-constrained fpv-style UAV, QuadAgent demonstrates high-agility semantic navigation in cluttered real-world indoor environments at speeds up to 5.1 m/s. The agent consistently interprets complex, conditional instructions, reasons over sparse scene priors, and adapts trajectories in real time in response to dynamic user commands and informational queries.
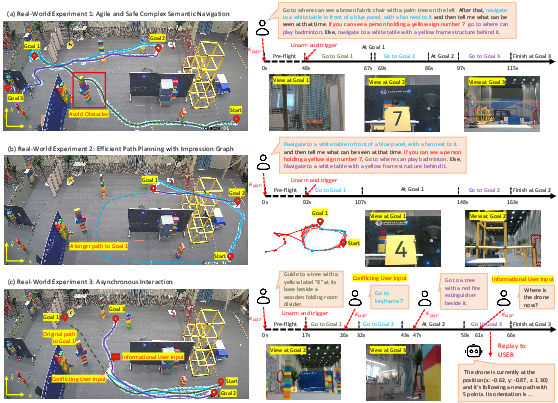
Figure 3: Real-world case studies. (a) Long-horizon conditional execution with agile obstacle avoidance. (b) Shortcut discovery via topological connectivity. (c) Asynchronous handling of dynamic user interrupts during navigation.
The Impression Graph enables the agent to exploit spatial shortcuts that are not captured in human-collected paths, and the asynchronous suspend-and-resume protocol allows for seamless, non-intrusive user interaction and knowledge querying during execution.

Figure 5: Example of complex reasoning: the agent dynamically alters goal-driven behavior based on observed environmental cues.
Implications and Future Directions
QuadAgent demonstrates that decoupling high-level semantic reasoning from low-level motor control through asynchronous agent frameworks and lightweight topological memory can dramatically enhance the responsiveness, efficiency, and agility of vision-language guided UAVs. The separation of cognitive and physical layers accommodates resource limitations and latency constraints of real-world systems, while the Impression Graph architecture balances memory compactness with semantic expressivity.
Theoretical implications include support for hierarchical, context-adaptive control policies and robust mid-flight plan revision grounded in naturalistic interactive paradigms. Practically, this architecture may inform design patterns for broader classes of embodied, instruction-following agents beyond UAVs, facilitating deployment in environments with unpredictable dynamics, strong latency constraints, or frequent human input.
Looking forward, expanding the skill library towards active exploration, richer manipulation, and closed-loop perception-action loops, as well as integrating online Impression Graph construction and lifelong learning mechanisms, represent promising directions to strengthen the autonomy and adaptability of vision-language-guided physical agents.
Conclusion
QuadAgent establishes a robust, responsive architecture for agile vision-language UAV navigation, uniting asynchronous multi-agent reasoning, on-demand scene-memory retrieval, and a differentiable physical control layer. The empirical results substantiate strong gains in task success, efficiency, and interaction availability over prevailing paradigms, attributable to both the architectural decoupling and the Impression Graph's sparse, semantically rich representation. These contributions advance the design of deployable, interactive embodied agent systems and provide a scalable path for further research on high-level cognition in robotics.
Reference: "QuadAgent: A Responsive Agent System for Vision-Language Guided Quadrotor Agile Flight" (2604.02786)

