- The paper’s main contribution is Model-Bench, a benchmark and pipeline that systematically transforms Python programs into TLA+ specifications for model checking.
- It employs deterministic code transformation via control flow graph construction and few-shot prompting to evaluate multiple LLMs on formal verification tasks.
- Experimental results reveal a tradeoff where code transformation improves state trace similarity at the cost of reduced runnable success, highlighting structural challenges for current LLMs.
Introduction and Motivation
Formal verification offers a rigorously reliable methodology for ensuring software correctness, particularly essential for safety-critical and infrastructure-dependent systems. Despite the expanding capability of LLMs in code generation and theorem proving, automatic derivation of verification-ready formal models—especially for model checking—remains largely unsolved. This paper presents Model-Bench, a benchmark and accompanying pipeline designed to assess and enhance LLMs' abilities to translate Python programs into TLA+ specifications suitable for exhaustive model checking. This effort is motivated by the need to fill the methodological gap between advanced LLM-driven theorem proving and the lack of comparable tools for model checking, particularly in automating the construction of executable, sound behavioral models from source code.
Model-Bench Construction Pipeline
Model-Bench comprises 400 Python programs drawn from the HumanEval, MBPP, and LiveCodeBench benchmarks, systematically normalized, simplified, and refactored to maximize coverage of core program logic and ensure compatibility with TLA+ model checkers.
The data processing pipeline involves deduplication, elimination of extraneous libraries, and systematic rewriting of advanced Python features (e.g., list comprehensions, lambdas, generators, recursion) into semantically equivalent but TLA+-compatible code. Complex type constructs and dependencies outside typing and math are excluded. Functional correctness is enforced via runtime verification with per-problem test suites.
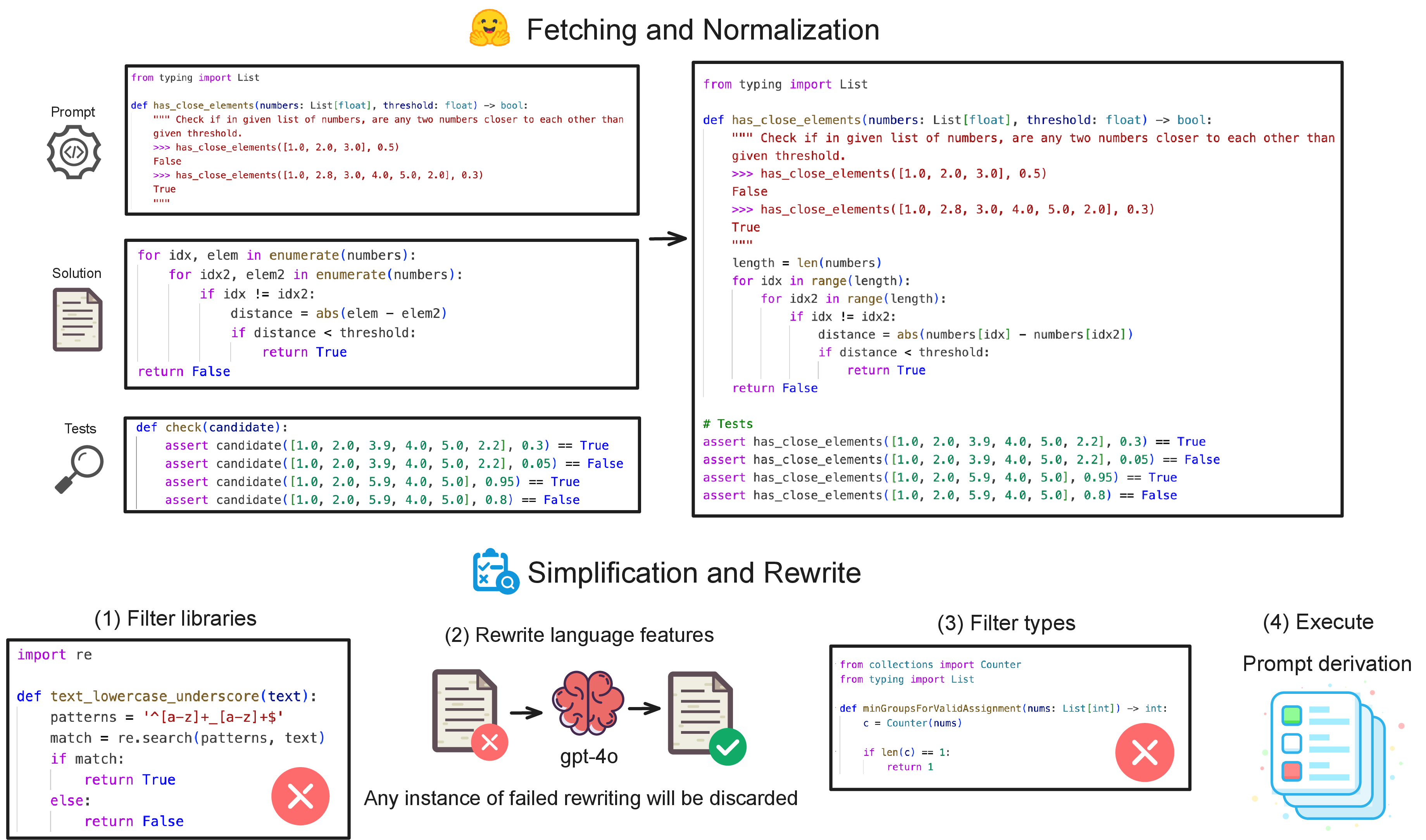
Figure 1: Overview of data processing from benchmark extraction to code normalization and verification-ready test harnessing.
Recognizing the semantic gap between Python's high-level execution model and TLA+'s discrete state machine formalism, the authors introduce a deterministic code transformation. Each Python program is lowered into a state-machine-resembling imperative form via CFG construction, node assignment, and global variable initialization. The principal execution structure becomes a while loop over an explicit program counter, accompanied by if-branches corresponding to CFG nodes. This approach enhances alignment with TLA+'s event/action semantics and addresses weaknesses in LLMs’ ability to generalize program control flow.
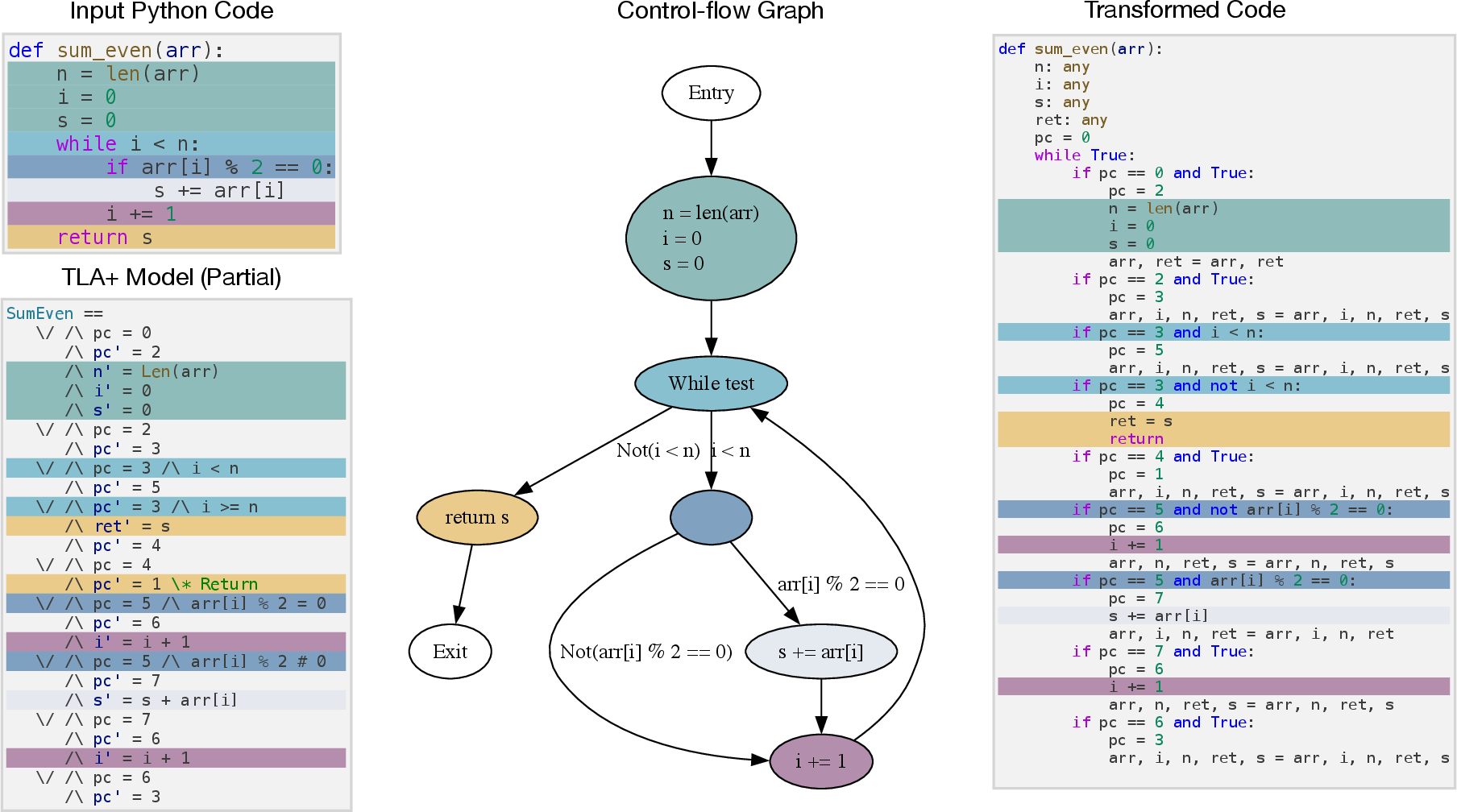
Figure 2: The transformation workflow maps Python ASTs through CFGs to a TLA+-like imperative form, bridging between source code and model checking spec.
Evaluation Protocols and Metrics
Evaluations leverage GPT-4o and several state-of-the-art open-source LLMs (DeepSeek, Qwen3, Gemma, Llama 3.1) under few-shot and zero-shot prompt regimes. Each LLM generates TLA+ models given original or transformed Python code; these outputs are validated by the TLC model checker. Success rates are reported via Runnable@k metrics (proportion passing model checking within three attempts) and a custom similarity metric, which quantifies state-wise execution trace congruence between model-generating LLM output and a manually crafted ground-truth TLA+ model. The similarity threshold used is strict (all variable-value pairs must coincide, θ=1.0).
Experimental Results and Analysis
Substantial variability is observed between models and prompt setups. The best-performing model, DeepSeek-V3, achieves a Runnable@1 of 51.75% and average state similarity of 49.55% with standard (original code, few-shot) prompting; top-3 models (DeepSeek-V3, -V2.5, Qwen3-32B) consistently outperform others.
Few-shot exemplars dramatically boost LLM ability to produce verification-ready specs: average Runnable@1 is 26.82% (few-shot) versus 9.25% (zero-shot), with even larger gains in state similarity. Lower-tier models exhibit near-zero performance in zero-shot.
While transformed code promptings generally reduce Runnable@k rates (by around 10%), they significantly improve trace similarity scores (e.g., DeepSeek-V3: +19% absolute). This reflects a tradeoff: transformation enforces higher semantic fidelity to original control flow at the cost of greater LLM difficulty and context length management ("lost in the middle" issue). Ensemble approaches (union of outputs across both prompt types) yield further gains, demonstrating complementarities.
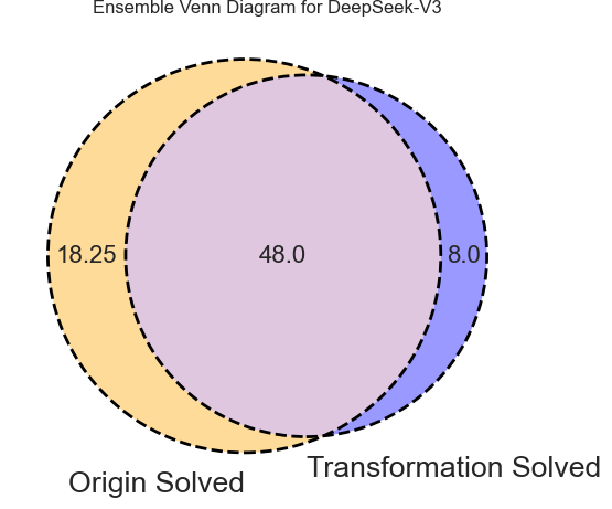
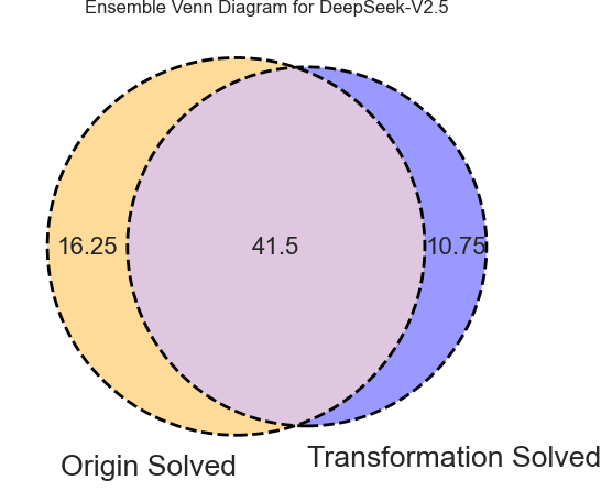
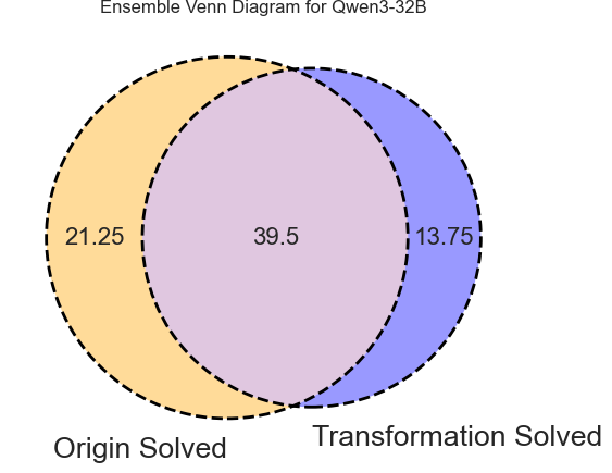
Figure 3: Venn diagrams capture the unique and overlapping success cases (Runnable@3) between original and transformed code promptings per model.
Syntactic Complexity and Modeling-Difficulty Correlation
Automatic modeling success declines monotonically with increasing source code cyclomatic complexity, maximum loop depth, and variable counts. There is no significant linkage between the algorithmic difficulty of the underlying problem and LLM modeling success; structure overwhelms logic.
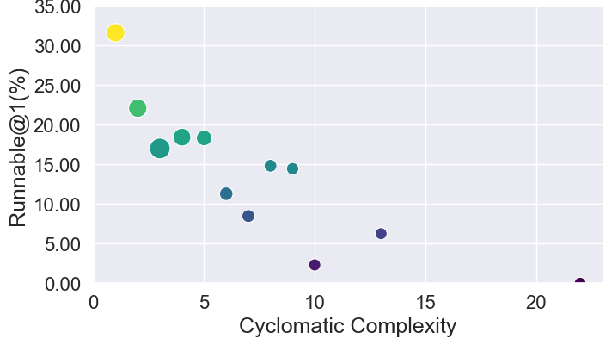
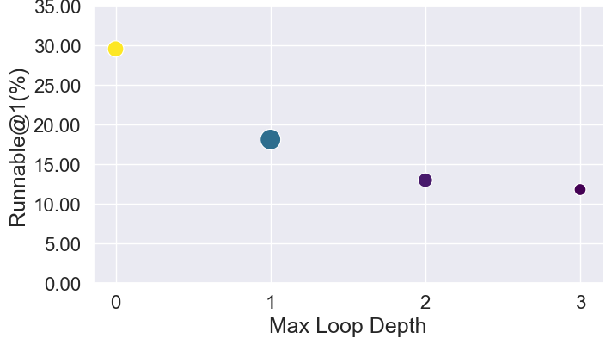
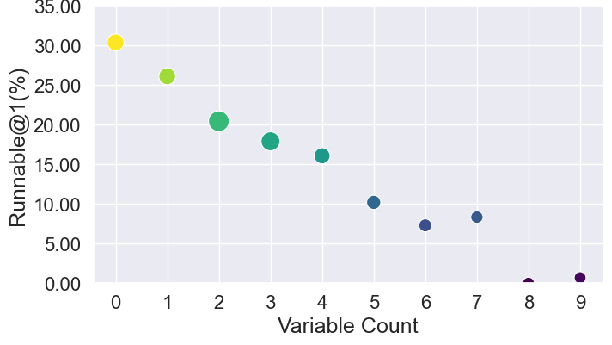
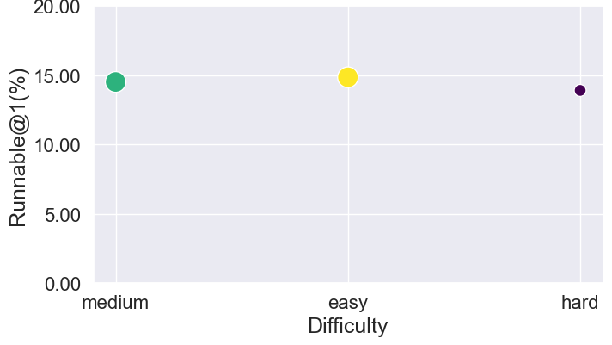
Figure 4: Correlation analysis of success rates (Runnable@1) with code complexity metrics demonstrates the dominant effect of syntax and structure.
Failure Case Taxonomy
Error analysis distinguishes between:
- Compilation errors—often due to generation of unknown or mismatched operators in TLA+ when translating Python built-ins (e.g., inappropriate use of sorting or concatenation operators).
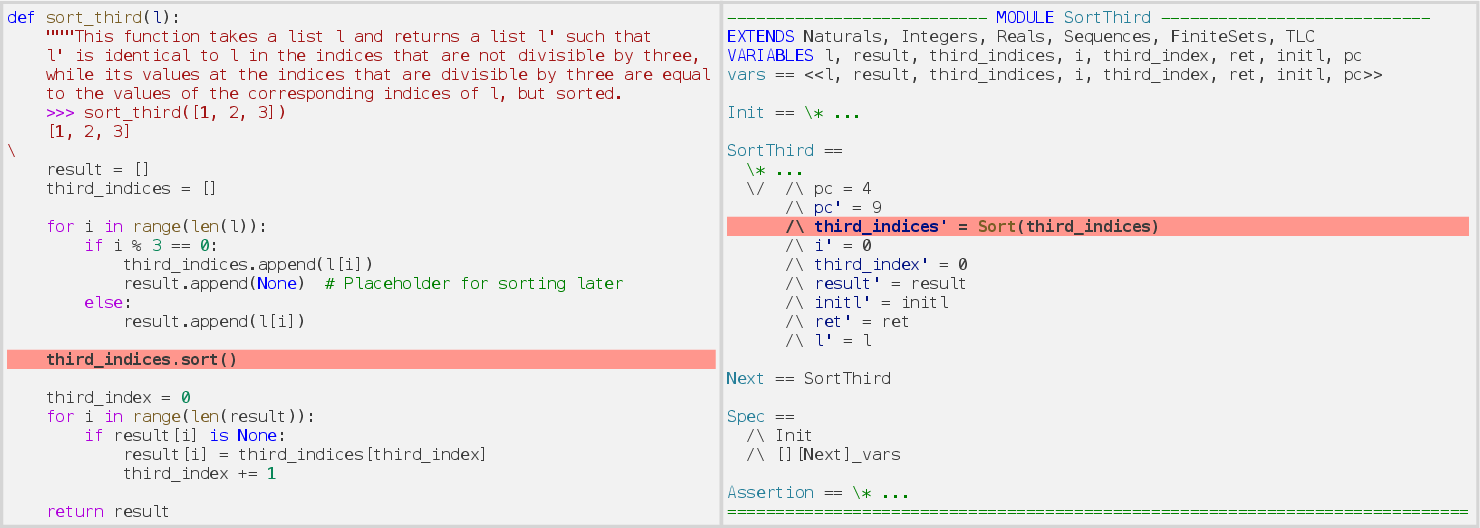
Figure 5: Unknown operator usage causes syntactic failure in TLA+ output stemming from Python constructs.
- Runtime errors—such as incorrect array indexing due to off-by-one differences or inattention to TLA+ base indexing.
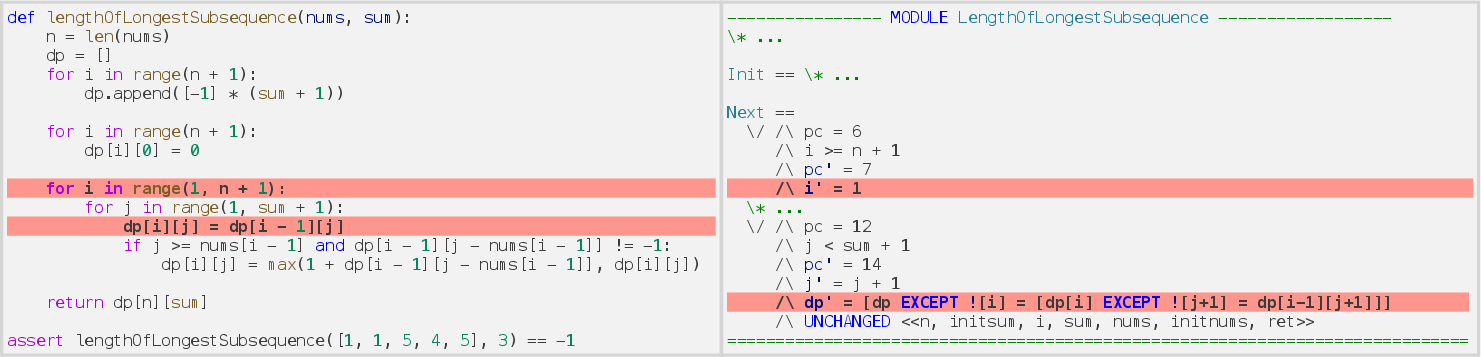
Figure 6: Runtime error stemming from misalignment in array indexing conventions between Python (0-based) and TLA+ (1-based).
- Assertion errors—frequently omission of side-effect logic (e.g., missing case normalization, omitted loop limits) due to overzealous or shallow copying between paradigms.
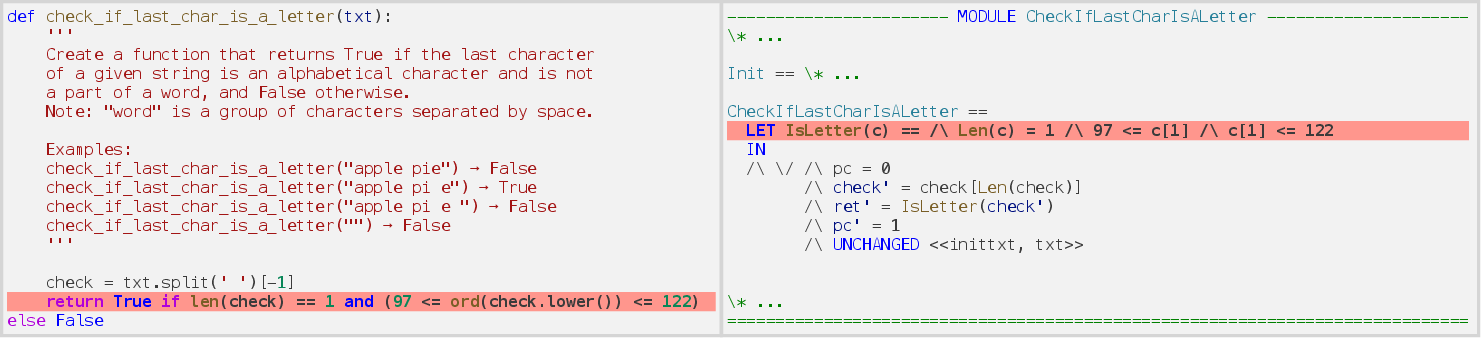
Figure 7: Failing assertion when model omits a function call (.lower()), leading to test mismatch in TLA+.
Implications and Future Directions
The results establish an authoritative baseline for the capabilities and limitations of current LLMs in formal program modeling for model-checking applications. Key takeaways include:
- Current leading LLMs can synthesize verification-ready specifications for approximately half of typical Python functions under ideal few-shot conditions.
- Prompt engineering (few-shot, code structural transformation) offers substantial but not complete mitigation of semantic and syntactic gap-induced failures.
- Model capacity and prompt conditioning are critical; low-parameter models fail unless expertly guided.
- Automated modeling success is more a function of code structural complexity than algorithmic depth.
- Error modality is dominated by language mapping mismatches and inadequate context generalization, highlighting the need for more robust representations or explicit intermediate abstractions.
Scalable, automated end-to-end formal verification pipelines will require future LLMs with enhanced context management, semantic alignment, deeper modeling of language-specific control flow semantics, and improved cross-language code reasoning abilities. Benchmarks such as Model-Bench may inform curriculum learning, representation alignment, or dataset curation strategies to close the gap.
Conclusion
Model-Bench introduces a practical, extensible framework and dataset for rigorous assessment of LLM-based program modeling for formal verification, identifying clear remaining challenges. In conjunction with the presented metrics and code transformation techniques, this work provides a foundation for advancing AI-assisted formal methods and invites further modeling innovations targeting exhaustive, machine-verifiable correctness. The gap between today’s LLMs and reliable formal modeling at scale is quantitatively established, and future developments must address both linguistic alignment and operational semantics to fully bridge this divide (2604.01851).