- The paper introduces a novel FFCIL framework that addresses irregular class arrival by mitigating catastrophic forgetting and prediction bias.
- It proposes a class-wise mean loss, replay-only distillation, and dynamic intervention weight alignment to stabilize gradient updates and normalize losses.
- Empirical results on CIFAR-100, VTAB, and ImageNet demonstrate consistent accuracy gains and reduced step-size sensitivity compared to traditional CIL methods.
Free-Flow Class-Incremental Learning: A Principled Framework for Irregular Class Arrival
Introduction
Class-Incremental Learning (CIL) addresses the challenge of continually learning new categories from non-stationary data streams while maintaining knowledge of previously learned classes. Existing CIL paradigms generally assume balanced, equally partitioned tasks, which sharply contrasts with the complexities of real-world environments where the set of new classes arriving at any update may be highly variable. "Towards Realistic Class-Incremental Learning with Free-Flow Increments" (2604.02765) formalizes this more realistic scenario as Free-Flow Class-Incremental Learning (FFCIL), proposing a unified framework to robustly address its unique instabilities.
The study demonstrates empirically that FFCIL induces striking degradation across standard CIL algorithms and introduces methodological innovations to minimize optimization drift and catastrophic forgetting under free-flow schedules. The proposed framework is shown to yield consistent gains across a comprehensive suite of methods and benchmarks, including CIFAR-100, VTAB, and ImageNet.
Problem Definition and Analysis
FFCIL relaxes the regular, controlled task partition adopted by conventional CIL, allowing the number of new classes per update to vary arbitrarily and unpredictably. Formally, each incremental step t introduces a non-empty new class set Ct with unconstrained cardinality; the only restriction is absence of label repetition.
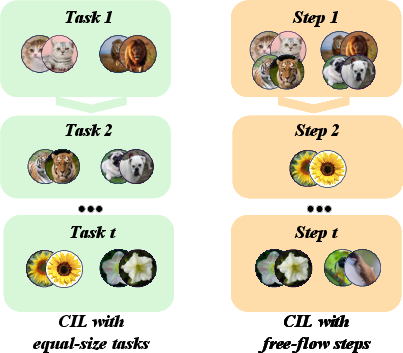
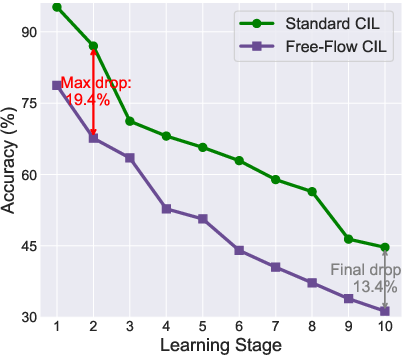
Figure 1: (a) Free-flow increments allow varying class additions per step; (b) Standard CIL methods suffer pronounced accuracy drops under FFCIL even with equivalent total classes and stages.
The central challenge arises from the instability in data distribution between steps. Variable class increments result in unbalanced gradients, step-dependent loss scaling, exposure bias, and unreliable classifier calibration. These phenomena collectively heighten catastrophic forgetting and prediction bias, producing unreliable historical knowledge retention and recency effects. The empirical results in the paper reveal that these irregular increments cause severe performance degradation in all major CIL paradigms.
Methodology
The proposed solution is a model-agnostic, modular framework that incorporates both a new generic loss function and targeted adaptations of auxiliary mechanisms used in CIL.
Class-Wise Mean (CWM) Loss Objective
Instead of conventional instance-level averaging (which weights classes by mini-batch frequency and amplifies inconsistencies with variable class counts), the CWM loss averages the per-sample objective within each class, then averages these uniformly across all classes present in the batch. This enforces class-invariant signal propagation, stabilizing gradient updates across steps regardless of the new class count.
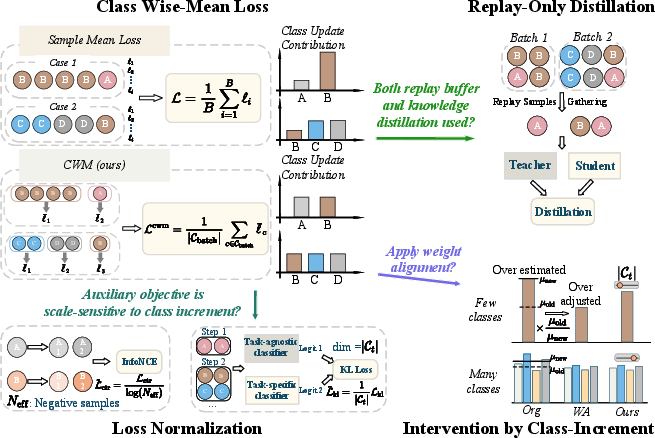
Figure 2: System diagram showing CWM loss for class-invariant updates, replay-only distillation to mitigate bias, scale normalization for auxiliary losses, and DIWA for dynamic calibration.
Adaptations of Auxiliary Losses
- Replay-Only Distillation: Distillation is restricted to replayed old-class samples, avoiding destabilizing gradients from highly variable new-class subsets.
- Scale Normalization: Auxiliary contrastive and knowledge-transfer losses are normalized according to metrics such as the number of valid negatives or dimensionality of newly introduced class subspaces, counteracting scale drift across steps.
- Dynamic Intervention Weight Alignment (DIWA): Conventional weight alignment post-hoc rescaling can induce over-correction when statistics on newly introduced weights are unreliable due to small increments. DIWA adapts the alignment factor based on the number of new classes, increasing alignment strength with increment size, thus mitigating over-calibration and instability.
Empirical Results
Empirical evaluations encompass seven state-of-the-art CIL methods spanning rehearsal, distillation, and dynamic expansion paradigms. Across datasets (CIFAR-100, VTAB, and ImageNet), all baselines experience significant accuracy loss and increased forgetting in FFCIL compared to standard equally partitioned protocols.
Confusion matrix analysis (BiC method) illustrates that FFCIL induces strong prediction biases, especially under-representing recently learned classes.
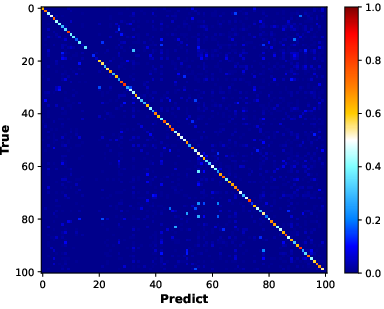
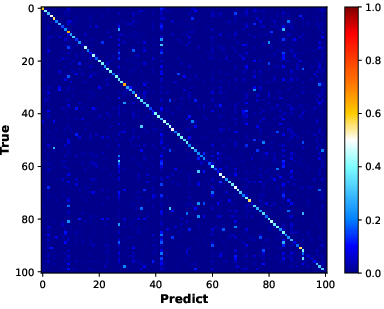
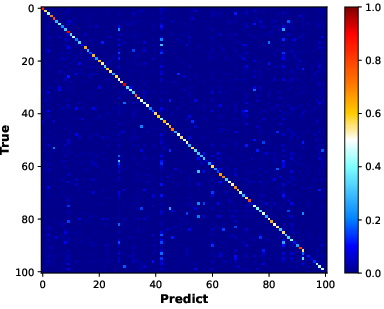
Figure 3: BiC confusion matrices show balanced prediction in equal-split CIL, a recency imbalance and class neglect under FFCIL, and substantial mitigation using the proposed framework.
Step Schedule Sensitivity and Robustness
FFCIL performance is strongly influenced by the step-size schedule:
- Ascending Schedules (increasing class count per step) lead to higher accuracy.
- Descending and Fluctuating Schedules (with either decreasing or highly variable step sizes) exacerbate degradation.
The proposed framework consistently improves accuracy and robustness under all tested schedules for both distillation-based (iCaRL) and expansion-based (DER) methods.
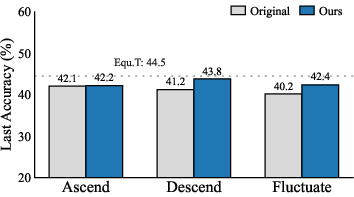
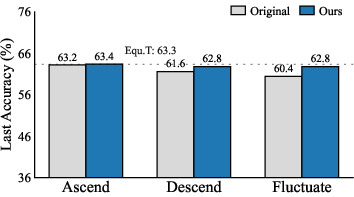
Figure 4: Final accuracy for iCaRL and DER under ascending, descending, and fluctuating FFCIL schedules; proposed framework reduces schedule sensitivity.
In the extreme regime (initial bulk of classes, followed by single-class increments), standard methods undergo catastrophic performance collapse, while the proposed framework preserves stable learning dynamics and mitigates abrupt accuracy loss.
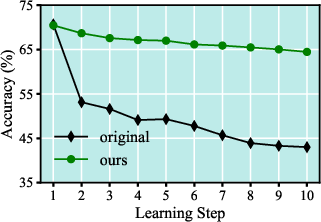
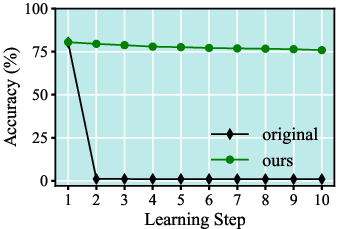
Figure 5: Step-wise CIFAR-100 accuracy under extreme FFCIL scheduling; the framework prevents collapse observed in both DER and TagFex.
Ablation and Efficiency
Ablation studies isolate the contributions of each component (CWM, replay-only distillation, DIWA, normalization) across all paradigms, evidencing that CWM consistently boosts accuracy, and further components yield additive improvements. Importantly, implementation of these components does not increase training runtime and in some cases marginally reduces it due to optimization stability.
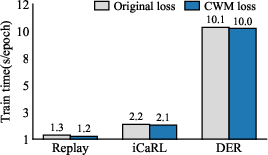
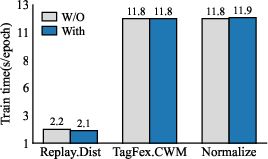
Figure 6: (a) CWM achieves consistent performance gains; (b) auxiliary components further enhance stability; (c) DIWA reduces weight-alignment overhead.
Implications and Future Directions
The formalization of FFCIL exposes a gap between current continual learning methodology and realistic data-generation assumptions. The study demonstrates that model-agnostic structural changes—particularly class-invariant objectives and dynamically regulated calibration—are essential for robust and reliable continual learning systems in non-stationary, unpredictable environments.
Practically, this framework enhances the deployability of CIL methods in production streaming and deployment scenarios, such as open-set recognition, security monitoring, or lifelong robotics, where class discovery is asynchronous and sparse.
Theoretically, the results motivate deeper investigation into loss function invariances, adaptive post-hoc calibration, and task-agnostic auxiliary objectives. Future research could advance adaptive architectures or curriculum strategies explicitly tailored for dynamic, unbounded class arrival distributions.
Conclusion
The introduction of Free-Flow Class-Incremental Learning (FFCIL) underscores the necessity for continual learning systems to operate under realistic, variable class increment scenarios. Across diverse CIL paradigms, FFCIL induces significant instability, best addressed by the proposed framework comprising class-wise mean losses, replay-only distillation, normalization, and dynamic weight alignment. These strategies yield consistent empirical gains and point toward the next generation of continual learning systems robust to genuine data stream irregularities.
Reference:
"Towards Realistic Class-Incremental Learning with Free-Flow Increments" (2604.02765)

