- The paper introduces a GPU-optimized Zak-OTFS receiver that exploits structured-sparse channel representations and branchless iterative equalization to deliver up to 906.52 Mbps throughput.
- The paper employs compute-aware algorithmic co-design techniques, including compact matrix operations and channel sparsity exploitation, ensuring deadline-satisfying latency on large delay-Doppler grids.
- The paper validates the receiver across multiple GPU platforms under realistic vehicular channel models, demonstrating BER parity with LMMSE and robust real-time performance.
Real-Time and Scalable Zak-OTFS Receiver Processing on GPUs
Overview
This work presents a comprehensive system design and implementation for scalable, real-time Zak-OTFS receiver processing utilizing GPU platforms. Zak-OTFS modulation, in contrast to traditional OFDM and MC-OTFS, offers explicit delay-Doppler (DD) domain representation, enhancing robustness in high-mobility channels but substantially increasing signal processing complexity as grid sizes expand. The authors exploit compute-aware algorithmic and hardware co-design, channel sparsity, and specialized matrix operations to enable end-to-end low-latency processing for DD grids up to (16384, 32) on modern GPUs, achieving throughput up to 906.52 Mbps at 245.76 MHz bandwidth using 16QAM. Extensive evaluation demonstrates deadline-satisfying latency and high throughput across several compute and hardware platforms, establishing practical viability for NextG high-mobility communications.
Zak-OTFS Processing Pipeline and Channel Model
Zak-OTFS directly applies the Zak transform to map DD symbols into time-domain pulse trains ("pulsones"), providing structured mapping over the full frame duration. The processing pipeline comprises:
- Zak transform and its inverse for DD/time domain conversion
- Pilot-based channel estimation leveraging DD domain sparsity
- Construction of the DD domain channel matrix H, inherently large and structured sparse
- Iterative equalization using GPU-optimal algorithms
- Hard demodulation for symbol recovery
Vehicular-A channel models are simulated, featuring multiple paths with fractional delay/Doppler and AWGN, to validate system behavior under realistic, high-mobility conditions.

Figure 1: Zak-OTFS pipeline: pilot and data frames undergo DZT, channel estimation, and equalization under Vehicular-A channel, leveraging delay-Doppler domain processing.
Compute-Aware System Design
The authors identify three critical optimizations:
1. Compact Matrix Operations:
Precomputing exponential phase coefficients and leveraging GEMM and Hadamard products for signal transformations allows efficient mapping to GPU-optimized operations, outperforming FFT-based expressions for typical grid sizes given the arithmetic units in modern GPUs.
2. Structured Channel Sparsity:
Wireless channels manifest extreme sparsity in the DD domain; h∈CM×N contains only a small number P of dominant paths. The channel matrix H can thus be represented in a structured-sparse format indexed by physical path parameters, drastically reducing computational and memory overhead in matrix-vector multiplications essential for equalization.
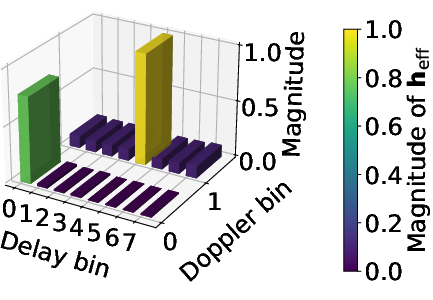
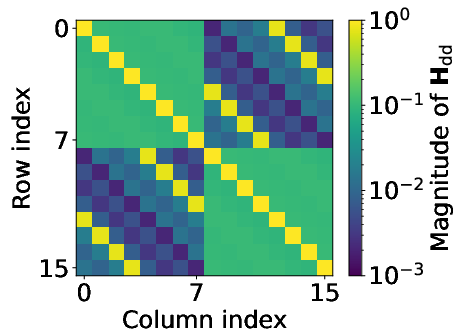
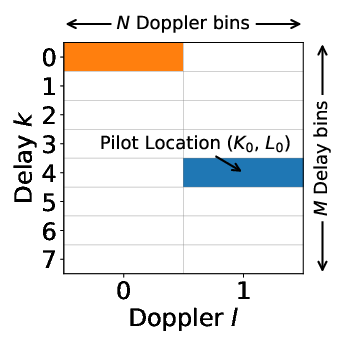
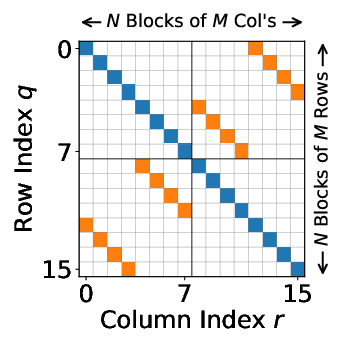
Figure 2: Visualization of DD channel sparsity and structured block-diagonal channel matrix. Dominant channel paths are isolated by thresholding, forming block-circulant patterns in H.
3. Branchless Iterative Equalization:
GPU compute efficiency is highly sensitive to branching. The authors employ a branchless conjugate gradient algorithm (CGA), determining the fixed iteration count offline via BER-driven profiling, thereby eliminating runtime conditional termination and maximizing GPU utilization. Noise covariance is reduced to scalar form for further arithmetic compression.
Scalability and Latency Analysis
The system achieves robust scalability on GPU platforms, translating operator-level MVM speedups into end-to-end deadline satisfaction for large DD grids. Latency evaluation across CPU and multiple GPUs demonstrates the following:
- Median and p99.9 latency consistently meet the processing deadline ($2T$ = 2.134 ms for typical configurations), even for M=16384, N=32.
- CPU implementations quickly become infeasible for large grids due to lack of parallelism and memory bandwidth.
- Structured-sparse representations of channel matrices are the key enabler for constant latency across grid scaling, independent of actual grid dimension but only dependent on the number of channel paths P.
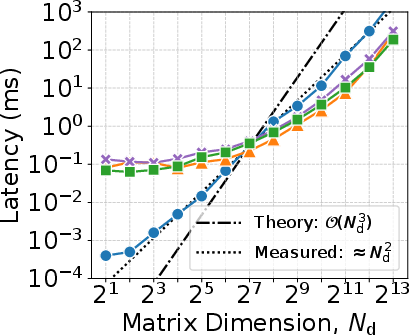
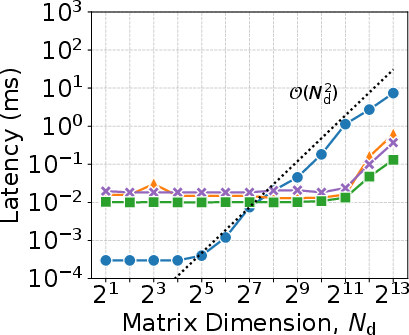
Figure 3: Compute latency and scalability for matrix inversion and matrix-vector multiplication across CPU/GPU platforms: MVM enables scalable low-latency DD-domain operations on GPU.
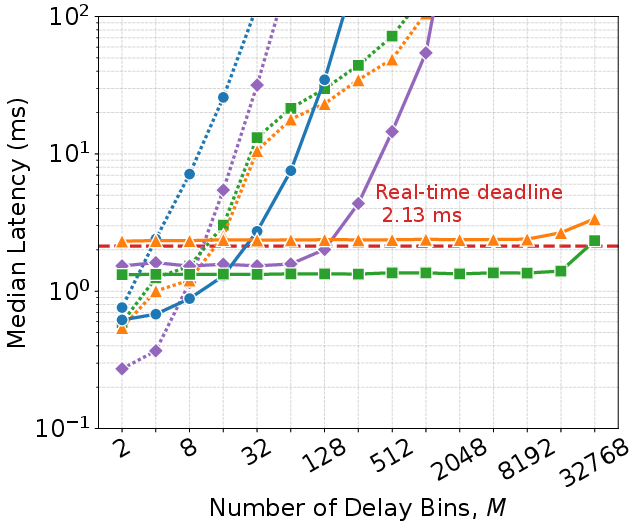
Figure 4: Median end-to-end processing latency per frame across hardware platforms, equalizers, and sparsity-aware representations. SS-CGA consistently satisfies per-frame deadline.
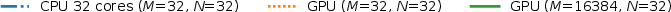
Figure 5: Latency CCDF: GPU meets strict tail latency targets for large DD grids, outperforming CPU approaches even as grid size increases.
The proposed SS-CGA equalizer, leveraging structured sparsity and compute-aware execution, matches or exceeds LMMSE in BER under realistic Vehicular-A channels while providing orders-of-magnitude lower latency. BER evaluation reveals:
- SS-CGA and LMMSE achieve BER < 0.015% for QPSK, and ~7.8% for 16QAM (M=16384, N=32, SNR=25dB).
- SS-CGA outperforms SS-MRC across SNR and Doppler spread settings.
- Proper thresholding of channel elements (γ) exploits channel sparsity, improving both latency and BER.
- Iteration count for CGA is empirically determined for each operating regime, striking a balance between latency and convergence without runtime monitoring.
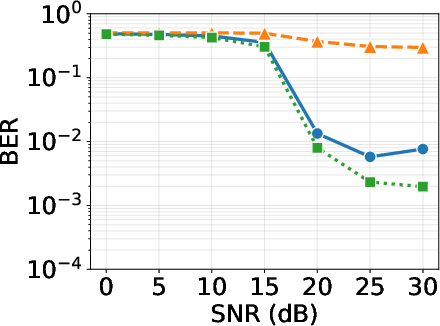
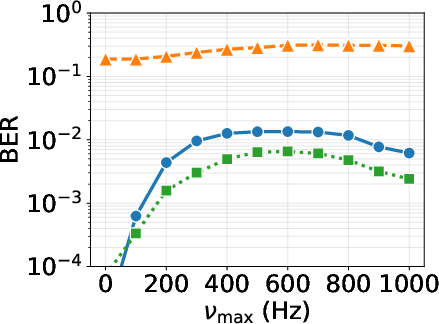
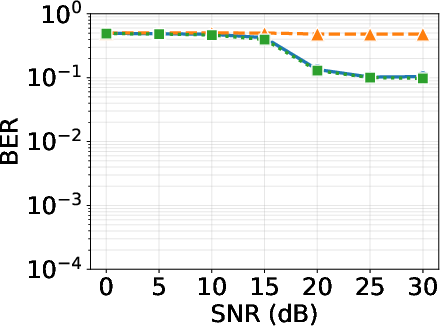
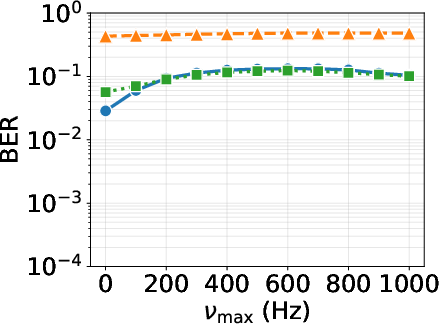
Figure 6: BER vs SNR for QPSK across equalizers: SS-CGA achieves parity with LMMSE, outperforming SS-MRC, confirming compute-aware equalization does not impair error performance.
Differential evaluation across multiple GPU platforms (Jetson Orin, RTX 6000 Ada, A100, H200) establishes processing latency boundaries as a function of grid size, Doppler bin count h∈CM×N0, and hardware characteristics. Jetson Orin, designed for edge, exhibits higher constant overhead and meets stricter deadlines for smaller grids. Each platform's parallelization limits are identified, guiding practical deployment.
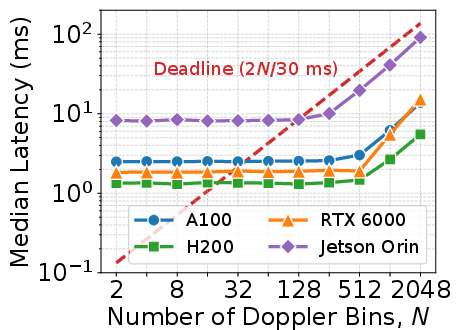
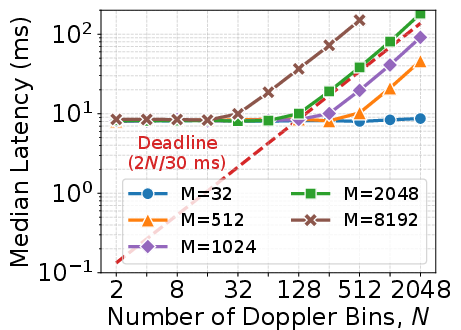
Figure 7: Median processing latency versus Doppler bin count h∈CM×N1 for multiple GPU platforms: intersection with deadline lines marks scalable operating region for each hardware target.

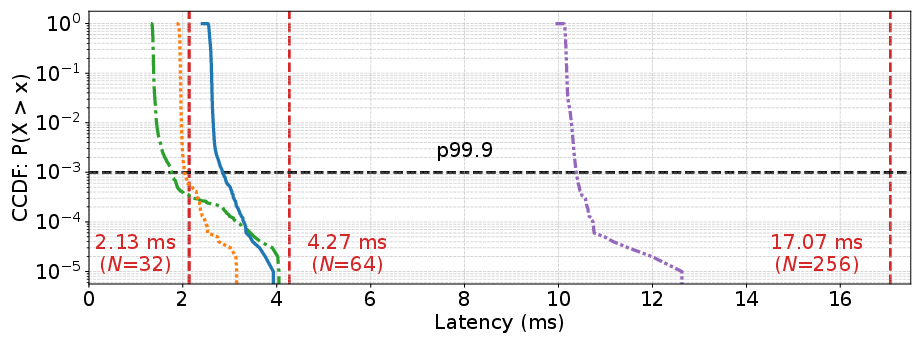
Figure 8: Platform-specific latency CCDF for largest feasible h∈CM×N2 values, confirming distinct real-time capability envelopes per GPU.
Theoretical and Practical Implications
The results demonstrate that exploiting DD domain channel sparsity and matrix operation optimizations unlock real-time Zak-OTFS processing for grid sizes previously considered computationally prohibitive. Structured-sparse representations are generalizable to any doubly-dispersive channel with low path-count, facilitating practical deployment in NextG vehicular and mobile networks. The branchless iterative paradigm aligns with GPU architecture, suggesting broader applicability to other wireless DSP workloads, including massive MIMO and LDPC decoding. The findings also inform DSP co-design strategies for future software-defined radio, virtualized RAN, and edge computing solutions, highlighting the necessity for explicit cross-layer optimization.
Conclusion
The system presented achieves scalable, deadline-sensitive Zak-OTFS receiver processing up to (16384, 32) DD grids on GPUs, with up to 906.52 Mbps throughput at 245.76 MHz bandwidth and robust BER performance for both QPSK and 16QAM. Structured-sparse matrix representations and branchless CGA equalization lie at the core of the design, facilitating low-latency operations with optimal parallelism and memory footprint. These insights establish both algorithmic and practical foundation for deploying Zak-OTFS in high-mobility NextG communications, and chart a path toward increasingly real-time, compute-aware DSP in future wireless systems.

