- The paper proposes A3D-RA, a novel relational algebra that extends traditional operators to efficiently process array-valued attributes in columnar systems.
- It presents a rule-based and cost-based transformation framework that achieves speedups up to 38.75× and resolves memory limitations in complex queries.
- The integration of A3D-RA with DBMS platforms like ClickHouse, Umbra, and Snowflake demonstrates substantial improvements in query execution time and resource utilization.
Optimizing Relational Queries over Array-Valued Data in Columnar Systems
Introduction and Motivation
Many contemporary analytical workloads, especially in finance, IoT, and ML data engineering, require support for denormalized tables with array-valued attributes. Columnar database systems provide high throughput and performance on read-heavy queries; however, native optimizers in these systems are typically limited in how they optimize queries that interleave classical relational algebra operators with array manipulations. This limitation leads to suboptimal query plan generation, intermediate result explosion, and even infeasible query execution due to memory bounds.
This paper (2604.01967) proposes A3D-RA, an extended relational algebra engineered explicitly for array-valued attributes. The algebraic foundation, a comprehensive set of transformation rules, and a plan enumeration strategy are developed for seamless integration with existing DBMS engines through an optimizer layer. The empirical results demonstrate that this approach yields significant runtime and memory usage benefits across various systems and real-world industrial datasets.
A3D-RA extends the relational algebra to support tuples containing both scalar and array-valued columns, with precise semantics for operators acting on arrays. The central operator extensions include:
- ArrayJoin (μ): Unnests array columns, expanding each row into multiple rows.
- ArrayFilter (ϕ): Applies an element-wise predicate to array columns.
- Derive (δ): Enables computation of new columns, supporting both scalar and per-element array derivations.
- Aggregation (Γ): Supports grouping and computation of aggregations over both scalars and arrays.
The semantics are carefully defined for compositions of these new and traditional relational operators, including the handling of positional correspondence in multi-array transformations. The data model partitions columns into scalar and array types, and formalizes array correlations, invertibility of predicates, and compositional operator semantics.
A3D-RA provides a comprehensive set of equivalence-preserving transformation rules enabling algebraic rewritings that expose new optimization opportunities. These include pushing down filters and derived computations beneath expensive array operations, as well as a detailed characterization of when these rewrites are safe (rule-based) or require cost-based justification.
Key classes of transformation rules include:
- Filter and Projection Pushdown: Pushing σ and Π through μ and ϕ when the relevant predicates/columns are unaffected by array transformations.
- Operator Commutativity and Distribution: Establishes which operator pairs commute and when distributive laws apply, particularly for joins, array filters, derives, and aggregations.
- Pre-aggregation Introduction: Enables pre-aggregation beneath expensive operators, reducing intermediate result size and query cost.
Strong empirical evidence is provided that the most substantial performance improvements derive from rules that move computation, filtering, and aggregation closer to the base data, especially before row-multiplying array expansions.
Plan Enumeration and Optimality
The core of the optimizer is an enumeration procedure that (1) introduces all relevant algebraic operators, (2) generates all valid rewritings consistent with operator dependencies, and (3) selects optimal plans based on a selectivity- and cost-aware ranking strategy. The enumeration algorithm is proven to be polynomial in the number of non-join operators and integrates techniques from both the Volcano optimizer paradigm and task scheduling theory for optimal unary operation ordering.
Optimization time and complexity scaling are empirically quantified, confirming quadratic to slightly super-quadratic scaling in the number of array-centric patterns and arrays per pattern. These results show that, in practical analytical workflows where such counts are relatively modest, the optimization cost remains negligible relative to query execution times.
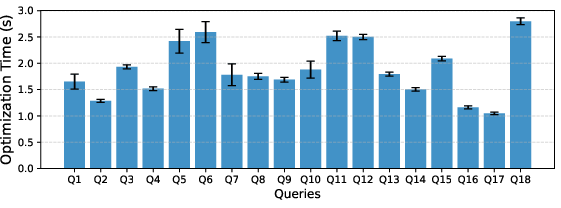
Figure 2: Distribution of optimization times on 18 real-world analytical queries, with all times within a practical interactive range (≤ 3s).

Figure 4: Polynomial complexity scaling in optimization time as the number of patterns in the algebraic query increases.

Figure 6: Optimization time scaling with the number of arrays per pattern shows manageable growth, confirming feasibility for typical workloads.
Experimental Validation
Evaluation is conducted on real and synthetic workloads using 100+ million row datasets with significant array-valued heterogeneity. The optimizer is instantiated for ClickHouse, Umbra, and Snowflake backends, all among the most performant analytical engines available.
Execution Time and Resource Usage
A3D-RA demonstrates significant execution time reduction and enables queries that previously failed due to resource constraints:
- ClickHouse: All queries benefited, with speedups up to 38.75× (mean 11.02×), and previously infeasible queries (due to memory errors) now completing in seconds.
- Umbra: Allowed successful execution of several queries failing natively, with moderate speedups (up to 6.4×).
- Snowflake (XS & L): Consistent mean speedups (up to 14.68× on XS, up to 2.73× on L), validating value across both limited and scaled resources.
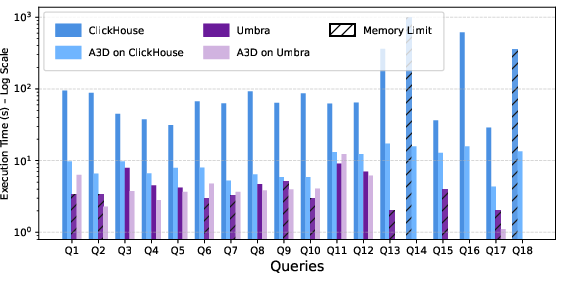
Figure 7: Query runtime comparison for ClickHouse and Umbra with and without A3D-RA, highlighting both speedups and enablement of previously infeasible queries.
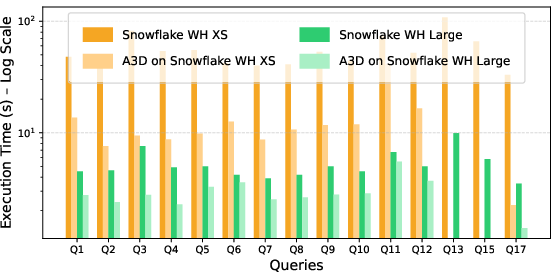
Figure 8: Snowflake warehouse runtimes before and after A3D-RA optimization; substantial reduction even for Large configurations.
Rule Impact and Analysis
Synthetic workload experiments isolate the impact of specific transformation rules:
- Filter Pushdown: Achieves up to 4× speedup and is critical for memory efficiency.
- Derive Pushdown: Reduces redundant computation and reshaping, with up to 2.79× speedup.
- Invertibility and Plan Branching: Enables selection among divergent execution plans, with major performance differences, especially in join-heavy queries.
- Pre-aggregation Introduction: Most pronounced in queries with heavy array flattening, raising up to 9.22× speedup.
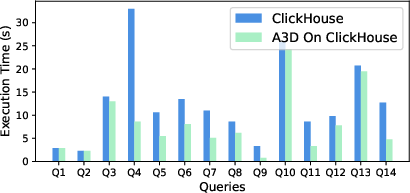
Figure 9: Horizontal and vertical pushdown of filters under ArrayJoin reduces cardinality, yielding up to 4× runtime improvement.
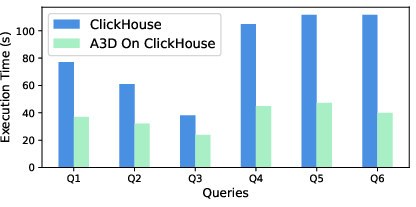
Figure 10: Pushing derive under ArrayJoin avoids duplicate computation after row explosion, further reducing computation.
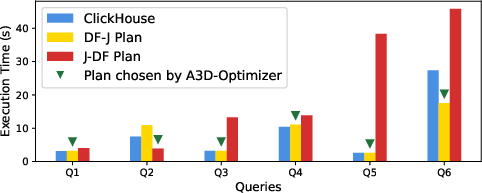
Figure 11: Alternative plans for non-invertible filters; plan selection highly impacts query feasibility and performance.
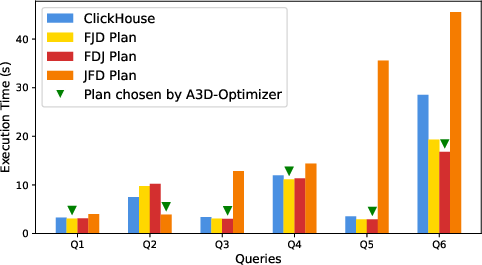
Figure 12: Plan reordering enabled by filter invertibility; enables optimal placement of joins, filters, and derives.
Practical and Theoretical Implications
This work establishes an algebraic framework for systematic, backend-independent optimization of array-centric analytical queries. The practical implications are direct: by integrating as a logical plan optimization layer, existing analytical DBMSs can support high-performance, resource-efficient analytics on denormalized, array-rich data models without engine modification.
Theoretically, A3D-RA demonstrates that extending relational algebra with expressive, equivalence-preserving operator families—together with a complete, complexity-aware enumeration and cost model—delivers both strong optimality guarantees and practical efficiency. This closes the optimization gap present in native backends, notably in array manipulation and flattening-heavy workloads, and provides a foundation for future work in integrating further nested and semi-structured features into the relational paradigm.
Conclusion
A3D-RA extends the scope and power of relational algebra to array-valued data, equipping the modern analytic stack with the ability to optimize complex, multi-modal queries that blend relational and array-processing logics. The proposed transformation rules and enumeration strategies unlock optimization opportunities unobtainable by existing DBMS-native optimizers, yielding substantial execution time and resource benefits. The modular optimizer can be deployed atop existing systems, confirming the viability and necessity of algebraic approaches to evolving analytical workloads. Future work could address extension to even richer nested types, further integration with machine learning dataflows, and automated selectivity/cost estimation pipelines.

