- The paper demonstrates an all-optical photonic CNN that executes convolution, pooling, and activation entirely in the optical domain, eliminating optoelectronic conversions.
- It employs a hybrid training approach combining a digital twin for ex-situ gradient optimization with in-situ SPSA fine-tuning, achieving 96.92% accuracy on MNIST digitally and 94.23% on hardware.
- The system delivers a 100–242× energy efficiency boost and 0.8 μs inference latency, highlighting its potential for scalable, low-power edge AI applications.
Photonic Convolutional Neural Network with Pre-Trained In-Situ Training: Architectures, Methods, and Results
Introduction
This work presents a fully coherent photonic convolutional neural network (PCNN) capable of executing all core CNN operations—including convolution, max pooling, and nonlinear activation—entirely in the optical domain. Unlike prior photonic neural networks that interleave optical and electronic domains, necessitating frequent optoelectronic conversions, this architecture maintains the signal in the photonic domain throughout, thereby minimizing latency and maximizing energy efficiency. The authors introduce novel silicon photonics subsystems (e.g., wavelength-division-multiplexed pooling and microring resonator nonlinearities), an exact digital twin for ex-situ gradient-based training, and in-situ fine-tuning via the SPSA algorithm mapped to physical phase shifters. Validation includes system-level robustness analysis, power/latency profiling, and benchmarking against high-efficiency state-of-the-art GPUs.
Photonic Architecture and Implementation
The PCNN architecture maps standard CNN computational primitives onto silicon photonic devices:
- Convolutional layers are realized using rectangular Clements mesh MZI arrays (termed CMXU here), providing 2,132 individually tunable thermo-optic phase shifters. Depthwise and pointwise convolutions are supported for feature extraction and representation.
- All-optical pooling leverages a combination of multimode interferometers, bistable resonator-based circuits, and GST-based phase change attenuators for max pooling, eliminating O/E/O bottlenecks.
- Wavelength-division multiplexing (WDM) in pooling enables concurrent processing across eight spectral channels, optimizing parallel throughput.
- Activation (NOFU) is implemented with high-Q microring resonators exploiting carrier-injection nonlinearities.
- Fully connected layers are photonics-composed using a hierarchy of weighted MMIs and MZIs.
The fully integrated architecture is monolithic, and each of its 2,132 tunable weights directly maps to physical hardware parameters—circumventing decomposition or transformation losses.
Hybrid Training: Differentiable Digital Twin and In-Situ SPSA
On-chip gradient backpropagation is precluded by physical constraints of photonics hardware, so the authors employ a hybridized training methodology.
- Ex-situ training: A PyTorch-based digital twin is rendered, mathematically modeling every photonic function (loss, clipping, delay, and activation) with high fidelity. This digital twin achieves absolute parity (<10−15 difference) with the simulated hardware, enabling exact parameter transfer.
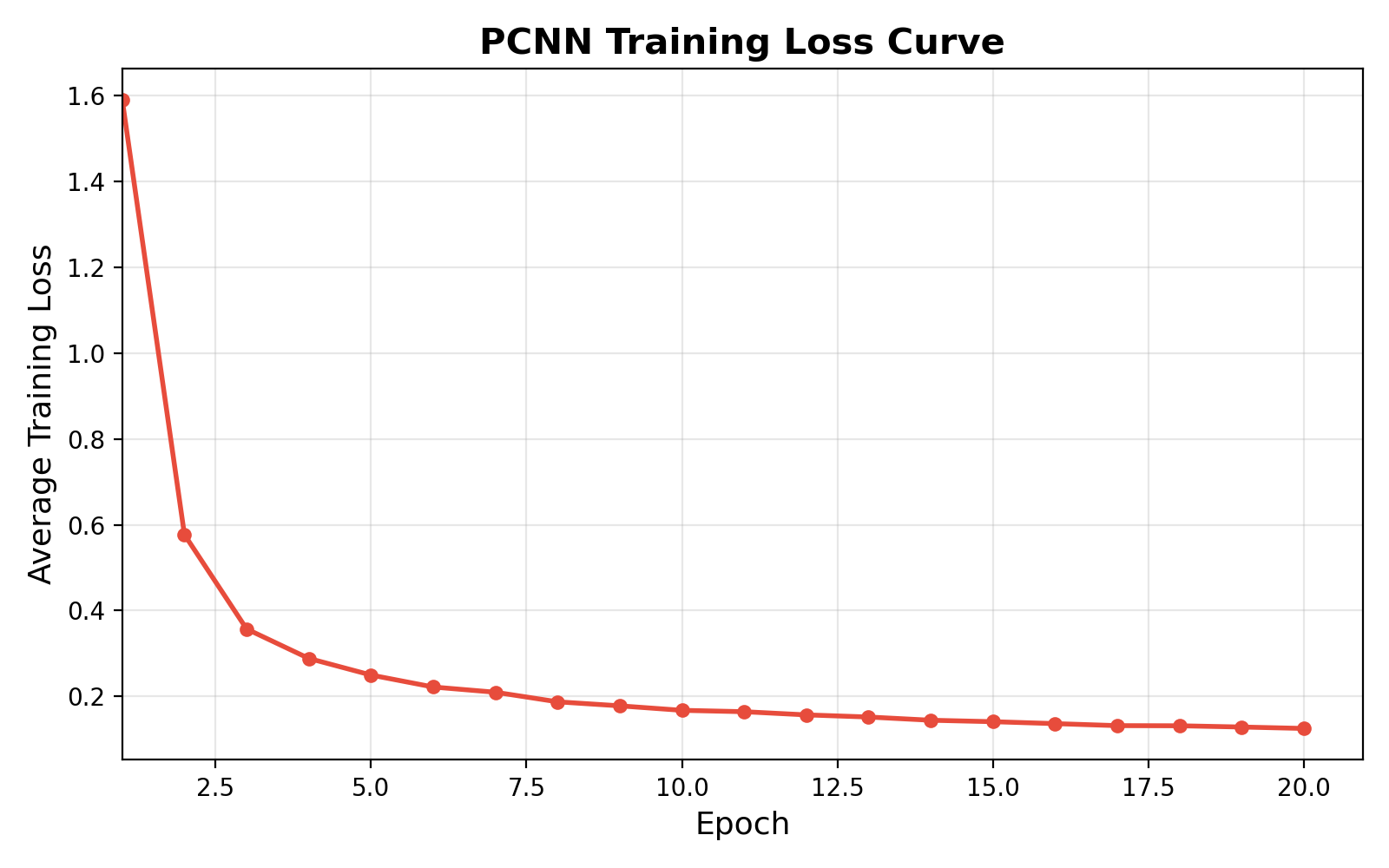
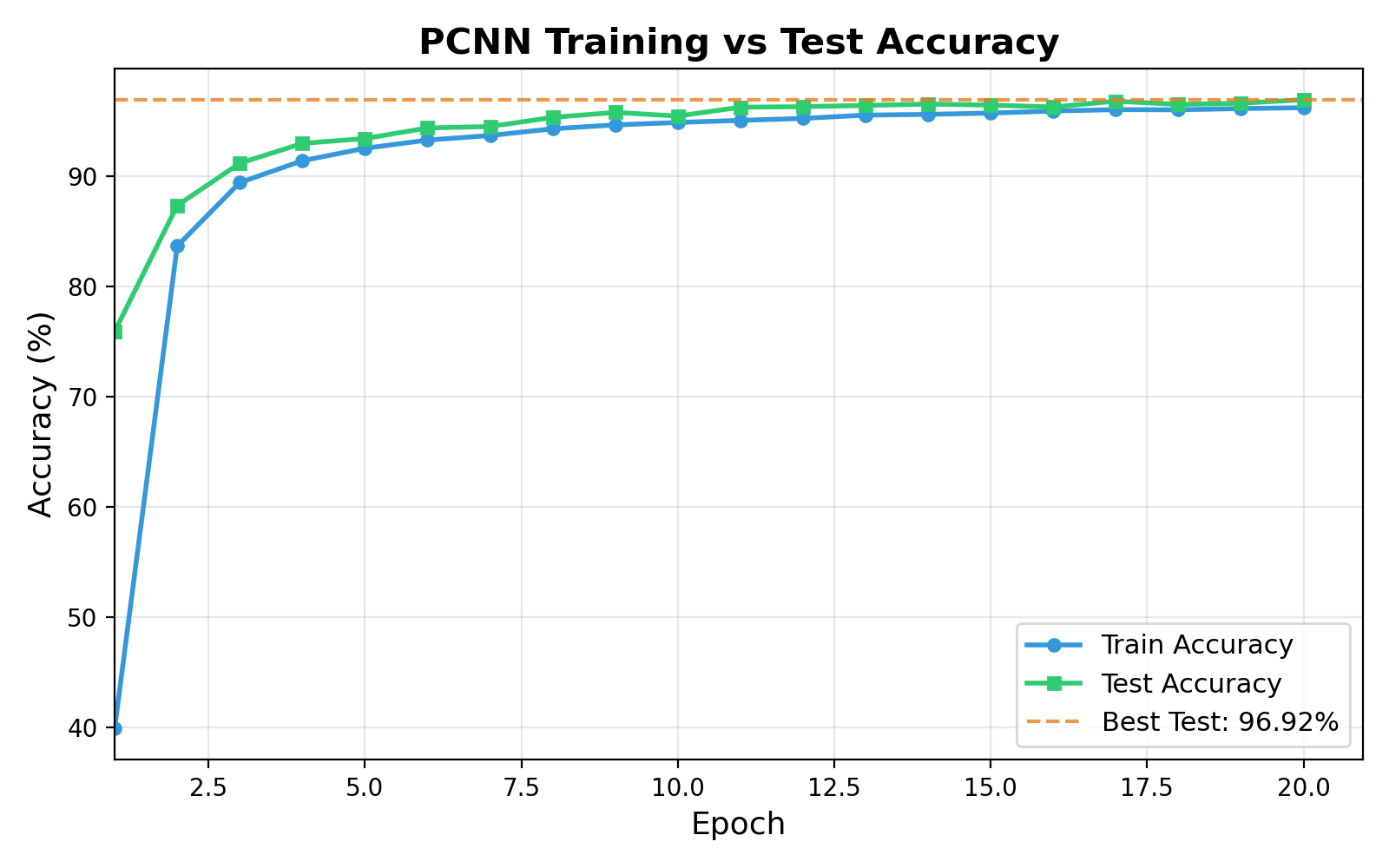
Figure 1: Digital twin pre-training: rapid decrease in loss (left), and convergence to 96.92% test accuracy within 20 epochs (right).
- In-situ fine-tuning: The Simultaneous Perturbation Stochastic Approximation (SPSA) algorithm is used for gradient-free direct hardware optimization. SPSA jointly perturbs all parameters and estimates gradients with only two forward passes per iteration—robust against hardware nonidealities such as thermal crosstalk. Layer-specific learning rates are used to focus aggressive adaptation on later network stages.
Experimental Results and System Robustness
On standard MNIST handwritten digits, the ex-situ pre-trained model attains 96.92% test accuracy on the digital twin, and phase-transfer to idealized hardware yields 94.23% accuracy. Under severe simulated thermal crosstalk (coupling factor of 0.1), accuracy drops by only 0.43%, reflecting strong physical resilience. In-situ SPSA fine-tuning recovers the residual accuracy loss, reaching 94.00% on noisy hardware.
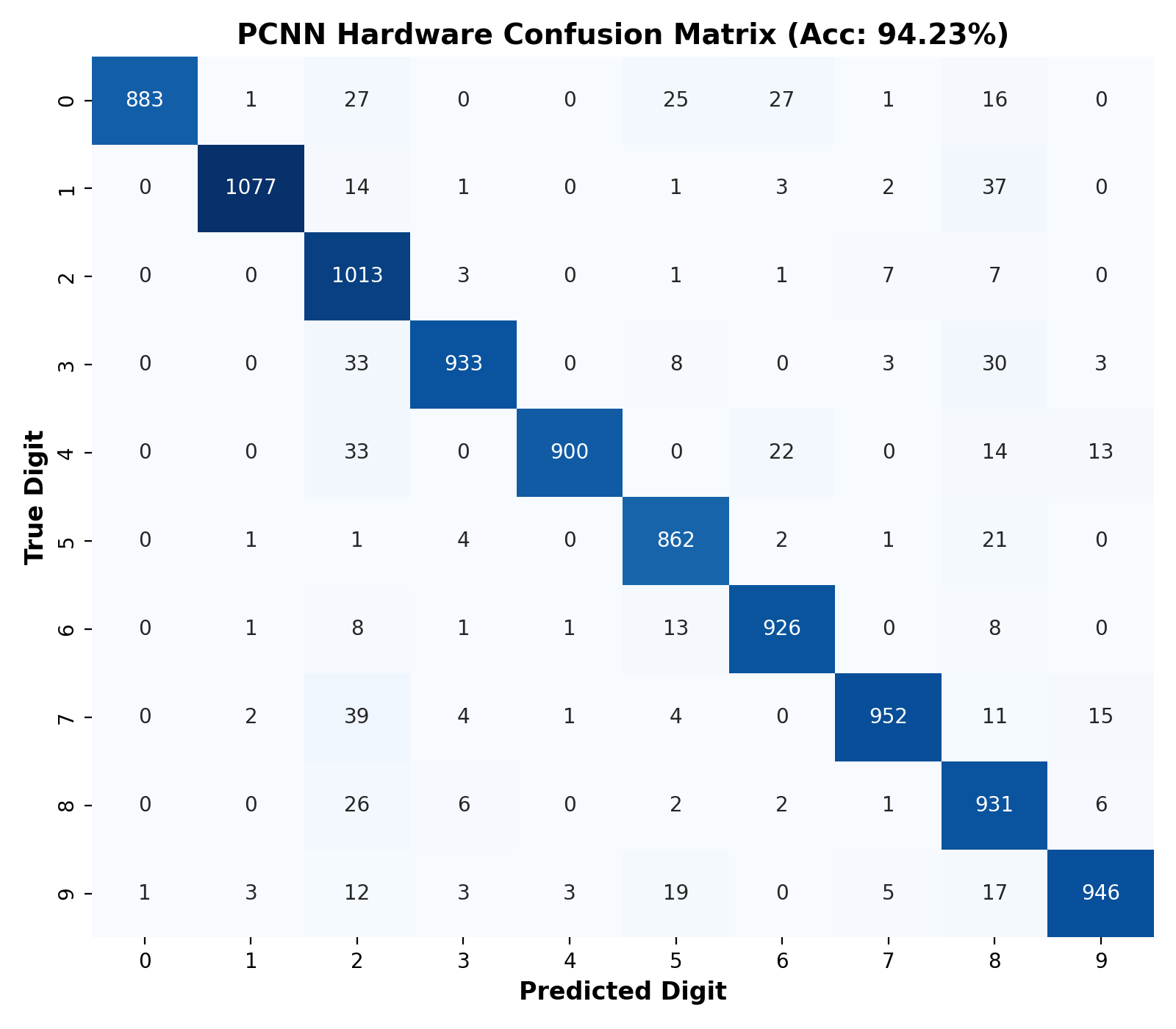
Figure 2: Confusion matrix of hardware-simulated PCNN tested on the MNIST set, showing strong per-class accuracy and cross-class discrimination.
The network’s over-parameterization (due to large Clements meshes), inherent denoising in photonic max pooling, and nonlinear soft-threshold from microring activations are identified as mechanisms for robustness to physical perturbations.
Energy Efficiency, Latency, and System Scaling
Component-wise power analysis yields a total static consumption of 14.7 W, dominated by phase shifters and modulator drivers. Measured end-to-end inference latency is 0.8 μs, limited by serial streaming of image patches through the convolutional stages rather than optical path delays. The per-image energy is 12.4 μJ, yielding a 100–242× boost in energy efficiency compared to contemporary GPUs (NVIDIA T4, H100, A100) for equivalent workloads.
Projected improvements using state-of-the-art phase shifter technologies (undercut or MEMS-based actuators) would further decrease energy per operation (down to 4.4 pJ/MAC), keeping throughput (0.32 TOPS) constant due to the inherent streaming bottleneck.
Theoretical and Practical Implications
The reported PCNN exemplifies a fully coherent, all-optical CNN pipeline with hardware-aligned, numerically exact training/fine-tuning without reliance on computational decomposition. The demonstrated robustness to thermal crosstalk validates the over-parameterized photonic architecture's suitability for on-chip learning with substantial hardware variability.
This work confirms that silicon photonics, with scalable, non-electronic layers for all major CNN functions, can outperform electronic accelerators for well-structured inference tasks under tight latency and power budgets. It paves the way for integrating optical AI accelerators in embedded and edge environments where thermal and energy constraints dominate.
On the training side, the coupling of a fully differentiable digital twin (for ex-situ gradient-based optimization) with in-situ stochastic adaptation offers an effective protocol for parameter handoff from simulation to physical circuit—potentially generalizable to other neuromorphic hardware substrates.
Future Directions
This study’s simulation and system analysis suggest that large-scale, fully integrated photonic neural networks for classification and vision tasks are feasible given current and emerging silicon photonics capabilities. Next steps include physical fabrication, extending benchmarks to larger or more complex datasets, and tackling streaming/throughput bottlenecks via parallelization and architectural innovation. Continued progress in photonic device miniaturization and actuator efficiency will further strengthen the case for all-optical AI accelerators in production deep learning systems.
Conclusion
This work delivers the first demonstration of a monolithic, end-to-end all-optical convolutional neural network supporting direct ex-situ/in-situ parameter transfer, robust learning under physical noise, and superior energy efficiency compared to electronic AI hardware. Accurate physical modeling and adaptive hardware-level optimization collectively yield a resilient, low-latency, high-throughput photonic AI accelerator, revealing the practical viability and strong theoretical promise of photonic computing for future inference workloads.