- The paper presents an innovative anisotropic speculation tree design that fuses context-matched (PLD) and transition-based (TR) proposals to boost decoding efficiency.
- The methodology integrates dynamic programming with confidence-adaptive allocation to achieve up to 4.3x lossless speedup over standard autoregressive decoding.
- Empirical results and theoretical proofs confirm that the anisotropic design consistently outperforms isotropic and single-source baselines in expected token acceptance.
Goose: Anisotropic Speculation Trees for Training-Free Speculative Decoding
Introduction and Motivation
Efficient inference for LLMs is essential given their increasing deployment in latency-sensitive applications. Speculative decoding accelerates autoregressive decoders by drafting multiple candidate tokens and leveraging the model's verification mechanism to accept as many as possible in a single forward pass, under the constraint that outputs are provably identical to classical decoding. Existing training-free speculative decoding approaches have focused either on breadth-heavy trees driven by transition probabilities (e.g., Token Recycling, TR) or depth-centric chains produced from context matching (e.g., Prompt Lookup Decoding, PLD), or on isotropic trees such as Sequoia that do not account for acceptance heterogeneity among sources.
"Goose: Anisotropic Speculation Trees for Training-Free Speculative Decoding" (2604.02047) identifies a significant, persistent acceptance probability gap between context-matched and transition-based token proposals. The paper formalizes the optimal topology for this heterogeneous case, proves that an asymmetric (anisotropic) tree with a deep, context-matched spine and wide, transition-derived branches strictly dominates single-source designs, and realizes this structure in the Goose framework, yielding substantial, lossless acceleration without auxiliary training.
Theoretical Framework: Acceptance Heterogeneity and Optimal Topology
Goose builds on Sequoia's dynamic programming approach but fundamentally augments it by modeling acceptance probabilities as source-dependent: ps for context-matched (spine) tokens, and pt for transition (TR) tokens, with empirical results confirming a median 6× acceptance ratio (spine vs. branches) that spans 2×--18× across architectures and benchmarks.
The optimal candidate tree under this heterogeneous acceptance model is an anisotropic spine tree:
- Spine (depth): Formed by context matches, yielding a high-confidence chain.
- Branches (breadth): Populated by transition alternatives, which hedge at each node against early termination of the spine.
The paper derives lower bounds on the expected number of accepted tokens per verification (E[τ]), showing that the spine tree's yield always exceeds the best single-source approach (either pure-PLD or pure-TR) under any feasible resource budget. Optimal branch allocation is shown to decrease linearly with distance from the root, exploiting the exponential decay in the probability of reaching deeper nodes.
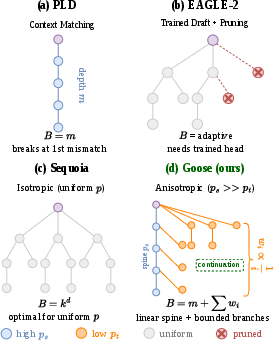
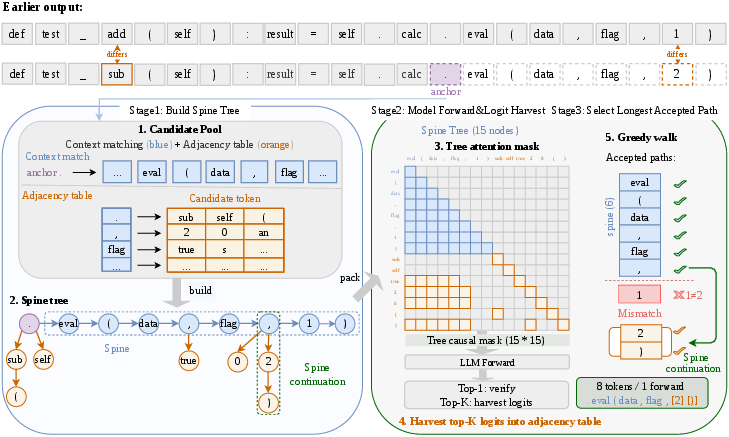
Figure 1: Speculation-tree topologies: (a) PLD spine (linear), (b) EAGLE-2 pruned, (c) Isotropic (uniform-rate), and (d) Goose's anisotropic spine tree with adaptive depth and breadth.
Theoretical proofs confirm that for any ps>pt>0, a sufficiently deep and resourced spine tree always yields higher expected acceptance than balanced-branching or single-source trees, and that the advantage grows monotonically with the degree of acceptance heterogeneity.
The Goose Framework: Algorithm and Pipeline
Goose is formulated as a training-free, confidence-adaptive system that dynamically combines PLD and TR candidate sources within a unified, anisotropic tree at each decoding cycle. Each cycle proceeds as follows:
- Candidate Pooling and Tree Construction: From the current anchor (last accepted token), context matching retrieves the longest available n-gram continuation as the spine. The TR adjacency table (extended to bigram conditioning in Goose) supplies high-probability alternative branches at each spine node. The budget for total nodes is apportioned adaptively between the two sources, with a runtime-tuned spine ratio.
- Unified Verification: All candidates are passed through a tree attention mask, ensuring causal constraints and enabling simultaneous scoring of all paths in one LLM forward step.
- Greedy Path Selection: The longest accepted path under step-wise target model verification is selected. This process inherently recovers "spine continuation," where a branch can extend the decoded sequence beyond a spine mismatch.
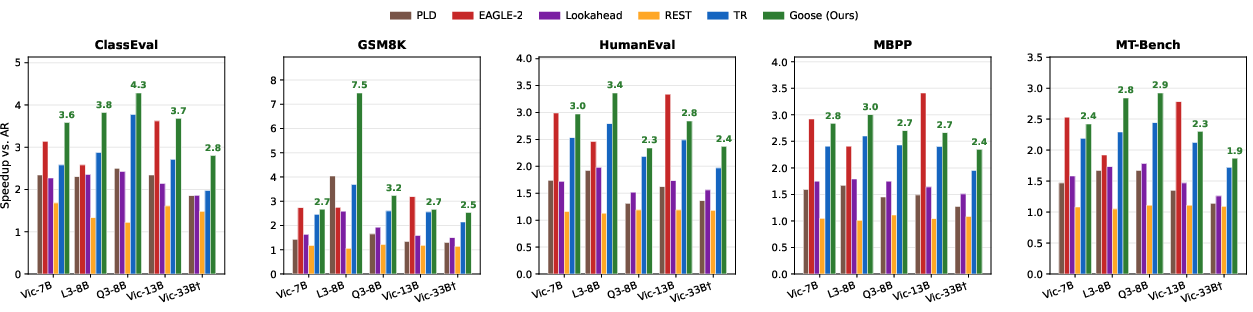
Figure 2: Goose pipeline overview: Stage 1 constructs the candidate tree, Stage 2 verifies all candidates in a single forward pass, and Stage 3 locates the longest accepted path via a greedy walk, supporting spine continuation at mismatch points.
Crucially, Goose adapts between bypassing tree construction for high-confidence, long PLD matches (linear mode), employing a hybrid tree when both sources are available, and reverting to pure-TR or even AR decoding in degenerate cases. This is guided by a run-time PLD confidence estimate (via multi-length n-gram consensus and match length).
Goose is benchmarked on five LLMs (Vicuna-7B/13B/33B, Llama-3-8B-Instruct, Qwen3-8B) over five tasks encompassing code generation, mathematical problem solving, and open-domain dialogue. Results show:
- Lossless speedup (identical output to AR): 1.9x--4.3x across all models and tasks, with the best-case (GSM8K, Llama-3-8B) reaching 7.5x due to pathological repetition.
- Superior τ (compression ratio): Outperforming best single-source and isotropic-tree baselines by 12--33% under fixed node budget, consistent with the theoretical prediction.
Ablation studies confirm that both the anisotropic topology and confidence-adaptive budget allocation contribute substantially to the gains observed, with the PLD-derived spine and bigram-TR branches providing complementary benefits.
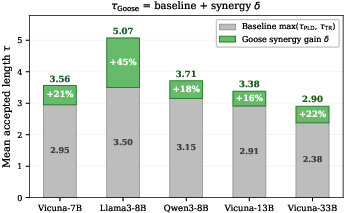
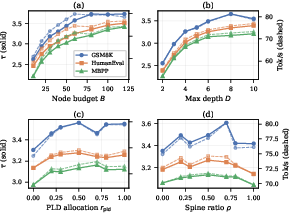
Figure 3: Wall-clock speedup over autoregressive decoding. Goose achieves 1.9x–4.3x speedup, outperforming baseline methods across model sizes and tasks.
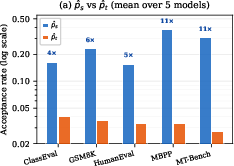
Figure 4: Acceptance heterogeneity on five benchmarks: mean acceptance rates for PLD (spine) and TR (branch) tokens, indicating a persistent multi-fold gap.
Synergy analysis shows that the "spine continuation" path—obtained only by the anisotropic layout—contributes up to 44% of accepted tokens on certain tasks, validating the structural argument. The advantage of Goose persists across all tested models and data distributions.
Practical and Theoretical Implications
The main practical impact of Goose is to provide an efficient, training-free speculative decoding routine applicable to any LLM, regardless of whether auxiliary draft models or feature-based heads are available. This makes Goose particularly suitable in deployment scenarios where retraining, fine-tuning, or architectural modification is infeasible.
Theoretically, the work:
- Demonstrates that topology optimization for verification trees is fundamentally a function of source acceptance heterogeneity, not just resource allocation or position.
- Establishes strict dominance (in expected accepted tokens per call) of anisotropic over isotropic/monolithic strategies, generalizing prior work.
- Suggests that further exploiting source diversity (e.g., more than two token sources with distinct quality) can yield even greater gains—an open avenue for future research.
Limitations include the focus on batch=1 inference and the assumption of greedy decoding; extensions to batched settings, stochastic sampling, and very large vocabularies may require additional system-side and algorithmic refinements.
Conclusion
Goose introduces an acceptance-heterogeneity-aware framework for training-free speculative decoding in LLMs, leveraging a provably optimal anisotropic tree topology that fuses context-matched (PLD) and transition-based (TR) candidates. Adaptive topology selection and branch allocation ensure that Goose strictly maintains or improves upon the yield of any standalone source, with empirical wall-clock speedups of up to 4.3x and consistent superiority to prior training-free baselines. The approach is robust across models and task types, and the theoretical results motivate further study of multi-source, structure-aware drafting in autoregressive inference acceleration.
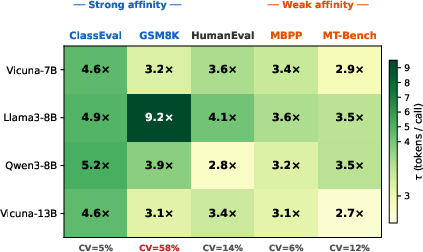
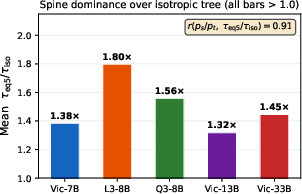
Figure 5: Per-dataset pt0 grouped by Goose’s source affinity and robustness: strong gains are observed across all settings, with coherence between acceptance heterogeneity and performance.