- The paper shows that DRL-based dynamic algorithm configuration outperforms static tuning on unseen, larger instances with up to 3.2% improvement in scheduling objectives.
- It employs a PPO-trained DRL controller to adjust memetic algorithm parameters using a multi-dimensional state representation and a carefully designed reward system.
- Empirical results highlight that investing in DRL pays off primarily in complex, variable problem settings, enabling robust transferability and reduced carbon emissions.
Deep Reinforcement Learning for Dynamic Algorithm Configuration in Carbon-Aware Scheduling
Introduction
This paper addresses the intersection of dynamic optimization and sustainability by studying whether Deep Reinforcement Learning (DRL) applied to Dynamic Algorithm Configuration (DAC) yields practical and transferable benefits for carbon-aware scheduling. The focus is on the permutation flow-shop scheduling problem (PFSP) augmented with explicit minimization of Scope 2 GHG emissions—a critical consideration in manufacturing optimization given electricity’s time-varying carbon intensity. The central contribution is a DRL-based DAC framework—denoted MA-DRL-CAS-PFSP—which is rigorously compared to static tuning in a scenario partitioned into known (training-aligned) and unknown (previously unseen, larger-scale) instance types. The study establishes when investing in DRL pays off in terms of solution quality, transferability, and robustness.
The carbon-aware PFSP extends classical makespan minimization by introducing a time-dependent objective that models both renewable and grid electricity with dynamic emissions factors. The scheduler explicitly leverages periods of reduced grid intensity and maximizes renewable utilization to minimize total GHG output, rather than just minimizing completion time.
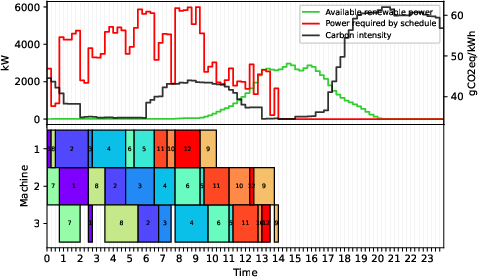
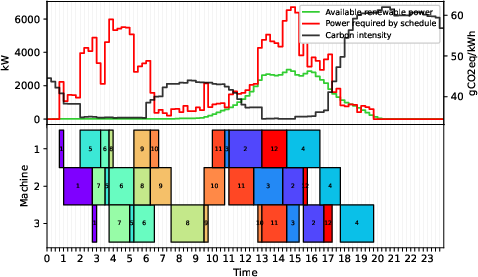
Figure 1: Two optimal schedules compared—minimizing makespan vs. minimizing total carbon emissions ($7.00$ tCO2 vs. $4.85$ tCO2), illustrating the impact of carbon-aware objectives.
The core optimization algorithm is a memetic algorithm (MA), which combines a genetic algorithm with a local search operating over a dual random-key encoding, optimizing both sequencing and slack-time placement. In the static regime, parameters governing crossover, mutation, and local search are either default or tuned via hyperparameter optimization. The DAC setup instead allows these parameters to be dynamically adapted at each iteration.
MA-DRL-CAS-PFSP: Proximal Policy Optimization for DAC
The DAC problem is formulated as an episodic MDP where:
- State: 5D normalized vector capturing best/mean fitness, search diversity, remaining budget, and stagnation count—deliberately designed to support cross-instance generalization.
- Action: 7D continuous vector mapping directly to MA parameters, rescaled to literature-aligned ranges to ensure expressivity without destabilizing policy learning.
- Reward: Change in normalized best fitness, with later-stage improvements upweighted by squaring, normalizing to an offline "ideally" tuned solution.
The DRL controller is trained using PPO and only on small/simple instances, aiming to discover policies that are robust and transferrable to problem classes not present at training time.
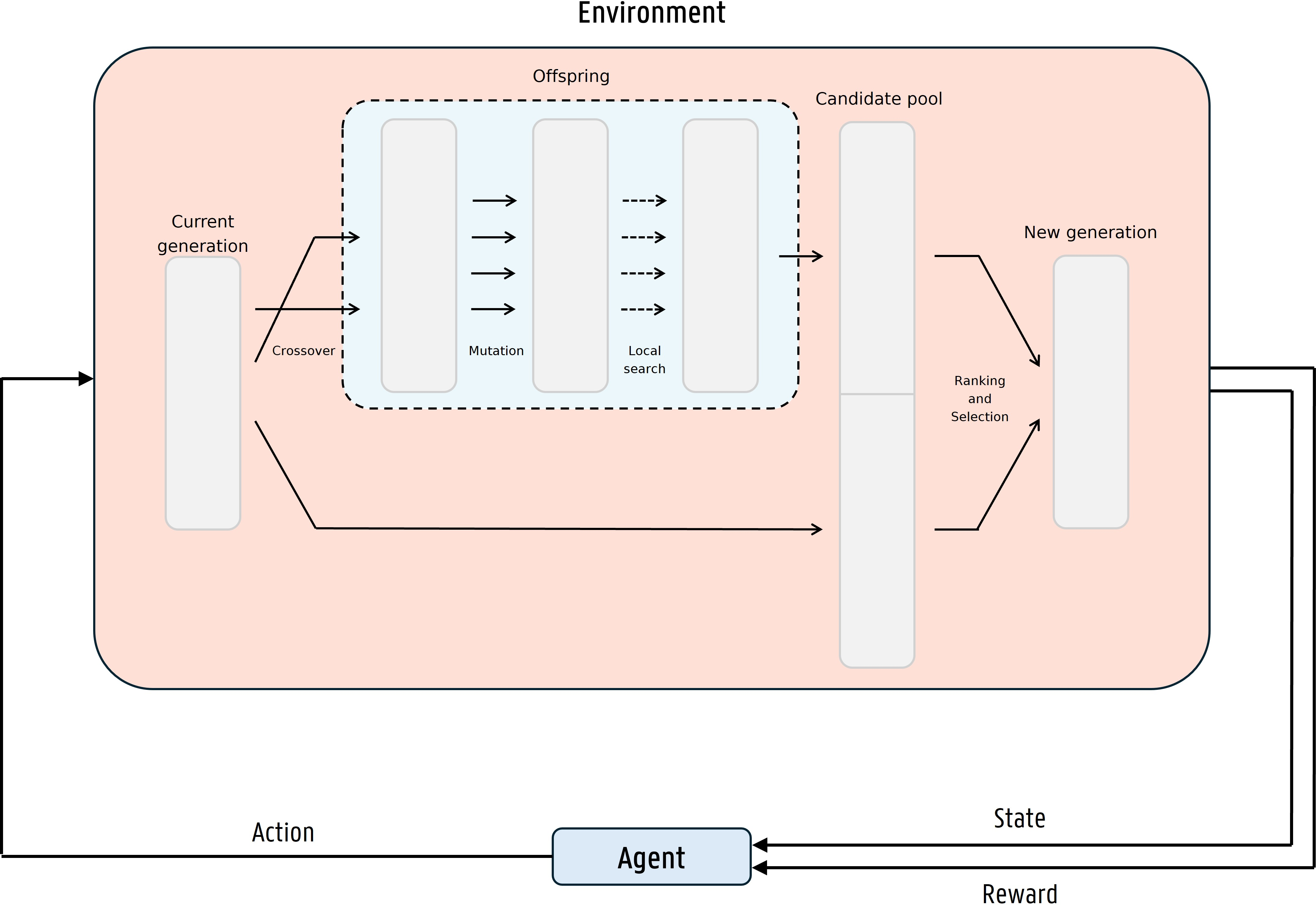
Figure 2: High-level schematic of the MA-DRL-CAS-PFSP system where the DRL policy iteratively configures the memetic algorithm's parameters given search state feedback.
Learning proceeds until episode reward converges, monitored as mean performance over all training instances.
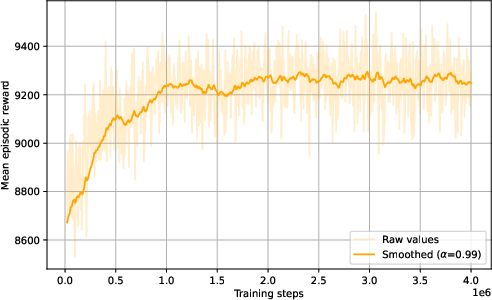
Figure 3: Learning curve of mean episode reward during PPO training.
Experimental Design
The empirical evaluation covers ten datasets, four "known" (used for training/tuning) and six "unknown" with higher combinatorial complexity (primarily increased machine counts), partitioned to isolate generalization effects. Static tuning of MA parameters uses Optuna with the same computational budget as DRL training ensuring strict fairness. Each configuration is tested across 50 instances × 10 runs per method, reporting mean/best objectives and statistical dominance.
Results: Transferability, Generalization, and When DRL Helps
Known Instance Types (Training-aligned):
- MA-DRL performs equivalently to static tuning and default parameters.
- No statistically or practically significant improvements are found; when parameter space is well-covered during tuning/training, offline methods suffice.
Unknown Instance Types (Larger/Unseen):
- DRL-based DAC consistently outperforms static tuning as combinatorial complexity increases.
- For moderate complexity increases (e.g., M5T3), gains are small (approx. 0.3%) but statistically consistent.
- For the largest/more complex datasets (M10T3, M15T3), improvements reach up to 3.2% in objective value relative to static tuning—substantial in practical GHG emissions or cost terms.
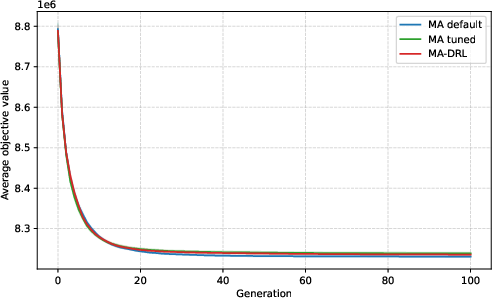
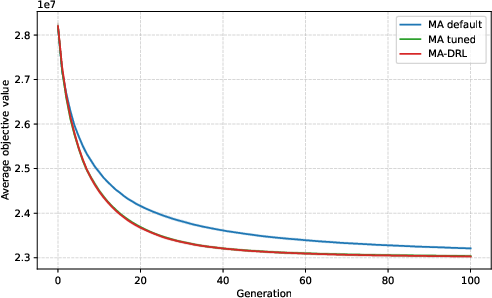
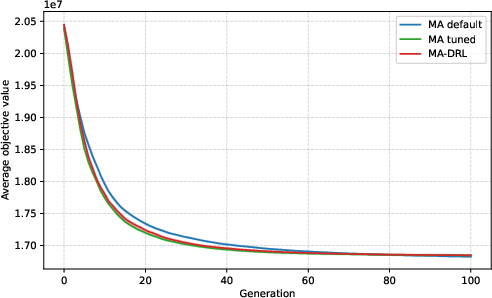
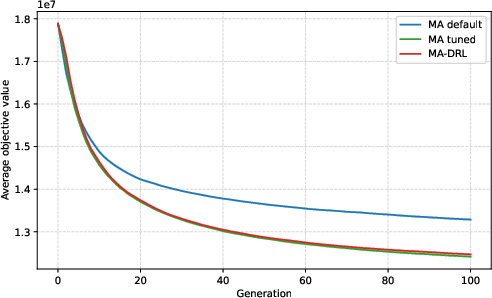
Figure 4: Convergence trajectory for the smallest known instance dataset (CAS-PFSP-M1T1); all methods converge similarly, and DRL offers no tangible benefit on well-covered distributions.
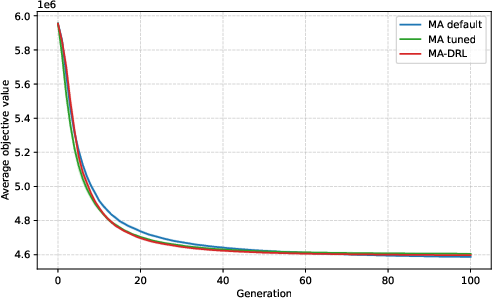
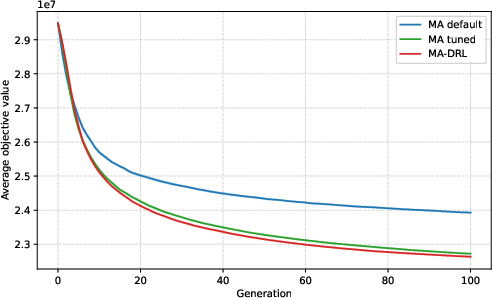
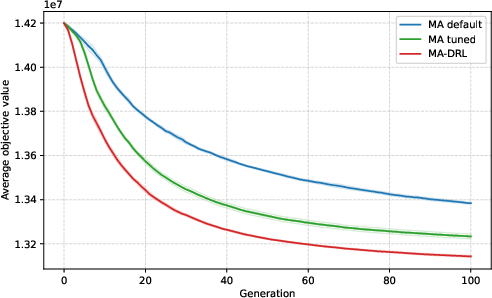
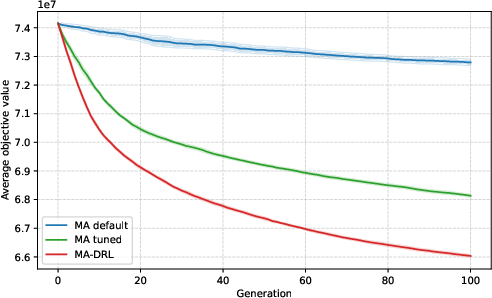
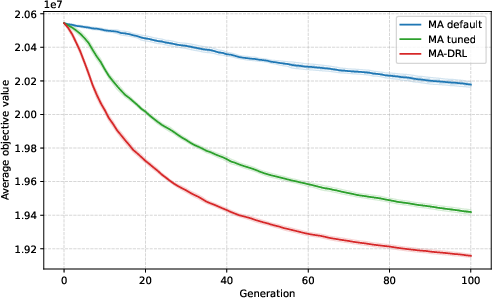
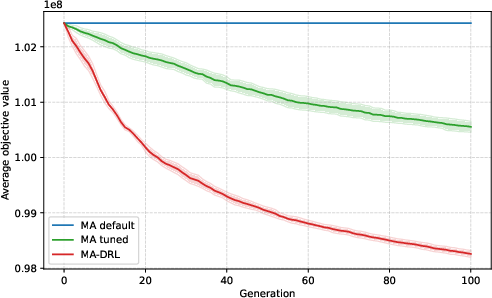
Figure 5: Convergence on a more complex, unseen instance type (CAS-PFSP-M5T1); DRL shows improved asymptotic solution quality as combinatorial complexity increases.
These patterns robustly demonstrate: The value of DRL-based DAC emerges predominantly out-of-distribution—i.e., on instances whose size or structure is not seen during policy learning or offline static tuning.
Implications and Future Work
Practically, this places DRL-based DAC as the preferred configuration modality where:
- Problem size/structure is variable or hard to anticipate;
- Repeated retuning of parameters is infeasible;
- One-off policy training (even on smaller/simpler instances) can amortize cost by enabling transfer to much larger, more valuable deployment cases.
Theoretically, the results reinforce the need for MDP state/action design that is instance-agnostic but information-rich; the capability to generalize is tightly linked to both the expressivity of the parameter space and the regularization in policy learning.
Avenues for theoretical extension include formalizing policy transferability bounds wrt. instance space coverage, and augmenting search dynamics features with richer search trajectory summaries. Practically, work on cross-problem generalization (training DAC controllers for one combinatorial class and deploying on another with a shared search model) may yield broadly reusable configuration policies for evolutionary AI and metaheuristics.
Conclusion
The study provides a systematic answer to the central question: Learning-based DAC via DRL is only beneficial over static tuning when the deployment distribution is both larger or structurally different from the training/tuning distribution. Generalization is robust when the state and action spaces are appropriately abstracted, and substantial computational savings are achieved by eliminating costly per-instance retuning on complex schedules. DRL-based DAC should, therefore, be viewed as a strategic investment to future-proof optimization pipelines in scenarios demanding rapid adaptation and sustainable operational objectives, especially as carbon-aware scheduling becomes central in manufacturing and operational research.

