- The paper introduces an on-premises RAG pipeline that grounds LLM responses in curated EIC scientific literature.
- It employs fine-grained text chunking, 1024-dimensional embeddings, and cosine similarity with MMR to achieve accurate contextual retrieval.
- Evaluations reveal high context recall and faithfulness with challenges in entity recall and answer correctness, guiding future improvements.
Retrieval-Augmented Question Answering System for EIC Scientific Literature
Introduction
This work proposes and evaluates an on-premises, open-source Retrieval-Augmented Generation (RAG) pipeline for question answering over arXiv scientific literature pertaining to the Electron-Ion Collider (EIC) experiment (2604.02259). RAG is leveraged to ground LLM responses in curated scientific contexts, mitigating the typical hallucination errors observed in pretrained LMs. The deployment targets the EIC collaboration—an international experiment producing a substantial corpus of technical and scientific publications—by facilitating accurate, context-aware, and citation-traceable responses to detailed queries. The design prioritizes resource efficiency, privacy (eschewing cloud dependencies and external APIs), and transparent traceability of generated responses to their foundational sources.
System Architecture
The architecture encompasses a modular pipeline consisting of article ingestion, fine-grained document chunking, embedding generation, vector storage and retrieval, prompt formation, and context-conditioned answer generation via LLMs.
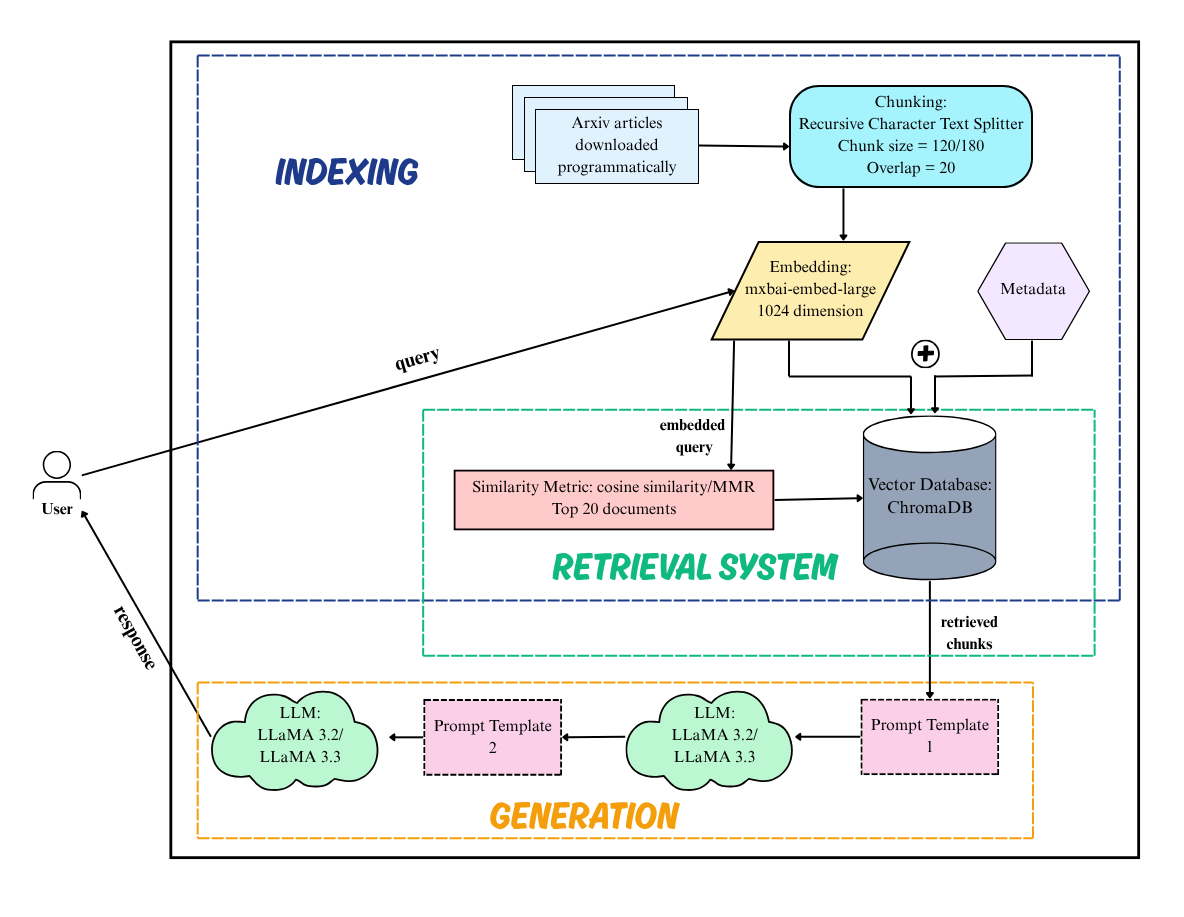
Figure 1: Schematic overview of the RAG-based QA system, detailing ingestion, chunking, vectorization, ChromaDB indexing, retrieval, prompt assembly, and response generation.
The system ingests 178 arXiv articles spanning EIC phenomenology, hardware, and computational developments. Texts are segmented with the RecursiveCharacterTextSplitter (120 or 180-character segments, with a 20-character overlap), an approach aligned with prior literature emphasizing the trade-off between information coverage and relevance granularity. These chunks and associated metadata (arXiv ID, authors, publication year) are embedded into 1024-dimensional vectors using the mxbai-embed-large transformer model, achieving strong semantic fidelity and supporting local deployment. Of the multiple vector-store technologies examined (FAISS, Pinecone, LanceDB, ChromaDB), ChromaDB was selected for its privacy, efficiency, and compatibility with LangChain orchestration.
Query retrieval utilizes both cosine similarity and Maximum Marginal Relevance (MMR); top-20 most relevant chunks are incorporated into a synthesized prompt delivered to LLaMA LLM variants (3.2 and 3.3). A guardrail-enforced prompt formulation restricts answer generation strictly to retrieved contexts, with every response undergoing context traceability via LangSmith.
Latency Characterization
The study benchmarks the latency distribution at both the retrieval and generation steps, dissecting the impact of chunk size, retrieval algorithm (Cosine, MMR), and LLaMA model size.
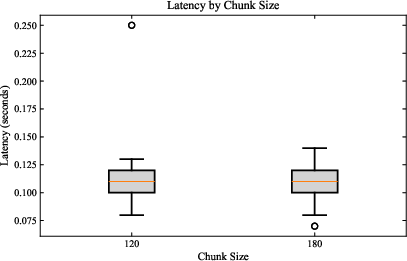
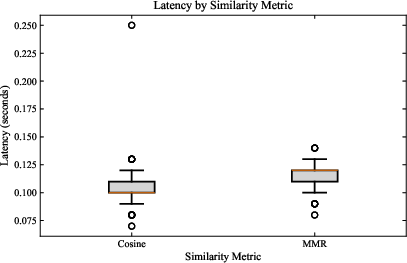
Figure 2: (Left) Retrieval latency comparison between 120 and 180-character chunk sizes; (Right) Latency distribution for Cosine similarity versus MMR retrieval.
The empirical evaluation indicates that retrieval latency is effectively invariant under both chunk size (median ≈0.11s for 120 and 180) and retrieval metric, though wider chunk sizes introduce slightly greater variance. In sharp contrast, generation latency is highly sensitive to model scale:
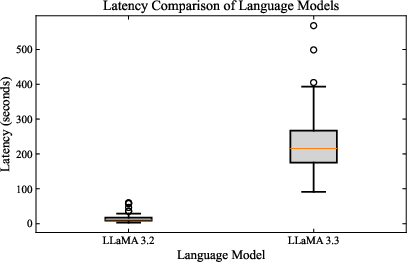
Figure 3: Distribution of response generation delay for LLaMA 3.2 versus LLaMA 3.3 models.
LLaMA 3.3, while potentially more capable, introduces an order-of-magnitude increase in inference time and greater variance, rendering it less suitable for interactive QA deployment under resource constraints. LLaMA 3.2 provides a stable, narrow latency profile (median 10–20s).
Evaluation: Retrieval-Augmented Generation Assessment
The system’s output is rigorously evaluated against an expert-vetted gold-standard dataset (AI4EIC2023_DATASETS, 51 questions with multi-claim structure). RAG Assessment (RAGAS) metrics—Context Entity Recall, Context Precision, Context Recall, Answer Relevance, Correctness, and Faithfulness—are computed across chunking and retrieval strategies.
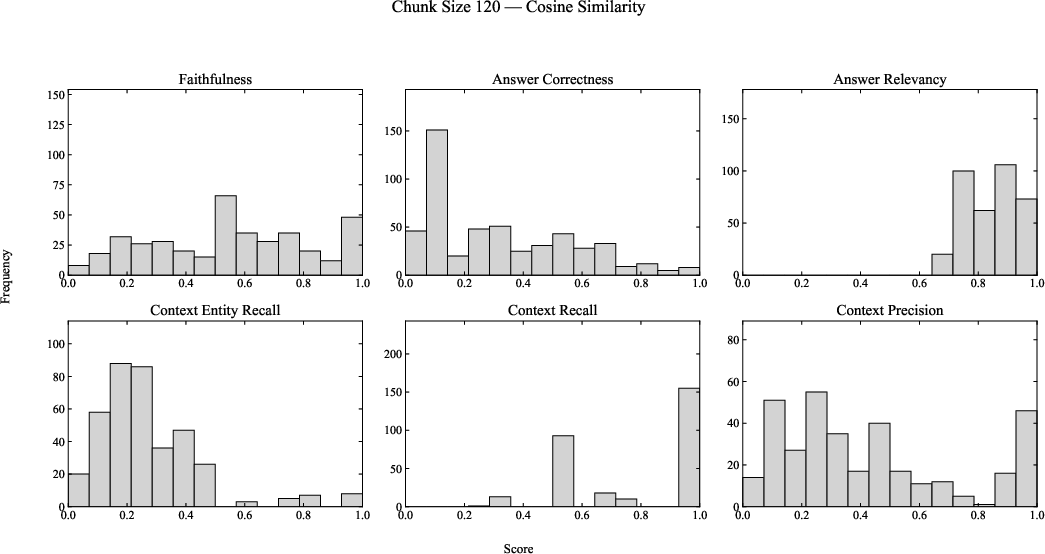
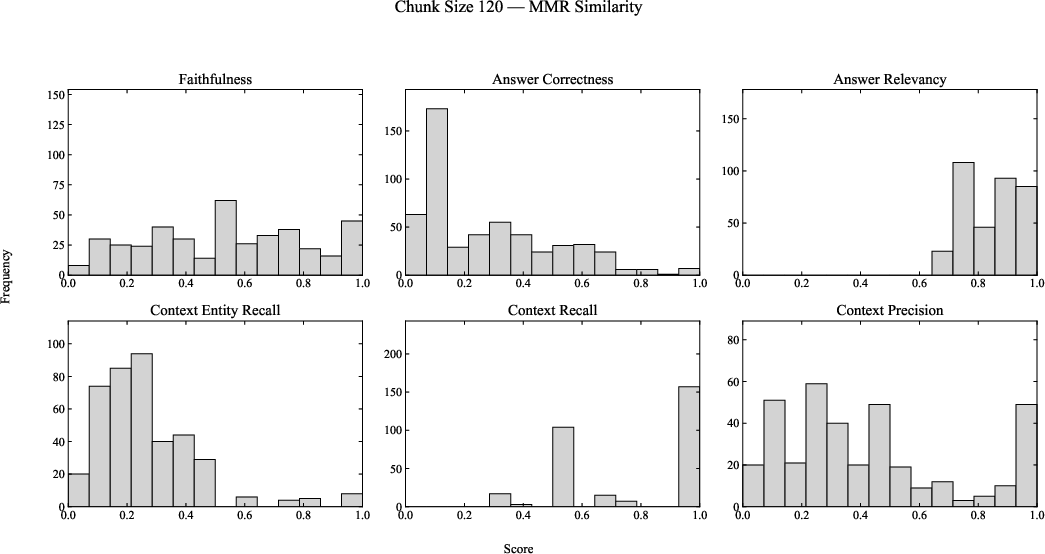
Figure 4: RAGAS benchmark distributions for chunk size 120, comparing Cosine and MMR retrieval across six evaluation metrics.
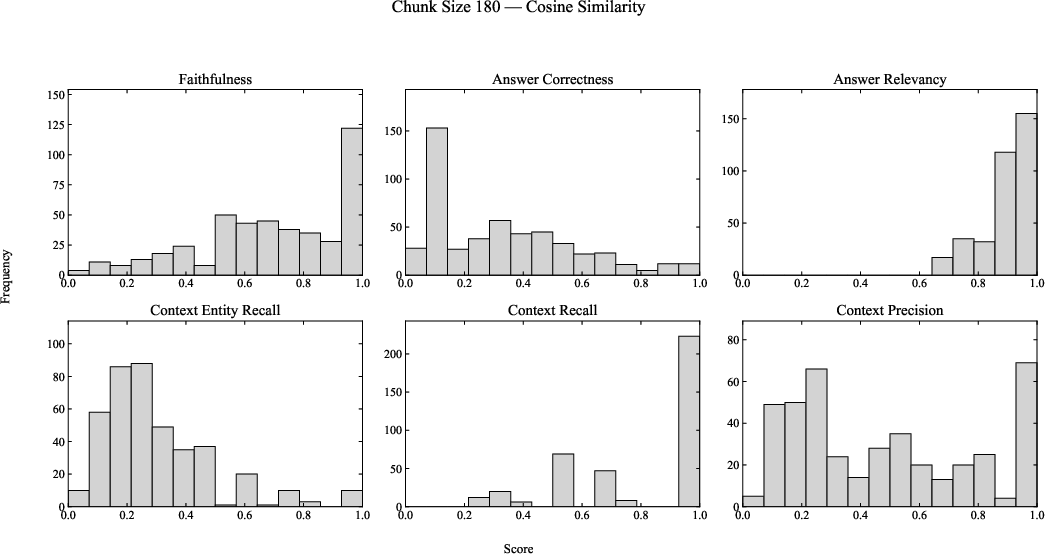
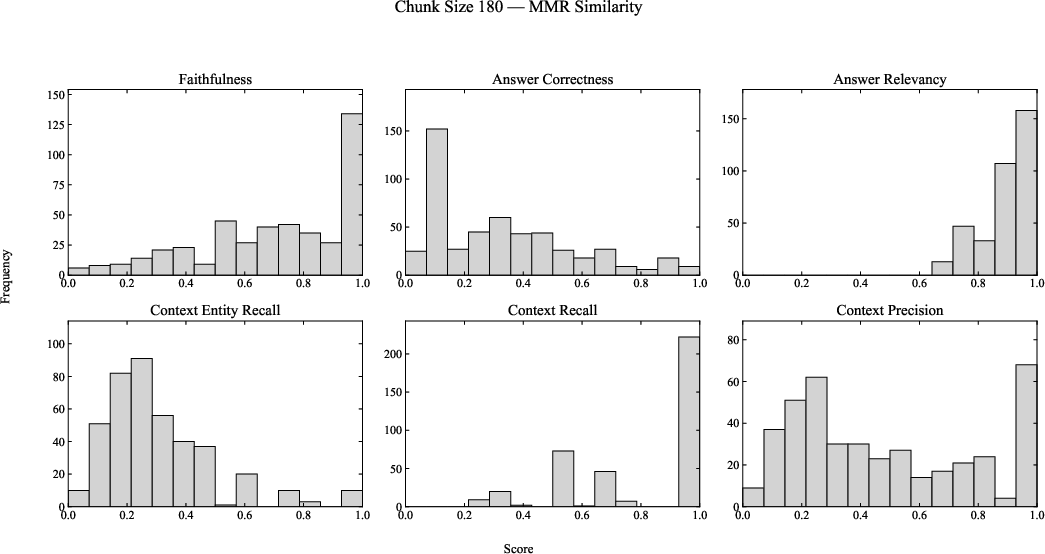
Figure 5: RAGAS scores for chunk size 180; upper panel: Cosine similarity, lower: MMR.
Robust trends are observed:
- Context Recall consistently clusters near 1.0, especially for 180-character chunks, indicating high recall of ground-truth claims due to improved context preservation.
- Context Precision and Entity Recall remain modest, with broad bimodality and moderate performance. This likely reflects challenges for general-purpose embedding models in capturing domain-specific scientific entities.
- Faithfulness and Answer Relevance both improve with chunk size, evidencing more comprehensive factual alignment in generated answers as larger segments encompass more supporting evidence.
- Answer Correctness lags behind, with notably low scores, highlighting the inherent difficulty of capturing precise factual details important in the EIC domain and the limitations of lightweight LLaMA variants.
Importantly, MMR fails to produce clear performance gains over cosine retrieval within this domain-specific, moderate-size corpus.
Implications and Future Directions
The demonstrated methodology provides a practical blueprint for domain-grounded scientific QA with controlled data governance. By eschewing proprietary LMs and cloud-hosted vector DBs, it lays a foundation for collaboration-centric, privacy-preserving research assistance. Several salient insights arise:
- Model scaling has greater impact on system responsiveness than marginal retrieval design variations, emphasizing the need for careful resource/model size calibration in practical deployments.
- Chunk size must balance between recall and precision, with larger chunks advisable given the document structure and QA needs typical in experimental physics literature.
- The moderate RAGAS correctness and precision scores signal a need for science-specialized embedding models and more robust entity-aware retrieval architectures.
Future work will focus on expanding the knowledge base to include presentations, wikis, and technical reports, as well as orchestrating the pipeline via LangGraph to enable more flexible control and monitoring. Incorporating open-source LMs with stronger performance on long, technical context and developing advanced entity-aware embedding schemes are promising research avenues.
Conclusion
The work systematically validates open-source, locally deployed RAG QA for EIC scholarly content, achieving high context recall and faithfulness but revealing ongoing bottlenecks in entity recall and factual precision. The results underscore the maturity of RAG for specialized scientific collaborations under privacy and resource constraints, but also delineate clear pathways for enhancing factual grounding and latency. This positions the approach as a scalable foundation for future research assistant tools in large-scale, data-intensive scientific workflows.