SenseMath: Do LLMs Have Number Sense? Evaluating Shortcut Use, Judgment, and Generation
Abstract: LLMs often default to step-by-step computation even when efficient numerical shortcuts are available. This raises a basic question: do they exhibit number sense in a human-like behavioral sense, i.e., the ability to recognize numerical structure, apply shortcuts when appropriate, and avoid them when they are not? We introduce SenseMath, a controlled benchmark for evaluating structure-sensitive numerical reasoning in LLMs. SenseMath contains 4,800 items spanning eight shortcut categories and four digit scales, with matched strong-shortcut, weak-shortcut, and control variants. It supports three evaluation settings of increasing cognitive demand: Shortcut Use (whether models can apply shortcuts on shortcut-amenable problems); Applicability Judgment (whether they can recognize when a shortcut is appropriate or misleading); and Problem Generation (whether they can generate new problem items that correctly admit a given type of shortcut). Our evaluation across five LLMs, ranging from GPT-4o-mini to Llama-3.1-8B, shows a consistent pattern: when explicitly prompted, models readily adopt shortcut strategies and achieve substantial accuracy gains on shortcut-amenable items (up to 15%), yet under standard chain-of-thought prompting they spontaneously employ such strategies in fewer than 40% of cases, even when they demonstrably possess the requisite capability. Moreover, this competence is confined to the Use level; models systematically over-generalise shortcuts to problems where they do not apply, and fail to generate valid shortcut-bearing problems from scratch. Together, these results suggest that current LLMs exhibit procedural shortcut fluency without the structural understanding of when and why shortcuts work that underlies human number sense.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple question: do today’s AI LLMs (like chatbots) show “number sense” the way people do? Number sense means spotting useful patterns in numbers, choosing smart shortcuts when they help, and knowing when not to use them. For example, instead of multiplying 98 × 14 the long way, a person might think “98 is close to 100,” and compute (100 − 2) × 14 = 1400 − 28 = 1372. That’s faster and less error‑prone.
To study this, the authors create a test called SenseMath to see whether AI models can:
- Use shortcuts when they should,
- Judge when a shortcut is or isn’t appropriate,
- Create new math problems that truly allow a shortcut.
What questions does the paper try to answer?
The paper focuses on four easy‑to‑understand questions:
- Do models naturally use shortcuts on their own?
- If they don’t, can they use shortcuts when we clearly tell them to?
- Do they mistakenly use shortcuts when they shouldn’t?
- Can they invent new problems that really do allow a shortcut?
These questions move from easier skills (apply a known shortcut) to harder ones (analyze when a shortcut fits) to the hardest (create new, valid shortcut problems). That mirrors how students progress from applying, to analyzing, to creating.
How did the researchers test this?
They built a large, carefully controlled set of 4,800 multiple‑choice questions across eight common shortcut types people use in mental math. Each question came in three matched versions:
- Strong: a clean shortcut works very well.
- Weak: a shortcut helps a bit, but you still need some calculation.
- Control: no shortcut really helps; you should do normal steps.
They also varied the “digit scale,” which just means how large the numbers look (2, 4, 8, or 16 digits), while keeping the same underlying pattern. For example, comparing 10/11 vs 11/12 uses the same idea as comparing 1110/1111 vs 1111/1112: check which is closer to 1.
The eight shortcut types included things like:
- Magnitude estimation: rounding to powers of 10 to see the “ballpark” answer.
- Structural decomposition: using near‑round numbers, like (100 − 1) × 37.
- Relative distance for fractions: comparing how close two fractions are to a landmark like 1.
- Cancellation and compatible numbers: noticing “almost canceling” parts or rounding to make easy products (like 250 × 4,000).
- Landmark comparison: using familiar benchmarks (like 50%).
- Equation reasoning: spotting structure in equations (like canceling common terms).
- Option elimination: ruling out wrong choices quickly by checking parity, last digit, or size.
They tested five popular LLMs and used three prompting styles (the instruction we give the model before it answers):
- Normal step‑by‑step (often called “chain‑of‑thought”): “Show your steps.”
- Number‑sense prompt: encourages easy, clever strategies without naming a specific shortcut.
- Strict: forbids shortcuts; must do full calculation. This serves as a “negative control.”
They ran three kinds of evaluations:
- Shortcut Use: Can the model use the shortcut when it’s clearly available?
- Applicability Judgment:
- J1: Given a problem, is a shortcut appropriate (YES/NO)?
- J2: Given a worked solution, did it use a shortcut or standard steps?
- Problem Generation: Can the model create a new, valid shortcut problem? They checked generated problems with code to verify the answer is correct and that a shortcut really exists (and is blocked in control versions).
What did they find, and why does it matter?
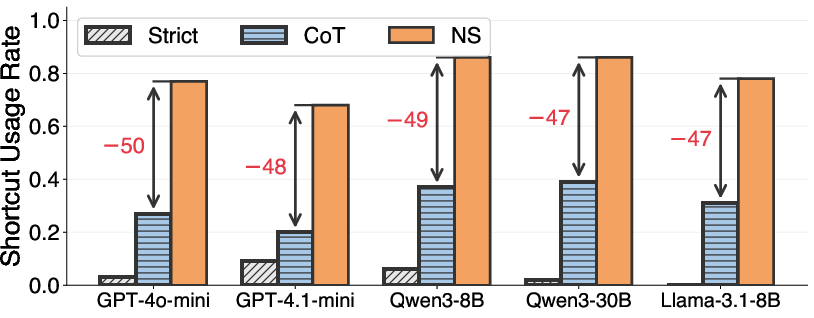
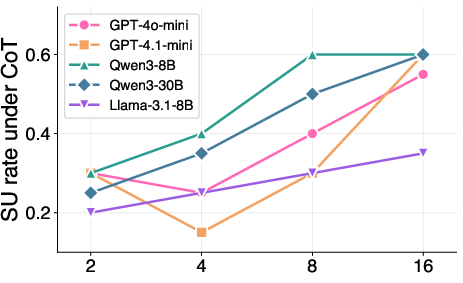
- Models rarely use shortcuts on their own. Under normal “show your steps” prompting, models used shortcuts in fewer than 40% of chances (with medium‑sized numbers). They often defaulted to long, step‑by‑step math.
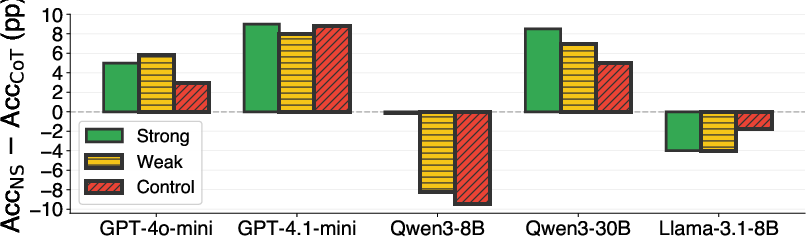
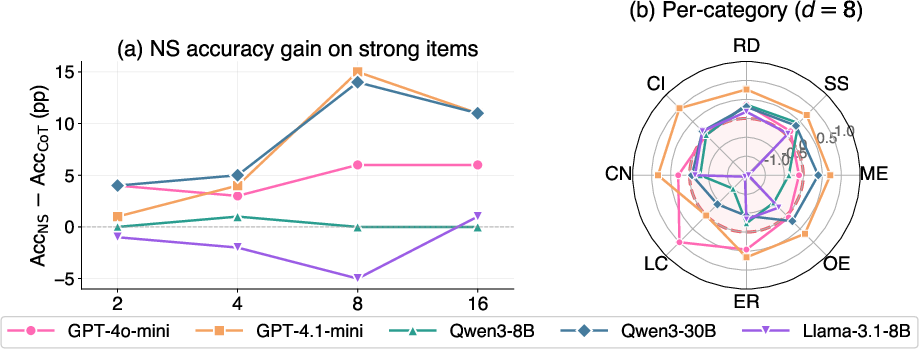
- If you nudge them, they can use shortcuts. When the prompt encouraged number sense, shortcut use jumped to about 68–86%, and accuracy on shortcut‑friendly questions improved—sometimes by as much as 15 percentage points. The benefits were larger when numbers looked bigger, because brute‑force math gets harder while a good shortcut stays easy.
- But many models overuse shortcuts. When asked if a problem allows a shortcut (J1), some models said “YES” almost all the time—even for control problems where no shortcut helps. This led to accuracy drops (up to 12%) on problems where shortcuts don’t apply.
- They can recognize a shortcut after the fact. In J2 (spotting whether a given solution used a shortcut), models did much better. In other words, they’re decent at identifying a shortcut that was used, but poor at deciding ahead of time when to use one.
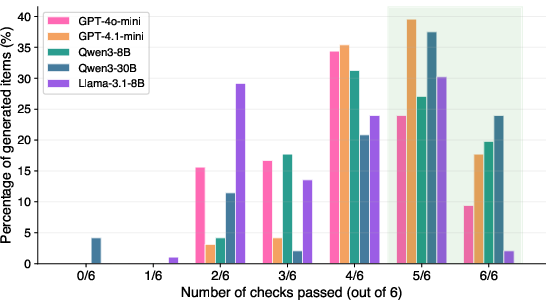
- Creating new shortcut problems is hard. Only about 2–24% of generated problems passed all checks. The most common failure: the problem looked like it should have a shortcut (numbers “looked round”), but the shortcut didn’t actually work. So models copied the surface style without truly getting the hidden structure that makes a shortcut valid.
- Training can help a bit. Special training nudging models toward number‑sense solutions gave small improvements for some models, and bigger gains for weaker models, but it didn’t close the gap entirely.
Together, these results show a consistent pattern: today’s models can perform shortcut procedures when prompted, but they don’t yet truly “understand” when and why a shortcut works.
What’s the bigger picture?
For classrooms and AI tutoring:
- Strength: Models can demonstrate clever tricks when told to, which can make solutions shorter and clearer.
- Weakness: They struggle to decide when a trick is the right tool and to craft new, good practice problems. This is a key part of human number sense—knowing the “why” and “when,” not just the “how.”
For AI research:
- There’s a gap between doing a procedure and understanding the structure behind it. SenseMath helps measure that gap by separating “apply,” “analyze,” and “create.”
- Future work should focus on teaching models to recognize structure, not just execute steps. That could make AI better teachers and more reliable problem solvers.
In short, the paper shows that current AI has “shortcut skills” but not full “number sense.” It can do the trick, but it doesn’t yet reliably know when to use it—or how to build new problems that truly need it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide follow-up research.
- Construct validity of “number sense”
- How well do the eight shortcut categories capture the breadth of human number sense (e.g., proportional reasoning, probabilistic/ratio reasoning, place-value flexibility with negatives/decimals, exponents/roots, modular arithmetic, units/measurement)?
- Does performance on SenseMath correlate with validated human number sense assessments on the same items, or with broader conceptual understanding (beyond procedural shortcut use)?
- Ecological validity and task realism
- The benchmark is programmatically generated with uniform multiple-choice templates; to what extent do findings transfer to realistic word problems, open-ended responses, and mixed-format assessments used in classrooms?
- Option-level shortcuts may be specific to multiple-choice formats; do the same behaviors hold under free-response settings where elimination is impossible?
- Generalization beyond covered operations and contexts
- Do results extend to more diverse numeric contexts (e.g., inequalities, integer arithmetic with negatives, division with remainders, manipulation of decimals/irrationals, logarithms), and to reasoning with units and measurement conversions?
- How do models handle multi-step word problems where shortcut cues are embedded in linguistic context, diagrams, or multi-modal inputs?
- Language, notation, and cultural transfer
- Are behaviors consistent across languages, numeral systems, and culturally distinct curricula and benchmarks?
- Do results depend on tokenization and number formatting (commas, decimal separators, scientific notation)?
- Sensitivity to prompting and decoding
- The study uses greedy decoding (temperature=0); does spontaneous shortcut use or applicability judgment change with sampling, self-consistency, or scratchpad variants?
- How robust are conclusions to alternative prompt framings for CoT/NS/Strict, and to meta-cognitive prompts that explicitly separate “decide-then-solve” stages?
- Reliance on CoT text for detecting shortcuts
- Shortcut usage is inferred from written rationales; how faithful are these traces to underlying computations, given known unfaithfulness in CoT?
- Can alternative process-tracking (e.g., tool invocation logs, intermediate arithmetic checks, verifier-based probes) yield more reliable shortcut-use detection?
- Applicability judgment calibration
- Models show extreme YES bias on J1 (appropriateness); what interventions reduce overgeneralization (e.g., calibrated uncertainty, explicit abstention training, counterfactual pairs)?
- Are there category-specific confounds (e.g., estimation framing that encourages “always yes”) that inflate misuse rates?
- Benchmark design and psychometrics
- Matched strong/weak/control variants are intended to isolate shortcut effects; are there residual difficulty differences across variants or categories (e.g., distractor plausibility, numeral length) that require psychometric calibration or IRT-style analyses?
- Are effect estimates stable under item re-balancing, alternative distractor parametrizations, or different digit-scale progressions?
- Statistical rigor and reliability
- The paper reports percentage gains without confidence intervals or significance testing; what is the variance across runs, seeds, and batches?
- How sensitive are results to model updates, context length limits, or server-side inference variability (especially for API models)?
- Model coverage and contemporary systems
- Findings are based on five instruction-tuned models; do O1/R1-style deliberate reasoning models, larger frontier models (e.g., Claude, Gemini), or tool-augmented systems show different Apply/Analyze/Create profiles?
- How do smaller/open-weight models behave under scaling laws targeted at number sense, and where are the capability thresholds?
- Tool use and hybrid reasoning
- The study intentionally avoids calculators/programs; can controlled use of tools coupled with meta-cognitive gating (when to estimate vs. compute) yield better applicability judgment without harming accuracy?
- Can verifier-critic loops or execution checks suppress shortcut overuse on controls?
- Training interventions and data
- NS post-training used small DPO datasets; what is the effect of larger-scale, counterfactually matched strong/weak/control training, or curricula that explicitly teach “when-not-to-shortcut” with dense negative examples?
- Can strategy selection be improved with multi-objective training (accuracy + applicability calibration + token efficiency), or with decision-first reinforcement learning signals?
- Mechanistic understanding
- What internal circuits or features drive shortcut discovery vs. overgeneralization, and can mechanistic probes separate procedural heuristics from structural understanding?
- Are there identifiable “applicability detectors” that can be strengthened or used to gate strategy selection?
- Generation evaluation fidelity
- The shortcut-existence check (SC.Ex) is the main bottleneck; does the verifier miss valid human shortcuts (false negatives) or accept spurious ones (false positives)?
- Would richer, category-specific formal specifications or search-based verifiers better capture the structural constraints that define a valid shortcut-bearing item?
- Transfer and longitudinal effects
- Does improving number sense on SenseMath transfer to gains on broader math benchmarks (GSM8K/MATH), to efficiency (tokens/time), and to robustness under perturbations (e.g., MATH-Perturb)?
- Do gains persist after model updates or fine-tuning on unrelated tasks, or do they require continual reinforcement?
- Safety and pedagogy
- Overgeneralization of shortcuts can mislead students; what guardrails (uncertainty calibration, counterexample prompting, reflective checks) are effective in tutoring settings?
- Can models reliably articulate “why a shortcut does not apply” and teach error-detection strategies, not just solutions?
- Human baselines and alignment
- How do human learners (novices vs. experts) perform on SenseMath across Apply/Analyze/Create, and do models mirror human error patterns?
- Can human-in-the-loop evaluation refine category definitions, difficulty calibrations, and the educational validity of the tasks?
- Computation–strategy trade-offs
- The paper reports limited token savings on one subset; what are the systematic trade-offs between shortcut use, accuracy, and compute across scales, categories, and models?
- Can models learn compute-aware strategy selection (when to shortcut vs. compute exactly) under explicit resource constraints?
- Data contamination and leakage
- Although items are programmatically generated, to what extent could template types or category descriptions overlap with pretraining data, and how would that affect claims about structural understanding vs. memorization?
- Multi-modal number sense
- Do findings extend to visual or embodied number sense (e.g., interpreting number lines, histograms, or measurement instruments), where human shortcuts often rely on spatial anchors and perceptual benchmarks?
Practical Applications
Below is an overview of practical applications derived from the SenseMath benchmark, its methods, and findings. Each item names sectors, outlines potential tools/workflows, and notes assumptions or dependencies that affect feasibility.
Immediate Applications
- SenseMath as a standardized evaluation suite for LLMs
- Sectors: software/AI, education, research
- What: Integrate SenseMath into internal QA and public leaderboards to assess “structural numerical understanding” beyond accuracy; use matched variants (strong/weak/control) and shortcut-invariant scaling to diagnose overgeneralization and spurious reasoning.
- Tools/workflows: CI gating for model releases; eval dashboards that report Shortcut Usage Rate, Applicability Judgment (J1/J2), and category-wise performance (ME, RD, OE, etc.); red-teaming for “shortcut overuse.”
- Assumptions/dependencies: Access to SenseMath dataset/code; consistent inference settings; agreement on evaluation protocols and reporting.
- Prompt-policy routing for math assistants
- Sectors: education, productivity apps, finance, customer support
- What: Add a lightweight classifier to decide whether a problem is “NS-amenable” (shortcut-friendly) and route to one of three prompt modes: Number-Sense (NS) for heuristics, CoT for general reasoning, or Strict for safety-critical exactness.
- Tools/workflows: Prompt router; few-shot NS-amenable classifiers; fallbacks to calculators/programs; logging of chosen strategy.
- Assumptions/dependencies: Classifier reliability; accurate detection of control-like items to avoid over-application; sufficient model capability (GPT-4.1-mini–tier) to benefit from NS prompting.
- Token and latency reduction by selective NS prompting
- Sectors: software/AI infra, cost-optimized SaaS
- What: On NS-amenable math tasks, switch to NS prompts to preserve or improve accuracy while reducing tokens and latency (as observed on MATH-500 subsets).
- Tools/workflows: Token-budget-aware reasoning policies; autoscaling with prompt selection; cost monitoring.
- Assumptions/dependencies: Gains depend on task mix (enough NS-amenable items) and model strength; careful monitoring to avoid accuracy regressions on control items.
- Safety mode for numerical decisions in sensitive domains
- Sectors: healthcare, finance, legal compliance
- What: Use “Strict” prompts (no shortcuts) for dosage, underwriting, tax computations, or regulatory filings; enforce external tool calling (calculators, spreadsheets) for exact arithmetic.
- Tools/workflows: Policy engine that detects sensitive use-cases and forces Strict mode; execution sandboxes; audit logs showing if/when shortcuts were used.
- Assumptions/dependencies: Robust policy detection; reliable tool integration; organizational buy-in for strictness over speed.
- AI tutor diagnostics focused on number sense
- Sectors: education (K–12, higher ed, edtech)
- What: Deploy SenseMath tasks in tutoring systems to differentiate “apply vs analyze vs create” abilities; provide formative feedback on when shortcuts are appropriate, not just how to execute them.
- Tools/workflows: LMS plugins; student dashboards with Bloom-aligned metrics; per-category practice sets (RD, CI, CN, OE).
- Assumptions/dependencies: Alignment with curricula; teacher-facing explanations; clear messaging about LLM limitations revealed in paper (e.g., over-generalization).
- Content generation with automatic validity checks
- Sectors: education, test prep, publishing
- What: Use the paper’s six deterministic checks (format, answer correctness, shortcut existence, control blocking, variant matching, digit scale) to vet LLM-generated math items before release.
- Tools/workflows: Item-authoring pipelines; server-side verification harness; rejection sampling with retry loops.
- Assumptions/dependencies: Coverage/recall of automated checks; editorial oversight for edge cases.
- Procurement and policy guidance for edtech adoption
- Sectors: policy, school districts, education procurement
- What: Require vendors to report SenseMath-style metrics (shortcut usage, applicability judgment, generation validity) in addition to accuracy; set thresholds for classroom deployment.
- Tools/workflows: RFP checklists; model cards with SenseMath sections; periodic re-certification.
- Assumptions/dependencies: Stakeholder consensus on metrics; reproducibility of results across versions.
- Developer-facing quality controls for numeric features
- Sectors: software engineering, fintech apps, calculators/spreadsheets
- What: Add matched-variant tests (strong/weak/control) to CI to ensure agents and copilots don’t overuse heuristics; regressions flagged when control performance drops or YES-bias increases in J1.
- Tools/workflows: Unit tests that include shortcut traps; “applicability judgment” probes; CI badges for structural competence.
- Assumptions/dependencies: Test maintenance; mapping of app-specific numeric tasks to SenseMath categories.
- Model selection and routing for multi-model stacks
- Sectors: AI platforms, integrators
- What: Use SenseMath metrics to choose which model handles numerical tasks; route harder or control-like cases to more robust models or to exact computation tools.
- Tools/workflows: Capability registry (per-category scores, digit-scale curves); dynamic routing rules; graceful degradation paths.
- Assumptions/dependencies: Cost–latency–accuracy trade-offs; stable vendor APIs.
Long-Term Applications
- Post-training for structural number sense at scale
- Sectors: model labs, edtech platforms, research
- What: Expand DPO/SFT/RL approaches that prefer NS-style solutions when appropriate and penalize misuse on control variants; train applicability judges; distill into smaller models.
- Tools/workflows: Preference datasets pairing NS vs CoT traces; negative examples to curb YES-bias; curriculum that progresses Apply → Analyze → Create.
- Assumptions/dependencies: High-quality labels for applicability; scalable data generation beyond arithmetic; compute budgets.
- Agentic solvers with strategy selection and tool-use governance
- Sectors: software/AI, finance, operations
- What: Build agents that explicitly decide between heuristic, exact, and tool-assisted computation, with uncertainty-aware gating and explanations (“why shortcut is/ isn’t safe here”).
- Tools/workflows: Strategy arbitration modules; confidence calibration; post-hoc J2-style checks that verify stated strategy matches actual computation.
- Assumptions/dependencies: Reliable applicability predictors; faithful reasoning traces; integration with calculators/CAS.
- Domain-general “structure sense” benchmarks
- Sectors: science education, engineering, policy analytics
- What: Port the matched-variant + invariant-scaling design to physics, chemistry, and economics to measure when models exploit structure vs brute-force formulas.
- Tools/workflows: Template generators and verification suites per domain; Bloom-aligned tasks (Apply/Analyze/Create).
- Assumptions/dependencies: Domain experts to define shortcuts and controls; automated checkers for structural validity.
- Robust AI tutors that teach when/why to use strategies
- Sectors: education
- What: Next-gen tutors that detect the structural cue, explain applicability, and generate scaffolded practice that preserves the shortcut’s constraints; prevent overgeneralization by contrasting strong vs control items.
- Tools/workflows: Adaptive sequencing; constraint-preserving item generators; teacher dashboards showing students’ “applicability judgment” growth.
- Assumptions/dependencies: Advances in LLM problem generation that satisfy shortcut-existence checks; alignment with standards and assessments.
- Regulatory standards for AI math assistance
- Sectors: policy, accreditation bodies, compliance
- What: Create minimum competency standards (accuracy on control variants, rejection rates in J1, generation validity rates) for AI used in classrooms and high-stakes contexts.
- Tools/workflows: Certification suites; periodic audits; public reporting requirements.
- Assumptions/dependencies: Consensus on thresholds; independent test centers; handling of model updates/drift.
- Cognitive architecture components for numerical structure detection
- Sectors: model research, neurosymbolic AI
- What: Specialized modules that detect patterns like near-cancellation, benchmark proximity, compatible numbers, or OE heuristics; plug-ins that trigger or disable shortcuts accordingly.
- Tools/workflows: Hybrid LLM–symbolic detectors; feature probes; training with auxiliary losses for structure recognition.
- Assumptions/dependencies: Transferability across tasks; avoiding spurious cues; interpretability and debiasing.
- Compliance-grade logging and replay for numerical decisions
- Sectors: finance, healthcare, public sector
- What: Log whether a shortcut was used, the applicability score, and any tool calls; enable audits/replay to trace errors from heuristic misuse.
- Tools/workflows: Strategy metadata in traces; immutable audit logs; policy alerts when heuristics appear on control-like items.
- Assumptions/dependencies: Privacy and governance frameworks; standardized telemetry for LLM workflows.
- IDE and testing support for numeric correctness
- Sectors: software engineering, data science
- What: Plugins that generate matched variants of numeric test cases; detect shortcut-like brittle logic in code or prompts; recommend Strict/tool-call paths for safety.
- Tools/workflows: Test generators aligned to SenseMath categories; static/dynamic analyzers; CI integrations.
- Assumptions/dependencies: Mapping from code to numeric reasoning patterns; developer adoption.
- Large-scale numeracy diagnostics and curriculum analytics
- Sectors: education policy, assessment
- What: Use matched-variant tasks and applicability judgments to measure student number sense at population scale; inform curricula emphasizing structural reasoning.
- Tools/workflows: Psychometric models leveraging control vs strong contrasts; district-level dashboards; longitudinal tracking.
- Assumptions/dependencies: Ethical data use; validation across demographics; integration with existing assessments.
- Cross-domain safety playbooks for heuristic control
- Sectors: healthcare, energy, robotics
- What: Pattern libraries specifying when heuristics are acceptable vs forbidden, with auto-detection hooks; e.g., disallow estimation in medication dosing, allow OE-style elimination in multi-choice triage.
- Tools/workflows: Domain-specific policy packs; runtime guards; simulation-based validation.
- Assumptions/dependencies: Accurate domain policies; robust detection of scenario types; human oversight.
Notes on overarching dependencies and risks:
- Many benefits rely on models at least as capable as GPT-4.1-mini; 8B-class models may degrade under NS prompting and overapply shortcuts.
- Applicability classification is a linchpin; misclassification leads to over-generalization and accuracy loss on control items.
- For safety-critical use, external calculators/programs and Strict prompts should remain the default; LLM explanations should be advisory.
- Generalization beyond arithmetic requires new, domain-specific shortcut taxonomies and verification checks.
Glossary
- Applicability Judgment: A task asking models to decide whether a numerical shortcut is appropriate for a given problem or whether a solution uses a shortcut. "Applicability Judgment."
- Bloom’s Taxonomy: An educational framework categorizing cognitive skills from lower to higher levels (e.g., apply, analyze, create), used here to structure evaluation. "Following Bloomâs Taxonomy \citep{bloom1956taxonomy,krathwohl2002revision}"
- Cancellation (CI): A shortcut that exploits near-opposite terms in an expression to simplify computation by reducing components that nearly cancel out. "Cancellation (CI) tests sensitivity to near-cancellation patterns in expressions like when "
- Chain of Draft: A reasoning-efficiency method that aims to shorten or sketch reasoning compared to full chain-of-thought derivations. "methods like Chain of Draft \citep{kim2024chain}"
- Chain-of-thought (CoT) prompting: A prompting technique that elicits step-by-step reasoning in LLMs to improve problem solving. "Chain-of-thought (CoT) prompting \citep{wei2022chain, kojima2022large}"
- Cognitive Load Theory: A theory that distinguishes types of cognitive load (intrinsic, extraneous) and guides instructional design to optimize reasoning and learning. "We follow Cognitive Load Theory \citep{sweller1988cognitive} to construct items"
- Compatible numbers (CN): A mental-math strategy that rounds numbers to “friendly” values to make multiplication or division easier. "Compatible numbers (CN) assesses whether models can identify product-friendly rounding opportunities"
- Digit scale: A controlled parameter indicating the length (number of digits) of numbers in problems to vary intrinsic difficulty without changing structure. "four digit scales ()"
- Direct Preference Optimization (DPO): A post-training approach that optimizes models using preference pairs rather than supervised labels to shape outputs. "We fine-tune Qwen3-8B and Llama-3.1-8B with DPO on 500 MATH problems"
- Equation reasoning (ER): A shortcut category focused on algebraic structure, recognizing identities and cancellations to reduce multi-step algebra. "Equation reasoning (ER) moves beyond arithmetic to algebraic structure"
- Extraneous load: Non-essential cognitive burden imposed by presentation or format, controlled here to isolate true reasoning difficulty. "while extraneous load is held constant"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step (temperature 0), yielding deterministic outputs. "All inferences use greedy decoding (temperature) and ."
- Intrinsic cognitive load: The inherent difficulty of the material itself, manipulated via digit scale and shortcut availability. "two orthogonal dimensions of intrinsic cognitive load"
- Landmark comparison (LC): A shortcut using familiar reference points (e.g., 50%, 1) to compare quantities without exact computation. "Landmark comparison (LC) probes the use of familiar reference points"
- Magnitude estimation (ME): A shortcut approximating results (e.g., products) by rounding to nearby powers of ten to check plausibility or order of magnitude. "Magnitude estimation (ME) tests the ability to approximate products by rounding operands to nearby powers of 10"
- Matched Shortcut Variants: Controlled item variants (strong, weak, control) sharing surface form but differing in shortcut applicability to isolate strategy effects. "each scaled item is further expanded into three Matched Shortcut Variants (strong, weak, and control)"
- Meta-reasoning: Reasoning about strategies themselves (e.g., deciding to eliminate options) rather than computing exact answers. "Option elimination (OE) tests a meta-reasoning ability"
- Negative control: A condition designed to suppress a phenomenon (here, shortcuts) to validate experimental comparisons. "serving as a negative control."
- Number sense: Flexible, structure-aware numerical reasoning that recognizes when and why shortcuts apply, beyond mere computation. "A central concept capturing human mathematical reasoning ability is number sense"
- Option elimination (OE): A multiple-choice shortcut that rules out implausible answers via quick checks (e.g., parity, magnitude) without full calculation. "Option elimination (OE) tests a meta-reasoning ability"
- Out-of-distribution (OOD) benchmarks: Evaluation datasets that differ from training data distributions to test generalization. "without degrading generalisation across 7 OOD benchmarks"
- Rejection sampling: A generation technique that samples candidates and discards those failing constraints to ensure correctness and control. "with rejection sampling to guarantee answer correctness"
- Shortcut-Invariant Scaling: A scaling procedure that increases numerical size while preserving the structural cue that licenses the shortcut. "Shortcut-Invariant Scaling."
- Shortcut Usage Rate: A metric measuring how often models employ shortcut-based reasoning when it is applicable. "Shortcut Usage Rate, which measures the proportion of responses that use shortcut-based reasoning on instances where such strategies are applicable."
- Sketch-of-Thought: An efficiency method that prompts concise, high-level reasoning sketches instead of full chains of thought. "Sketch-of-Thought \citep{aytes2025sketch}"
- Structural shortcuts (SS): Shortcuts that exploit algebraic identities or proximity to round numbers to simplify computations. "Structural shortcuts (SS) require recognising and exploiting algebraic identities near round numbers"
- Tensor parallelism: A model-serving technique that splits tensors across devices to parallelize inference for large models. "Open-weight models are served via vLLM with tensor parallelism"
- Token-Budget-Aware reasoning: Methods that constrain or optimize the number of tokens used during reasoning to improve efficiency. "Token-Budget-Aware reasoning \citep{han2024tokenbudget}"
- vLLM: A high-throughput inference engine for LLMs optimized for serving and parallelism. "Open-weight models are served via vLLM with tensor parallelism"
Collections
Sign up for free to add this paper to one or more collections.