- The paper presents a novel framework, CBWSDID, that integrates covariate balancing with weighted stacked DID to better estimate treatment effects in staggered policy settings.
- It employs first-stage design adjustments and corrective aggregation weights to mitigate biases arising from within-cohort covariate imbalances between treated and control groups.
- Simulation evidence and empirical applications demonstrate that CBWSDID reduces bias and variance compared to standard methods, enhancing credible inference in complex panel data.
Covariate-Balanced Weighted Stacked Difference-in-Differences: A Design-Based Extension for Heterogeneous Panel Data
Introduction
The Covariate-Balanced Weighted Stacked Difference-in-Differences (CBWSDID) framework advances the identification and estimation of dynamic treatment effects in staggered and recurrent policy adoption settings where untreated potential outcome trends may be parallel only conditional on covariates or lagged outcomes. Standard stacked DID approaches, although separating cohorts to mitigate invalid comparisons, are susceptible to bias when comparability of treated and control groups is not achieved within each cohort-specific sub-experiment. Wing et al. remedied this via corrective aggregation weights, but left untreated within-subexperiment imbalance. CBWSDID unifies this literature by integrating covariate balancing—via matching or weighting—within each sub-experiment, while employing corrective aggregation weights to maintain targeted average treatment effect on the treated (ATT) estimands.
Stacked DID and Corrective Aggregation
In canonical stacked DID, units undergo treatment in varying periods, partitioning the data into sub-experiments by adoption cohort. Comparison is made between treated and "clean controls" (units untreated through the analysis window), generating cohort-specific DIDs that are subsequently aggregated. However, naive aggregation introduces a discrepancy: the control group aggregation does not generally target the same distribution (or mix) as the treated.
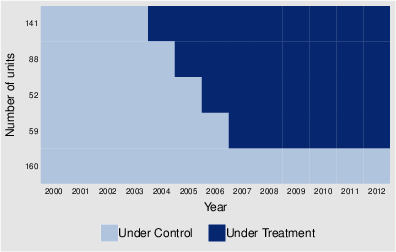
Figure 1: Treatment adoption map in the absorbing-treatment panel simulation, illustrating non-random assignment of treatment cohorts.
Corrective weighting, as per [Wing et al., 2024], aligns control group cohort aggregation weights with treated shares, ensuring the estimator targets the trimmed aggregate ATT and removing distortions from inappropriate control reweighting. This step is necessary but not sufficient, as within-cohort treated and controls may exhibit covariate imbalance, threatening internal validity of the DID contrast.
Covariate Balancing within Sub-Experiments
CBWSDID introduces a first-stage within-subexperiment design adjustment: either matching or balancing weights are estimated using only pre-treatment covariate information, generating (potentially non-uniform) control weights. Treated units retain weight one, so the ATT estimand is preserved. The design weights improve the credibility of the "parallel trends" assumption by ensuring that, conditional on the design, pre-treatment characteristics between treated and controls in each sub-experiment are closely comparable.
This logic is insulating to the type of covariate adjustment method: nearest-neighbor matching with/without replacement, Mahalanobis distance, entropy balancing, inverse probability weighting, and other methods are all admissible as long as weights remain nonnegative and are functions of pre-treatment data. This flexibility enables researchers to tailor the adjustment to the empirical context, maximizing overlap and mitigating instability.
The integration of first-stage design weights with second-stage corrective stacking yields the following structure:
- Within each sub-experiment, covariate-adjusted weights bsa are estimated for controls.
- Aggregation of sub-experiment estimates applies treated-cohort shares, with corrective normalization ensuring the aggregate ATT target is preserved.
The resulting estimator DIDeCBWSDID is the weighted average of adjusted within-cohort DIDs, with weights proportional to treated shares. The construction is such that changing the scale or normalization of bsa in any sub-experiment does not affect the final estimate—normalization is managed at the aggregation stage.
Extension to Repeated Treatment, Switching, and Episode-Based Designs
A salient feature of CBWSDID is seamless extension to settings with repeated treatment reversals (e.g., 0→1 and 1→0 switching). By indexing episodes not just by adoption time, but by both recent treatment history and event time, the framework harmonizes with designs such as PanelMatch, allowing for treatment reversal as a core feature. Under a finite-memory assumption, the potential outcomes depend only on the recent L period treatment history. The estimator then aggregates over switch episodes (not merely first adoption) with appropriate episode-level stacking and weights, preserving the identification logic for ATT over episodes rather than units.
Identification Assumptions
CBWSDID relies on the following key conditions (each appropriately modified for absorbing or repeated treatment designs):
- No anticipation: Treatment does not impact pre-treatment outcomes.
- (History-conditional) Weighted parallel trends: After covariate balancing, control trends parallel treated trends in absence of treatment, within each sub-experiment/episode type.
- Overlap and nondegeneracy: Sufficient number and covariate overlap of treated and control units exist within each sub-experiment.
- Pre-treatment construction of weights: Design weights depend only on pre-treatment information, avoiding post-treatment bias.
These collectively ensure unbiased identification of aggregate ATT or analogous episode-weighted treatment effects.
Simulation Evidence
A simulation with absorbing treatment and non-random assignment (cohort selection correlated with outcome growth trends) demonstrates the vulnerability of standard stacked DID and even corrective weighted stacked DID to bias arising from conditional, non-unconditional, parallel trends. Covariate balancing, either via matching or entropy weighting, robustly corrects spurious pre-trends and recovers the true treatment-effect profile with materially reduced bias and improved statistical properties.
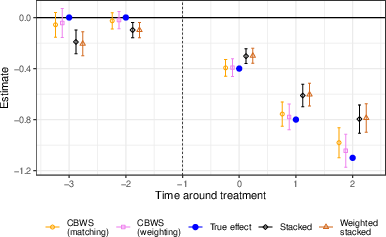
Figure 2: Event-study estimates for the simulation, revealing bias in standard estimators and accurate effect recovery by CBWSDID.
Monte Carlo results across 5,000 replications corroborate these findings: both matching- and weighting-based CBWSDID sharply attenuate bias and type I error, with weighting performing marginally better in simulation due to reduced tuning instability. However, relative performance may invert in settings with poor overlap or unstable weights.
Empirical Applications
Fair Housing Act and Segregation
CBWSDID is applied to analyze the effect of Fair Housing Act adoption on city "whiteness", a challenging empirical setting with stark non-parallel pre-treatment trends. Standard estimators (two-way fixed effect, Sun-Abraham, weighted stacked DID) produce pronounced, statistically significant pre-treatment effects, indicating design invalidity. Both CBWSDID variants (matching and entropy weighting) eliminate spurious pre-treatment trends and show the substantial decline in city whiteness post-adoption is closely tied to invalid comparing groups; the refined estimates are not significant post-adoption.
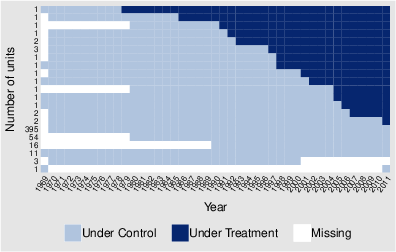
Figure 3: Treatment adoption map in the Trounstine (2020) empirical application, highlighting the timing and geography of Fair Housing Act uptake.
Democracy and Growth: Repeated Treatment
In the democracy and growth example (Acemoglu et al.), the repeated-treatment episode design is implemented, analyzing both democratizations and autocratizations. CBWSDID and PanelMatch, with identical first-stage Mahalanobis matching adjustments, yield negligible short-run growth effects for democratization and robust, persistent negative effects for autocratization. CBWSDID delivers similar point estimates but with lower variance, attributable to more efficient aggregation in the weighted stacked DID representation.
Inference
Statistical inference with CBWSDID is handled via cluster-robust standard errors at the unit level, treating the estimated design weights as fixed post-first-stage. While more ambitious bootstraps that re-estimate design weights are possible (and necessary for certain weighting methods), they are generally not feasible for nonsmooth matched designs.
Implications and Future Directions
CBWSDID provides a principled, design-based approach that integrates the estimation robustness of panel matching and balancing with the transparent estimand and aggregation logic of stacked DID. By cleanly separating design and aggregation stages, CBWSDID addresses two major vulnerabilities in modern panel data causal inference:
- Within-subexperiment comparability using pre-treatment information.
- Correct aggregation across varying treatment adoption patterns.
This generality makes CBWSDID particularly compelling for empirical researchers working in fields (such as economics, political science, public health) where policy interventions, treatments, or exposures are rolled out in non-random, heterogeneous fashions.
Ongoing and future research directions include:
- Evaluating the small sample and extreme-overlap cases for various balancing methods in the design stage.
- Exploring alternative estimation and inference strategies under complex dependency patterns (e.g., cross-sectional and temporal dependence).
- Extending user-friendly implementations in statistical software to enhance empirical adoption.
Conclusion
CBWSDID bridges weighted stacked DID and design-based panel matching, equipping researchers with a flexible, design-conscious, and estimand-transparent estimator for settings of staggered and repeated treatment. Substantive simulations and empirical applications confirm its advantages in mitigating bias from covariate and lagged outcome imbalance, producing robust inference even in demanding design environments. Its framework forms a reliable foundation for credible policy effect estimation in complex panel settings.

