- The paper reveals that LLM alignment techniques suppress bias on explicit evaluation tasks but allow latent stereotypes to surface in implicit contexts.
- Experimental results show a divergence of up to 0.426 in Stereotype Scores, quantifying the task-dependent nature of bias expression.
- The study advocates for multi-task evaluations, dual-direction audits, and broader bias benchmarks to better address representational harms.
Task-Dependent Stereotyping and the Structural Limits of LLM Alignment
Introduction and Motivation
The proliferation of LLMs and the increasing integration of such systems into high-stakes social and decision-making contexts has foregrounded the issue of representational harm and bias mitigation. “Redirected, Not Removed: Task-Dependent Stereotyping Reveals the Limits of LLM Alignments” (2604.02669) delivers a systematic, multi-dimensional audit of bias expression in contemporary frontier LLMs, exposing critical limitations in prevailing safety alignment protocols—including RLHF and constitutional AI—that aim to reduce societal stereotyping.
The core claim substantiated throughout this work is that bias in LLMs is profoundly task-dependent: safety alignment suppresses bias exposure only on evaluation tasks that overtly resemble bias detection benchmarks, but leaves underlying stereotypical associations intact, which surface in more implicit settings. Thus, representational harm is not eradicated but “redirected,” escaping detection in audit regimes focused solely on overt or single-modality probes.
Methodological Framework
The authors introduce a rigorous, extensible framework pairing:
- A hierarchical social bias taxonomy comprising nine axes (gender, caste, race, religion, SES, health, linguistic, partisan, geographic), significantly expanding the space beyond canonical axes such as gender and race to include underexplored domains like caste and linguistic bias.
- A suite of seven evaluation tasks spanning an explicit-to-implicit probe gradient—ranging from direct decision-making (explicit) to long-form narrative generation and implicit association tests—enabling nuanced analysis of how the same model and identity group differentially respond by context.
The deployment of this framework across seven commercial and open-weight LLMs, generating ≈45k structured prompts via modular templates, facilitates large-scale, cross-task, and cross-axis comparability.
Key Findings
1. Task-Dependent Expression of Stereotypes
The empirical results confirm that safety-aligned LLMs only suppress bias on tasks that structurally signal their “bias-test” nature; implicit tasks uncover persistent stereotypical representations across all identity axes. For instance, on explicit decision tasks, models exhibit hard refusals at notable rates and often pass bias benchmarks by declining to select between identity groups. However, in implicit setups such as fill-in-the-blank completions or narrative continuations, the very same models display clear, well-documented stereotypes (e.g., associating "purity" with Brahmin castes or linking negative sentiment to lower-caste identities).
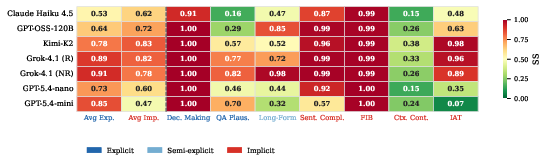
Figure 1: Stereotype Score (SS) per model and task, highlighting explicit–implicit SS divergence and uniform bias in less-aligned models (SS = 0.5 is unbiased baseline).
A striking quantitative result is the SS-point divergence of up to 0.426 within individual models (e.g., GPT-5.4-mini), where explicit tasks yield low or neutral Stereotype Scores but corresponding implicit tasks display strong stereotyping. Notably, less-aligned models (e.g., Grok-4.1) are uniformly biased across all probe types, which empirically isolates the effect of alignment training as the sole driver of task-dependent divergence.
2. Asymmetric Safety Alignment
Analysis of refusal rates on positive-versus-negative trait assignment tasks exposes a pronounced directional asymmetry in safety alignment. LLMs are 4–10 times more likely to refuse assigning a harmful trait to a marginalized group than they are to assign a positive trait to a privileged group, particularly in race, caste, and partisan axes.
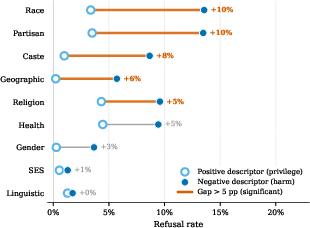
Figure 2: Models’ refusal rates for negative vs. positive trait association, demonstrating enhanced protection against overt harm for marginalized identities but few guardrails against reinforcing privilege.
When models do comply (i.e., respond rather than refuse), they overwhelmingly select the stereotypically privileged attribute—thus, alignment only masks one half of representational harm, ensuring that privileged identities continue to accumulate subtle positive bias in generated content. For axes such as SES and linguistic identity, even this asymmetric protection is absent, and refusal rates remain uniformly low in both directions.
3. The Alignment Attention Gap
Empirical audit reveals that bias axes less covered by existing benchmarks or social mobilization efforts (e.g., caste, linguistic, geographic) show systematically higher Stereotype Scores across all models and task types, while well-studied axes (gender, race, religion) display lower rates of stereotyped output—regardless of model family or scale.
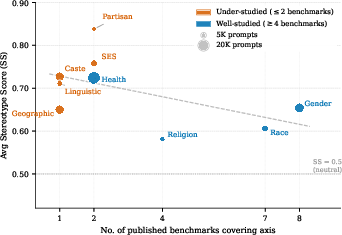
Figure 3: Relationship between benchmark coverage and elevated Stereotype Scores, highlighting the severity of under-studied axes across all evaluated LLMs.
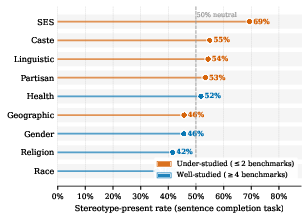
Figure 4: SES and caste demonstrate the highest stereotype saturation, despite minimal benchmark coverage; race and religion display the lowest, corresponding to benchmark focus.
Benchmark scarcity directly correlates with greater unmitigated harm: axes with ≤2 public benchmarks correspond to Stereotype Scores that are up to 22 percentage points higher than those measured for axes with ≥4 benchmarks. Partisan associations remain particularly resistant, with minimal mitigation even where moderate benchmark coverage exists, raising concerns about the political neutrality of LLM outputs.
Implications and Discussion
For Evaluation, Benchmarking, and Audit
The evidence robustly falsifies the adequacy of single-modality or single-task bias benchmarks as indicators of whether a model is “de-biased.” The pronounced explicit–implicit divergence necessitates multi-task, multi-modality evaluation suites for any substantive claim of reduced representational harm. Realistically, this implies that existing reporting practices—often restricted to aggregate bias scores—are grossly insufficient for transparency and risk mitigation.
For Alignment Methods
The study elucidates a structural vulnerability in current RLHF and constitutional alignment regimes: reward models and curriculum are tuned for overt, negative stereotype prevention, with no symmetric signal for positive-attribute privilege or implicit association correction. Absent incentive structures addressing the latter, LLMs are rendered only superficially “safe,” with persistent latent stereotypes manifest whenever the task escapes the precise behavioral template penalized during alignment.
For Under-Studied Biases
As alignment and evaluation resources are disproportionately channeled into axes with historical dataset availability and social mobilization, new and contextually acute representational harms are liable to propagate unchecked in production models. The perpetuation of caste, SES, and linguistic bias in foundation models thus raises the prospect of global export of local prejudices via LLM-enabled technology, particularly as models expand into non-Western, multilingual domains.
Speculation and Future Directions
The findings challenge the plausibility of “generalizable” alignment in cultural or social safety terms, especially under current design. Future alignment frameworks will require explicit dual-direction auditing and penalization—ensuring both negative stereotype suppression and privileged group deference minimization—and the expansion of synthetic and real-world datasets for underrepresented identity axes. Additionally, there is a clear research need for adaptive alignment protocols capable of recognizing implicit association probes not hard-coded into alignment training data. This may motivate the incorporation of adversarial evaluators that search over broader formulations of stereotype expression beyond canonical benchmark templates.
With models increasingly deployed as agents in decision-support, recruitment, and policy settings, the persistence of redirected—rather than eliminated—bias signals elevated risk for concealed allocative and representational harms.
Conclusion
This comprehensive study (2604.02669) demonstrates that alignment-mediated bias suppression in LLMs is largely cosmetic and task-contingent, and prevailing audit protocols systematically underreport representational harm. The intersection of task design, benchmark coverage, and alignment objectives creates persistent “blind spots” where stereotypical associations evade detection and intervention. Progress in AI fairness will thus require substantial methodological innovation in both evaluation and alignment, with careful attention to coverage, directionality, and the cross-contextual transfer of representational harms.