- The paper introduces a time-warping method that adjusts LSTM forget and input gate biases to transfer learned dynamics between systems with different time scales.
- Empirical results on fuel moisture prediction demonstrate that tuning only 128 bias parameters achieves performance comparable to full fine-tuning, reducing overfitting in sparse data regimes.
- The approach is grounded in theoretical proofs linking bias shifts to dynamical system behavior, ensuring interpretable and efficient transfer learning.
Time-Warping Recurrent Neural Networks for Transfer Learning
Introduction and Theoretical Motivation
"Time-Warping Recurrent Neural Networks for Transfer Learning" (2604.02474) presents a novel theoretically-motivated framework for transfer learning in sequence models, targeting explicit manipulation of learned RNN time-scale parameters. The core idea is formalized as a "time-warp": systematically adapting RNN parameters—specifically LSTM forget and input gate biases—so that a model learned on a source time-scale effectively transfers its dynamics to target systems with different intrinsic rate-of-change characteristics. This approach is positioned as an alternative to standard fine-tuning or layer freezing, providing a minimal and interpretable parameter adaptation with the potential for strong generalization, especially in data-sparse targets.
The paper begins by situating the underlying motivation within classical modeling of physical dynamical systems, emphasizing the notion that many real-world systems are governed by identical dynamics but operate at varying characteristic time scales (i.e., relaxation or lag parameters). This invariance under temporal rescaling is formalized via the "time-warp" operation, mapping a source ODE or discrete system to a family of transformations indexed by a positive real number γ (time-warp constant). The resulting change in the discrete-time update equations has an explicit effect on the parameters driving state-persistence versus responsiveness.
Theoretical Results: LSTM Time-Warpability
A foundational theoretical section establishes several propositions linking time-warping of linear first-order dynamical systems (discrete ARX/AR(1)-like; zt=azt−1+(1−a)Xt) with LSTM parameterization. First, the authors prove explicitly that:
- A simple RNN with linear activation can exactly reproduce such systems, and that time-warping (exponentiating a to aγ) is achieved by analogous parameter transformations (Propositions 1-2).
- For practical RNNs with tanh activations, rescaling produces arbitrarily accurate approximations on finite sequences by leveraging the locally linear region of tanh (Proposition 3).
- For LSTM architectures with linear (rather than tanh) activation at candidate and output (for tractability), there exist explicit settings of forget/input gate biases to reproduce the lag system and, crucially, time-warped versions thereof (Propositions 4-5). The parameter shifts are governed by logit transformations of a and $1-a$.
The implications are that pretrained LSTMs operating on a source time-scale can, at least for systems well-approximated by first-order linear dynamics, be "time-warped" to a target time-scale by analytically shifting just two parameters—the biases for the forget and input gates. These modifications alter the relative weightings of previously retained state (ct−1) versus new input (gt via it), thereby changing the "memory" of the model in a controlled and physically interpretable manner.
Methodology: Time-Warping as Transfer Learning
Building on the theory, the practical methodology proposed involves:
- Given a pretrained LSTM, introduce two time-warping parameters, αf and αi, directly shifting the forget and input gate biases post-training: a0, a1.
- For a given transfer learning task (with possibly very limited target data), tune only a2 and a3 via grid search with or without fine-tuning (full model, partial freezing, or only the two bias shifts), using the target data for selection.
- This method modifies only 128 (for 64-unit LSTM: forget and input gate per unit) out of 21,000+ parameters, minimizing the risk of overfitting versus full fine-tuning on small data.
Notably, the method is inherently interpretable: positive (negative) shifts to the forget gate bias increase (decrease) recurrence—i.e., slow down (speed up) the memory decay—while corresponding changes to the input gate bias adjust how strongly new input affects the state update. As shown in simulation, these effects are observed in induced autocorrelation structure and response speed of the network.
Empirical Validation: Fuel Moisture Content from Wildfire Science
The empirical application is in prediction of fuel moisture content (FMC) across multiple classes (FM1, FM10, FM100, FM1000), which in wildfire modeling, are parameterized by characteristic time lags (from fast-responding fine fuels to slow-responding heavy fuels). The dataset is typical for environmental science: vast amounts of data for FM10, but severe sparsity for other classes.
The main experimental design is as follows:
- Pretrain a deep LSTM RNN model on abundant FM10 data (from weather-driven sensors and NWP), validated to outperform physical models and ML baselines for FM10.
- For FM1, FM100, and FM1000, transfer via (a) no transfer (from scratch training), (b) classical fine-tuning (full/unfrozen), (c) variants with frozen layers, and (d) time-warping (bias-only shift; no fine-tune, or with fine-tune).
- Only small field-study datasets are available for the target tasks—consistent with the practical motivation.
- For each approach, aggregate RMSE, bias, and a4 across multiple training replications (random seeds, splits).
Strong stability in the source-model bias parameter distributions was confirmed across replications (see below).
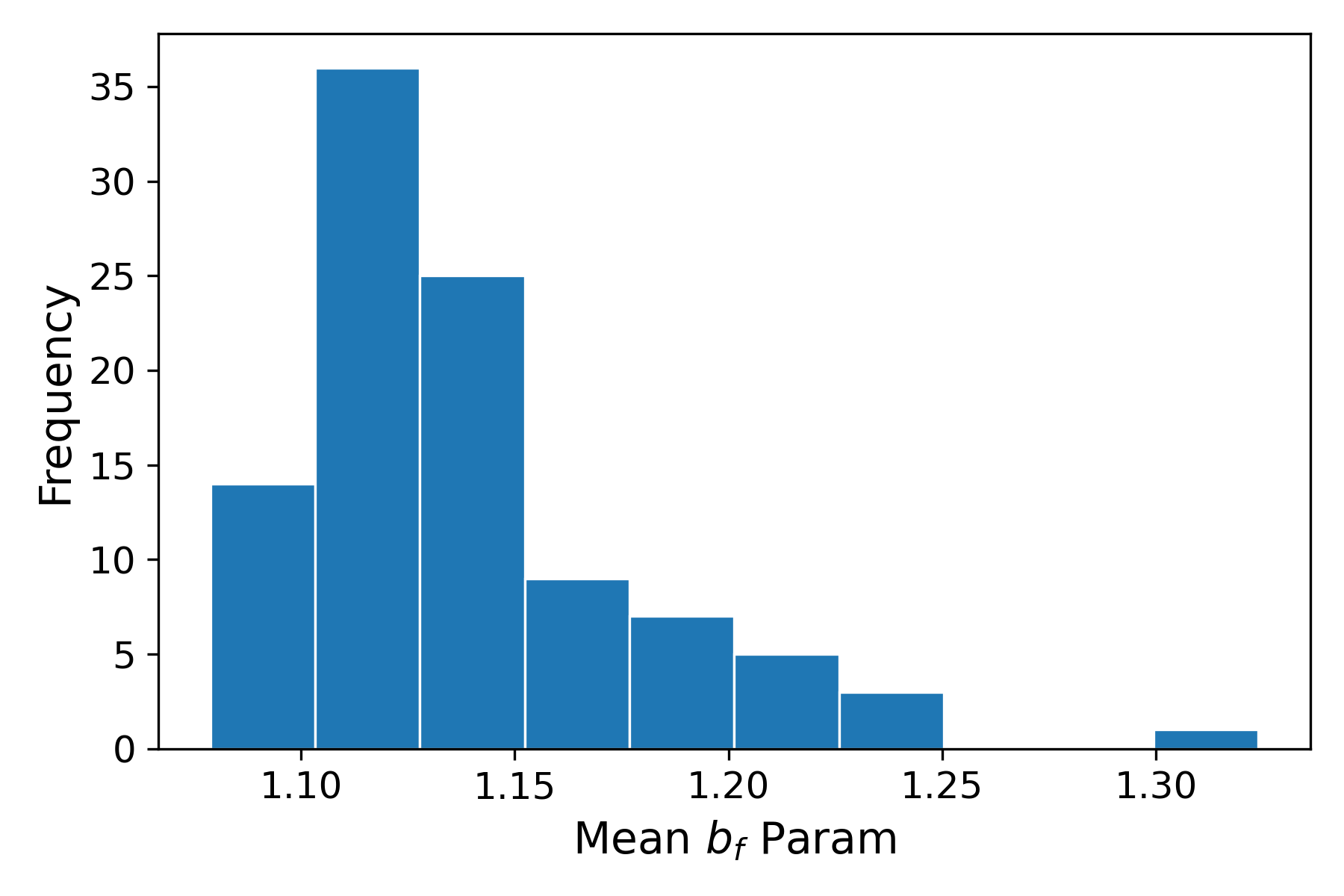
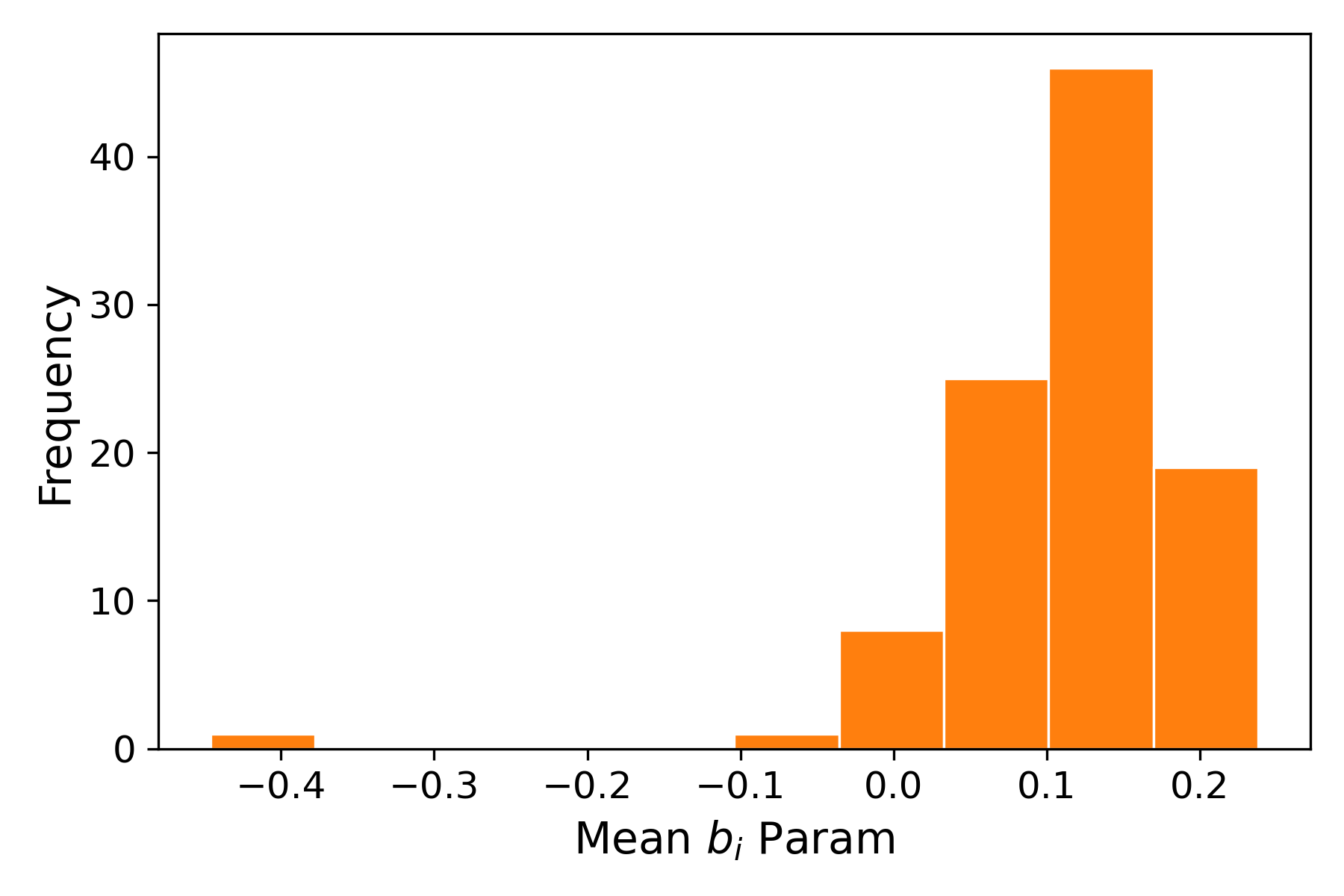
Figure 2: Distribution of the mean LSTM forget (a5) and input (a6) gate biases for the pretrained FM10 model across 100 training replicates shows convergence and low variance across training runs.
The time-warping approach yields strong numerical performance, competing with or closely matching full fine-tuning, and dramatically outperforming baselines in data-scarce settings—even though only 128 bias parameters are adjusted. Notably:
- For FM1 (after removing pathological wet observations), time-warping attains RMSE within 0.1–0.4 % (absolute) and a7 within 0.01 of the best methods.
- For FM100/FM1000, results are similar: time-warping delivers test RMSE not statistically different from full fine-tune or dense-layer-only fine-tune.
- The signs and relative magnitude of the optimal bias shifts (a8, a9) empirically agree with the theoretical predictions (decrease forget/increase input for shorter lags; Figure 2 and related tables cited in the text).
Analysis of Temporal Effects
To examine the actual impact of bias-shifting, temporal structure in the output sequences was systematically characterized using autocorrelation and partial autocorrelation functions (ACF, PACF). Plots show:
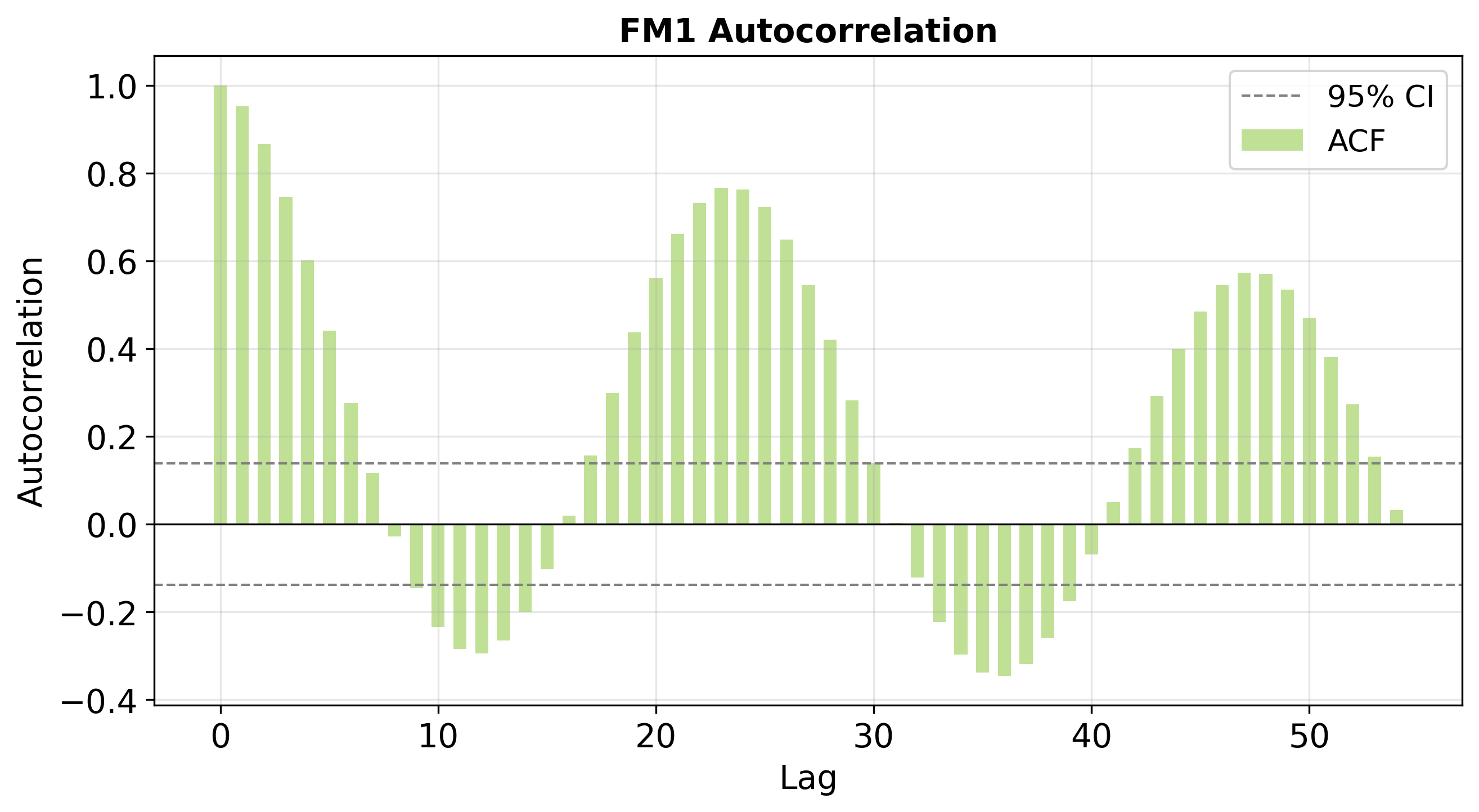
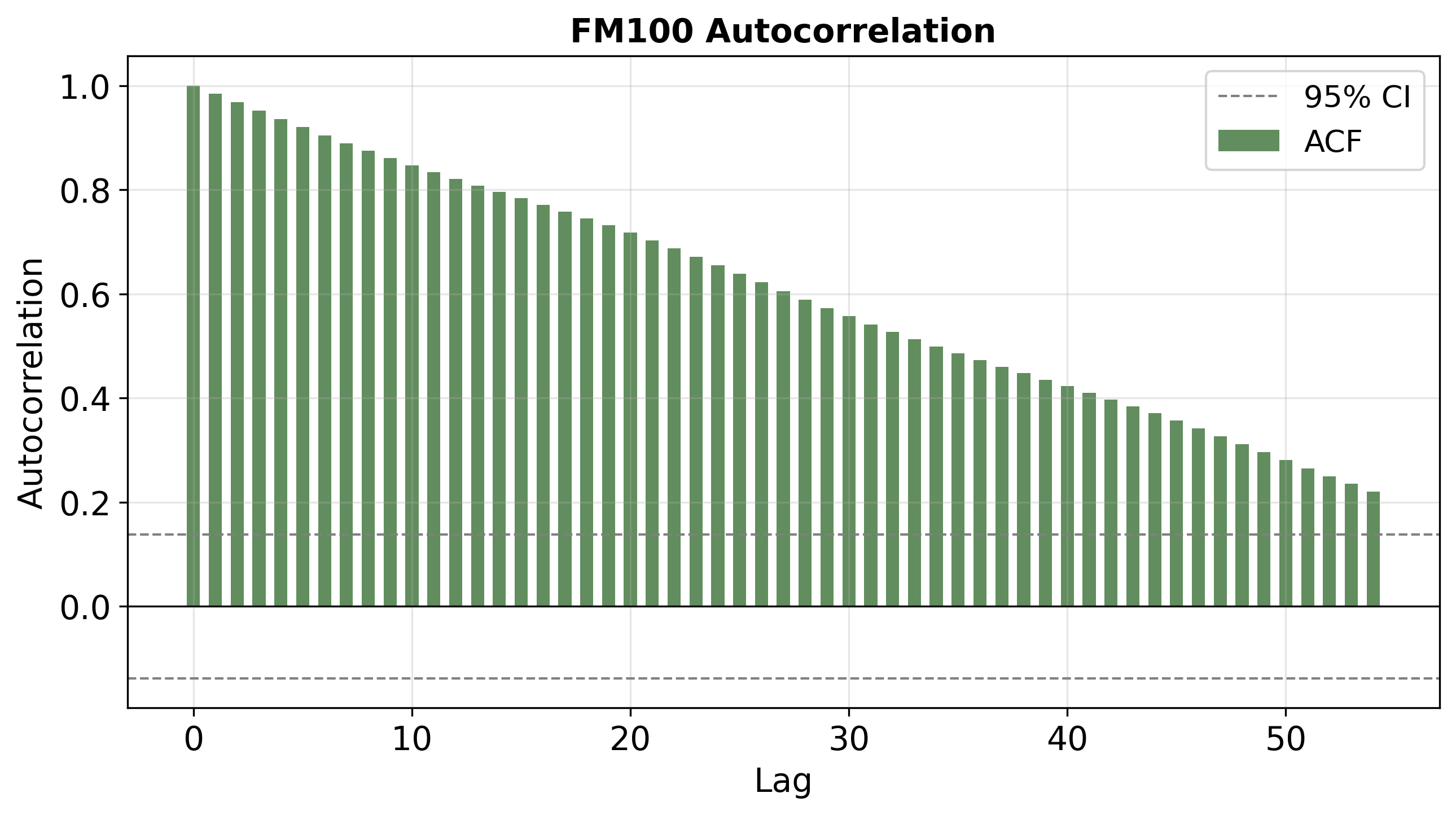
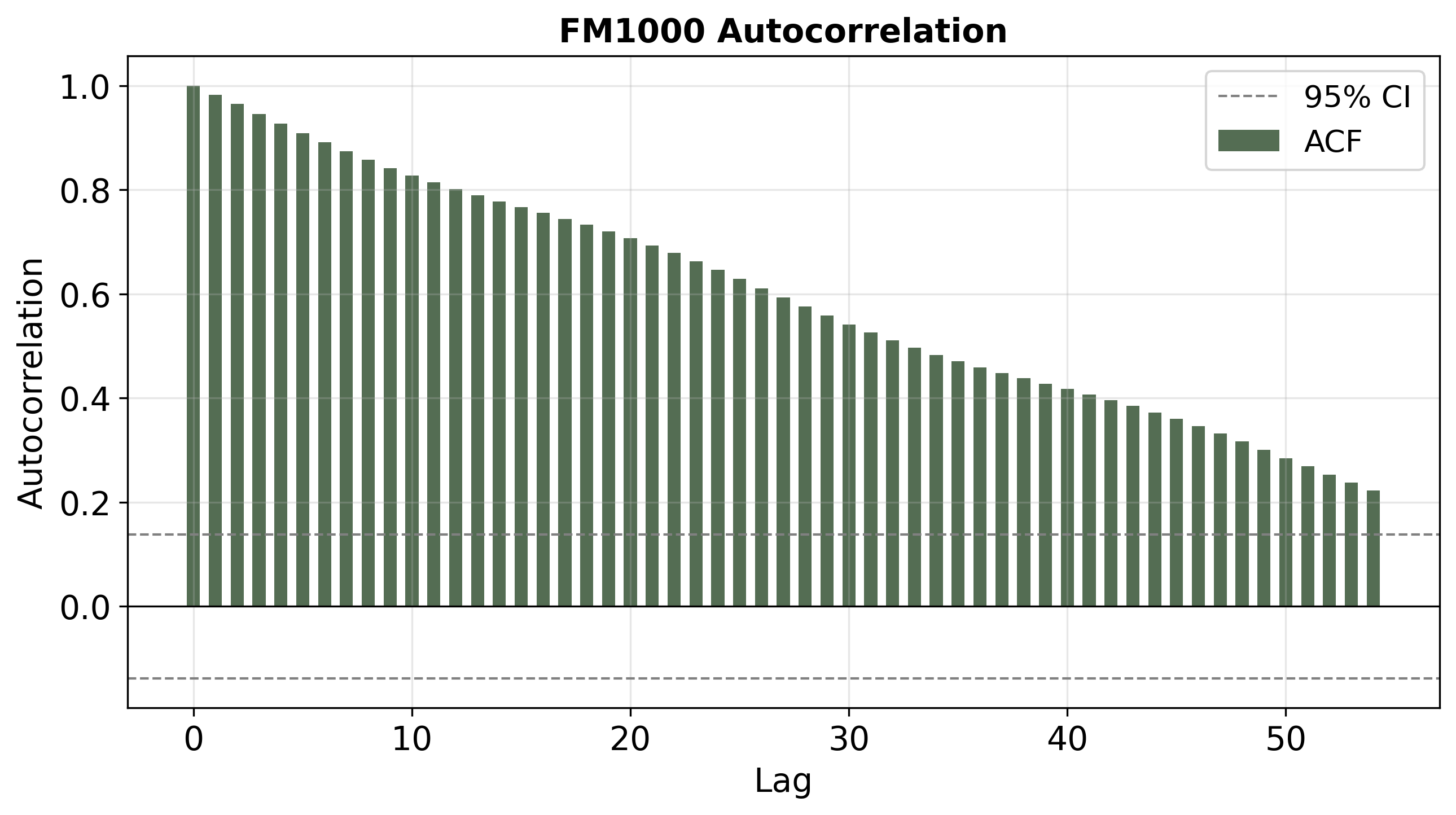
Figure 4: ACFs for predictions on FM1 (top), FM100 (middle), and FM1000 (bottom). FM1 shows rapid ACF decay and strong diurnal periodicity, while FM100/FM1000 predictions have much slower ACF decay, representing long "memory" consistent with large time-lag fuels.
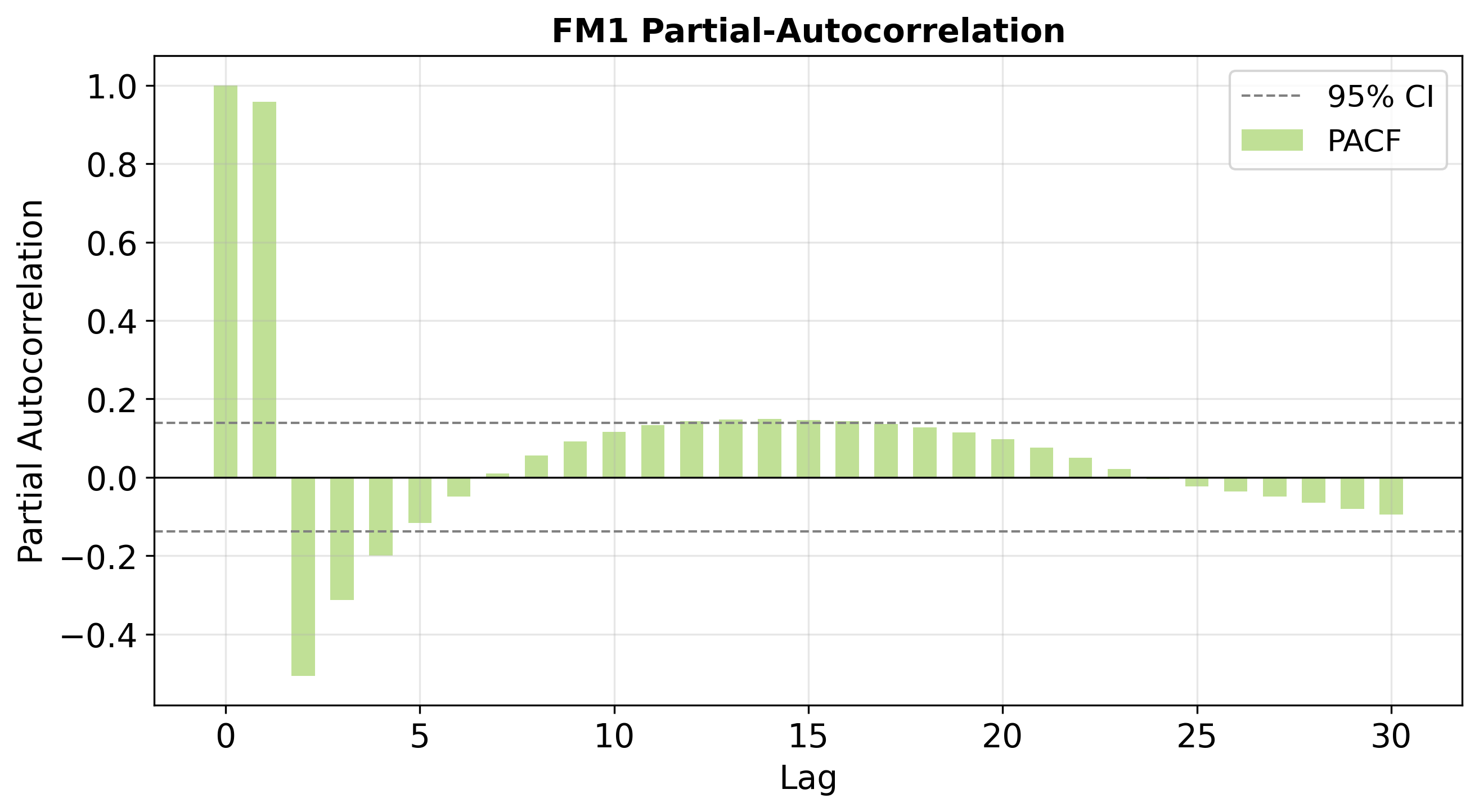
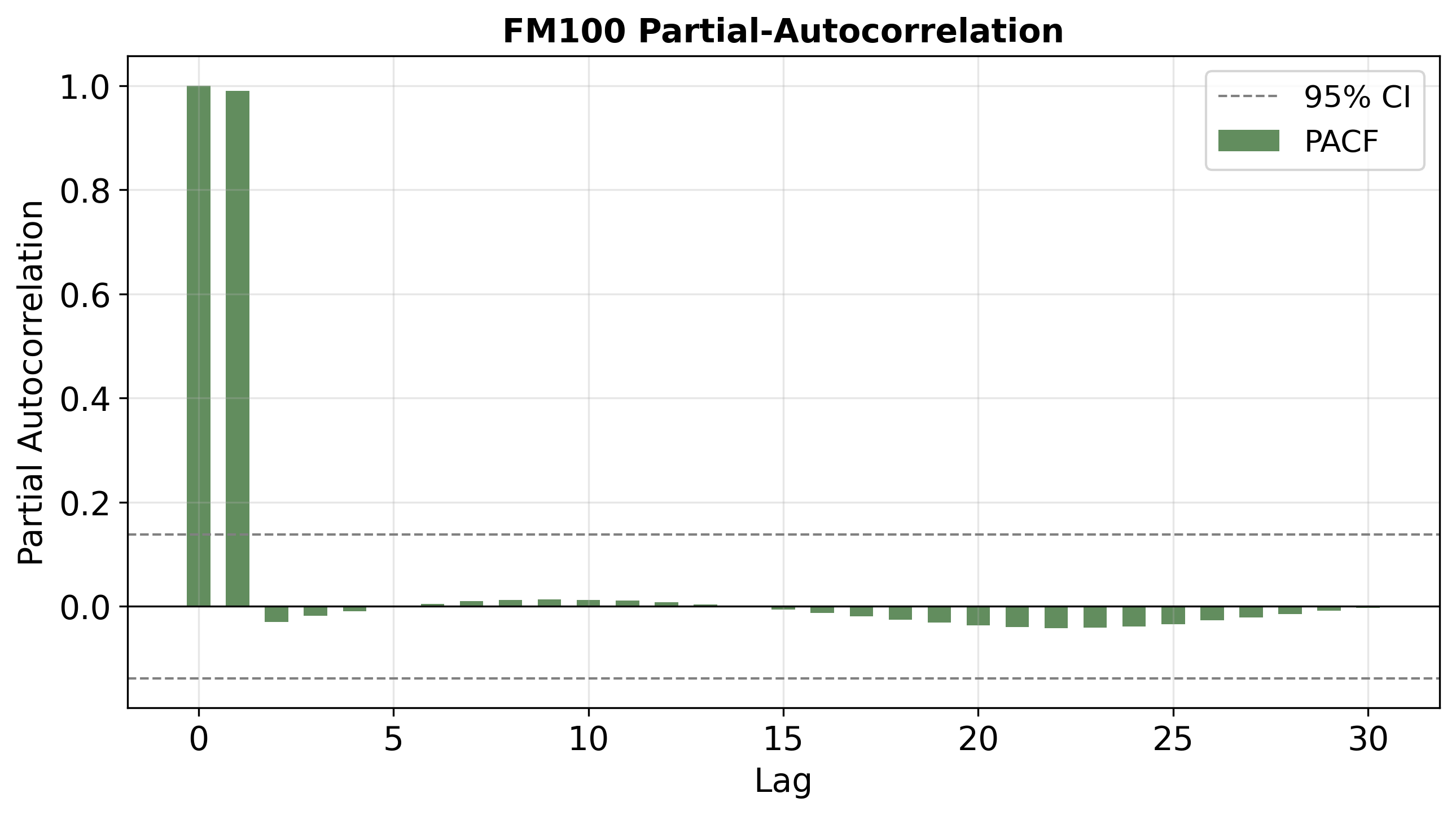
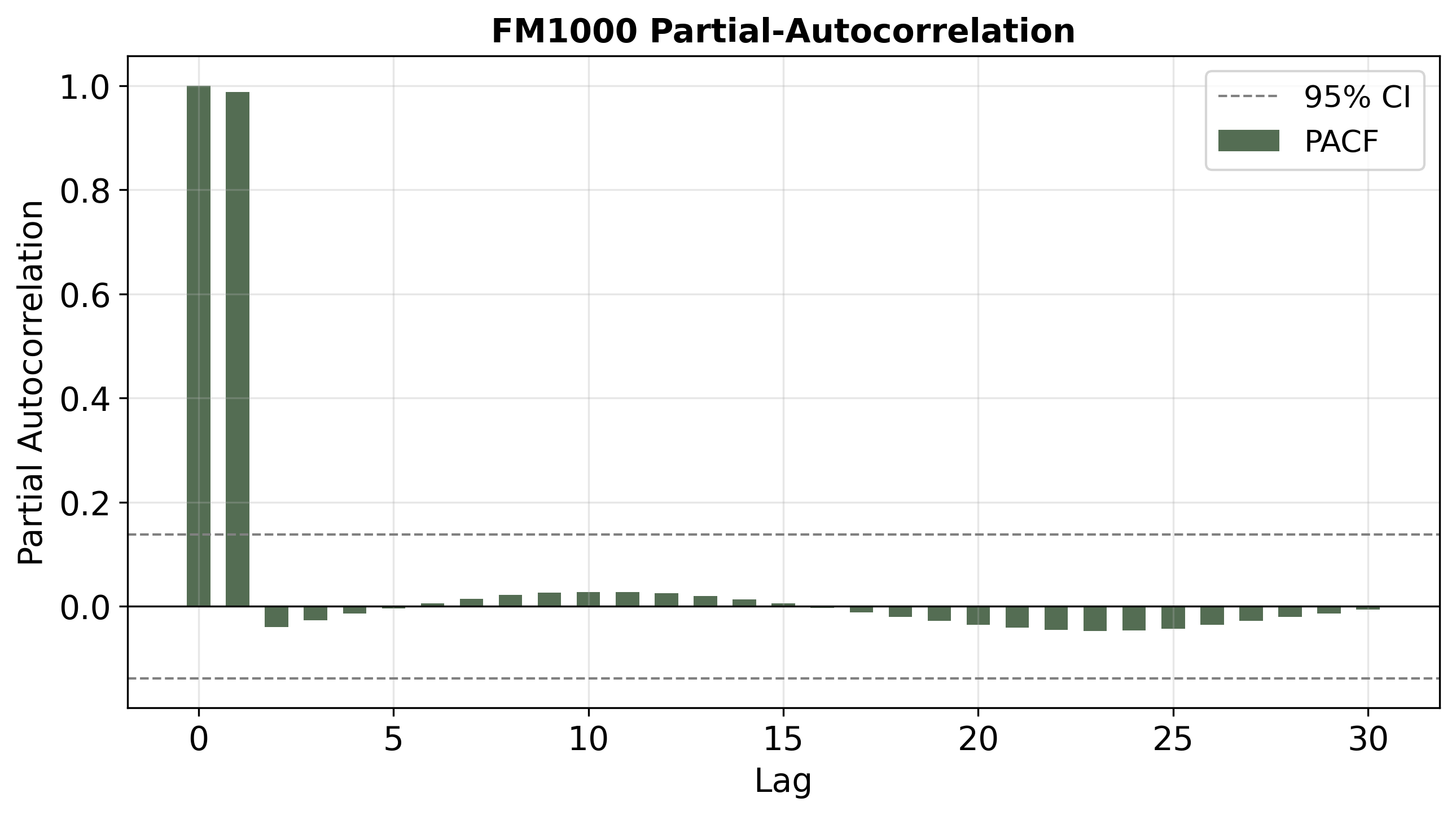
Figure 6: PACFs for FM1, FM100, and FM1000 predictions reveal that post-warp, FM100(/FM1000) display the expected dominant lag-1 effect, with negligible partial autocorrelation at higher lags (AR(1)-like), unlike FM1 which shows shorter persistence.
These alignments confirm that bias shifting within the LSTM can controllably alter the network's implicit time-scale of memory, yielding prediction series conformant with the target class's physical characteristics.
Distributional Robustness and Learned Parameter Structure
Detailed statistical analysis demonstrates that, regardless of random initialization or training variance, the trained models converge to tightly-clustered distributions over bias values for both gates and their difference. This convergence is necessary for the soundness of the time-warping intervention, as the key theoretical results depend on homogeneity of learned dynamics.
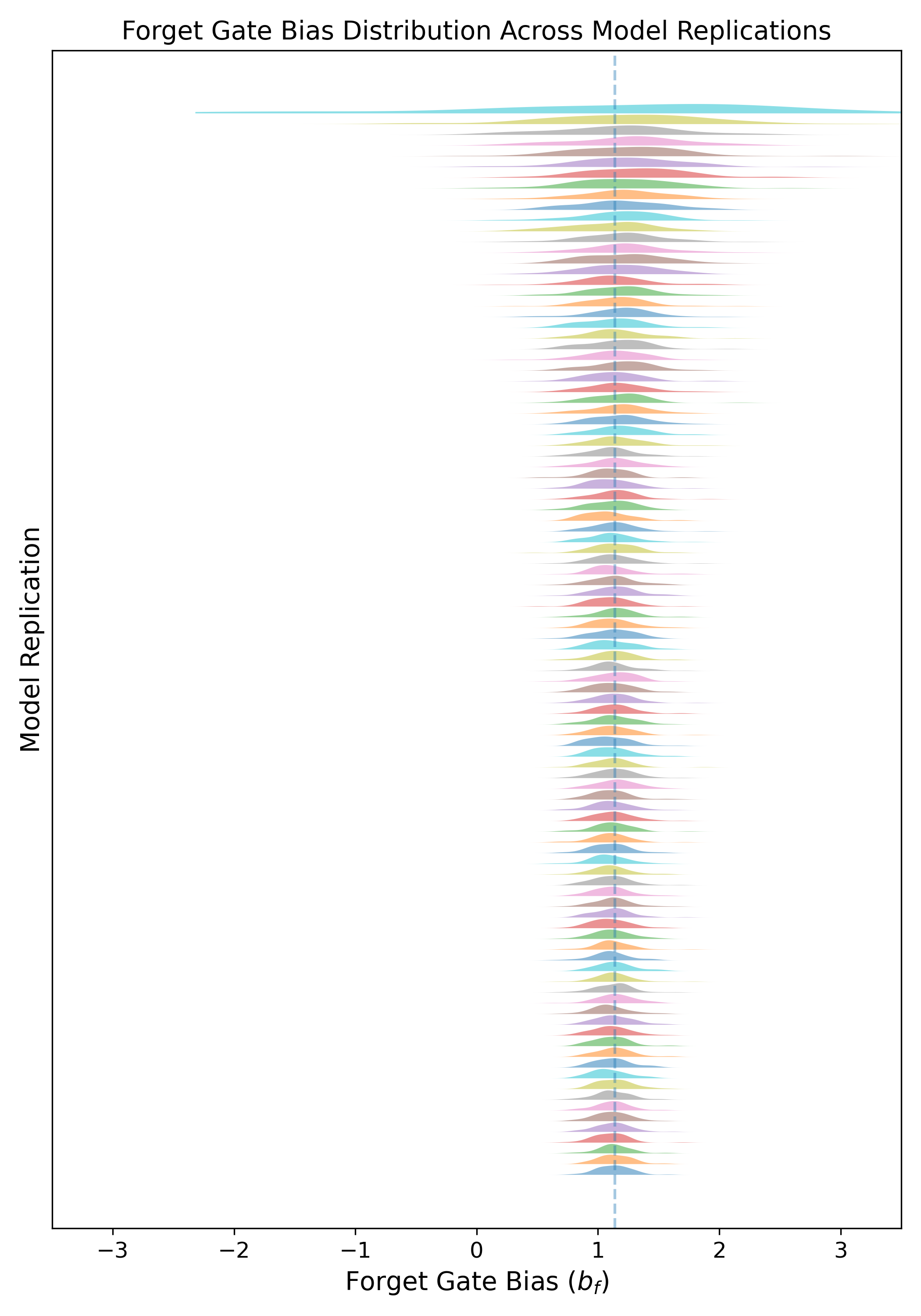
Figure 8: Distribution of forget gate biases across 100 replications showing narrow variance and consistent central tendency.
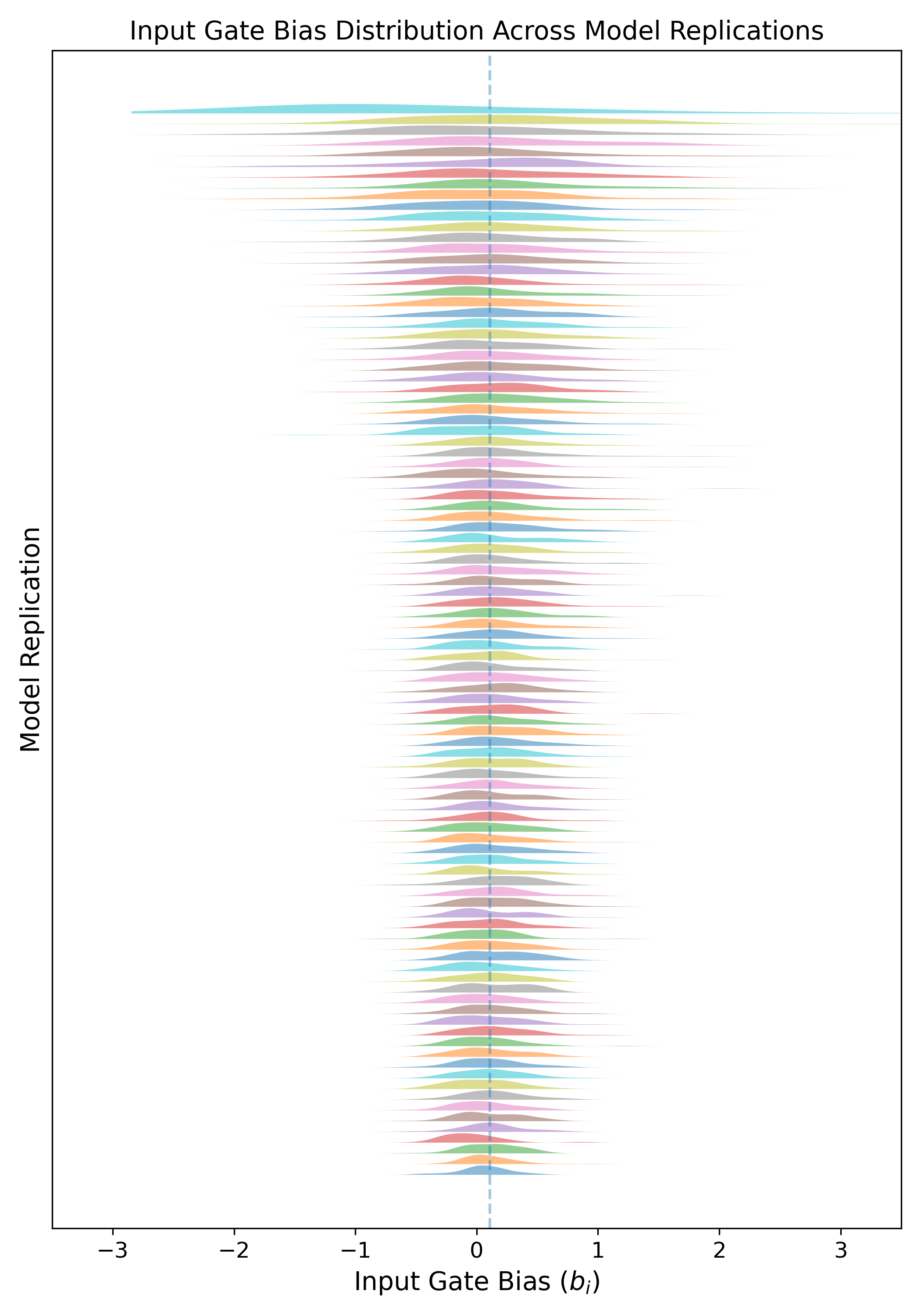
Figure 10: Distribution of input gate biases across 100 replications showing higher but still controlled variance compared to forget biases.
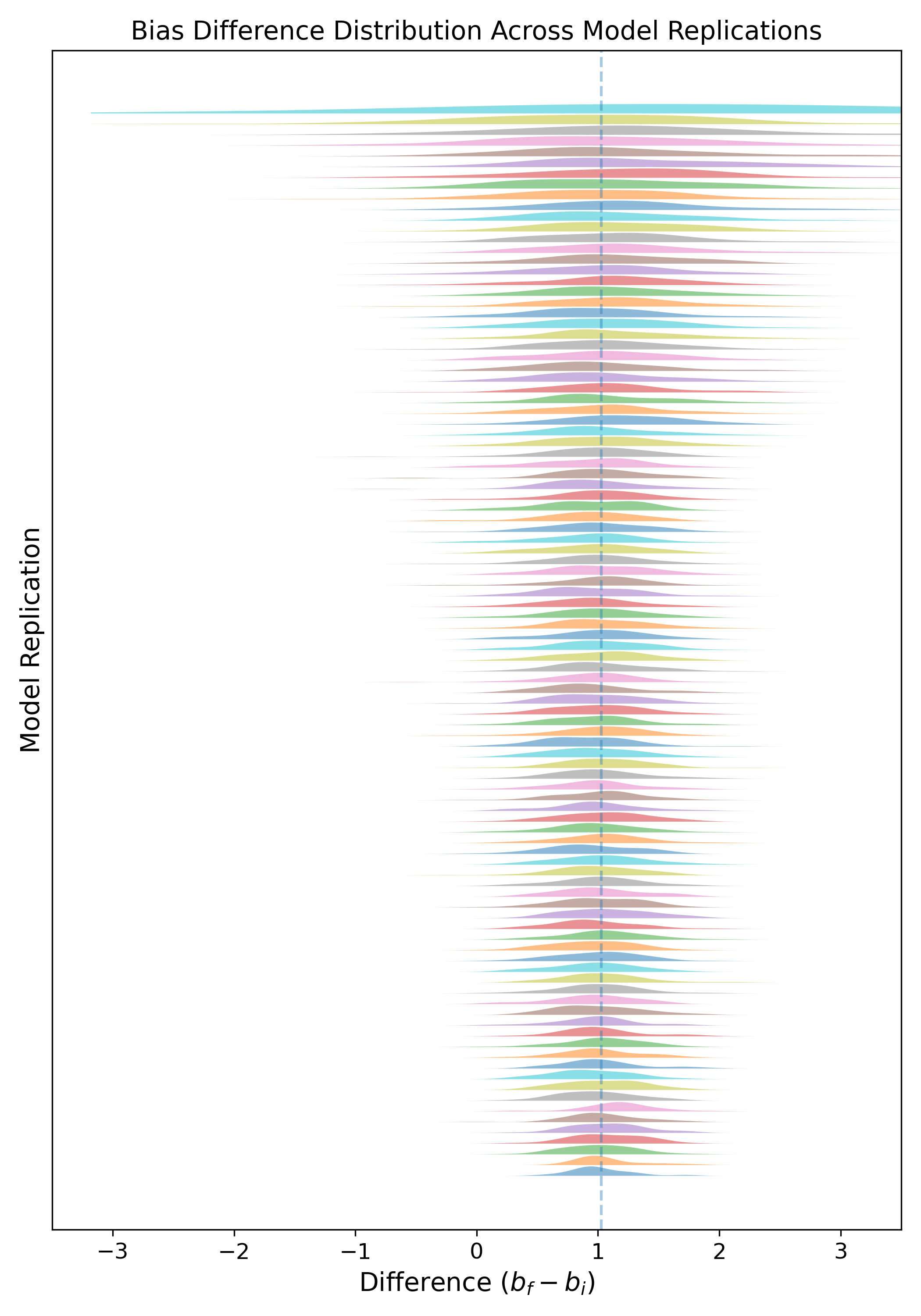
Figure 12: Per-unit difference between forget and input gate biases demonstrates a stable, unimodal distribution supporting the theoretical design of the time-warp operation.
Collectively, these confirm that the hypothesized coupling between parameter distributions and emergent time-scale is preserved and is amenable to systematic, interpretable post-hoc modification.
Practical and Theoretical Implications
This work offers several key implications:
- Minimal, Theory-Guided Transfer: Directly warping gate biases allows physically-motivated, extremely low-dimensional adaptation—mitigating overfitting typical of fine-tuning with small target data and making the method suitable for high-cost/sparse measurement applications.
- Interpretable Latent Timescale Manipulation: Unlike generic fine-tuning, the impact of changes is analytically predictable, bridging traditional physical models and deep learning.
- Framework Generalization: Though the main results hold provably only for (near-)linear lag systems, empirical findings in the context of nonlinear, high-dimensional RNNs remain robust—suggesting applicability to other physical sequence modeling tasks.
- Diagnostic Utility: Emergent temporal properties can be interrogated via ACF/PACF analysis, providing tools for model selection, validation, and debugging.
Future Directions
The method's efficacy in this work prompts further lines of inquiry:
- Zero-shot extrapolation: Grid searches over (aγ0, aγ1) could be tied to canonical physical parameters, enabling continuous extrapolation/interpolation across unobserved time-scales/classes (e.g., predicting for hypothetical fuel classes).
- Extensions to Neural ODEs and Nonlinear Manifolds: Investigating the interplay with neural ODEs, which allow continuous, differentiable vector-field warping, could increase the expressivity/applicability of the time-warp technique.
- Adaptive or Heterogeneous Time-Warping: Allowing learned, unit-wise, or input-conditioned time-warping could further enhance transferability for non-homogeneous target domains.
Conclusion
The study rigorously establishes, both theoretically and empirically, that post-hoc time-warping of LSTM biases offers an effective, interpretable, and data-efficient method for transfer learning across dynamical systems with different intrinsic rates. The approach maintains or improves empirical accuracy versus standard baselines, with an order-of-magnitude reduction in the number of adapted weights and robust theoretical underpinnings. These results highlight the feasibility and value of incorporating prior structural knowledge into deep sequence model transfer methods, with immediate practical benefits for environmental modeling and beyond.