- The paper introduces a transformer-based method that fuses per-face raw texture embeddings with geometric features to achieve superior segmentation accuracy on non-manifold 3D meshes.
- The method employs a two-stage transformer block with local intra-cluster and cross-cluster self-attention to capture detailed structure and reduce oversmoothing.
- Experiments on extensive urban and cultural heritage datasets demonstrate significant performance gains over geometry-only baselines, especially in long-tailed categories.
Semantic Segmentation of Textured Non-manifold 3D Meshes using Transformers
Introduction
The paper "Semantic Segmentation of Textured Non-manifold 3D Meshes using Transformers" (2604.01836) presents a transformer-based deep learning framework for semantic segmentation targeting textured, non-manifold 3D meshes. This work addresses the confluence of geometric and textural information on mesh surfaces and proposes architectural modifications tailored to the challenges of raw texture processing, irregular mesh topology, and the necessity for scalable, hierarchical context aggregation. The method is evaluated on both the Semantic Urban Meshes (SUM) benchmark and a novel cultural heritage (CH) mesh dataset, delivering superior quantitative and qualitative results compared to established baselines.
Prior methods for 3D semantic segmentation typically target regular data structures—voxels [maturana2015voxnet, wu20153d], point clouds [qi2017pointnet++, qian2022pointnext], or manifold meshes [feng2019meshnet, lahav2020meshwalker]—whereas many real datasets are non-manifold and encompass rich texture information absent from these surrogates. Most existing mesh-based methods emphasize geometric cues, occasionally incorporating low-dimensional texture statistics (e.g., mean vertex colors) [heidarianbaei2025nomeformer, zi2024urbansegnet], which are insufficient for representing the spatial complexity of texture maps.
Efforts to directly coalesce per-face texture and geometric information are rare. The only comparable mesh-centric method at scale, NoMeFormer [heidarianbaei2025nomeformer], relies on cluster-based transformers but utilizes hand-crafted texture statistics, potentially oversmoothing class boundaries and failing to capture high-frequency appearance variation. The presented approach notably introduces direct transformer-based modeling over raw per-face texture pixels, facilitating robust multi-modal feature fusion at triangle resolution.
Methodology
Architecture Overview
The architecture comprises three main components:
- Feature Extraction Branch: Each mesh face is independently encoded via concatenation of geometric and transformer-derived texture embeddings.
- Two-Stage Transformer Blocks (TSTB): Hierarchical processing is realized via TSTBs, each consisting of a local intra-cluster self-attention sub-block and a global cross-cluster self-attention sub-block. K-means clustering is used to partition faces for computational efficiency.
- Classification Head: After NBl TSTBs, each face embedding is mapped to class probabilities.
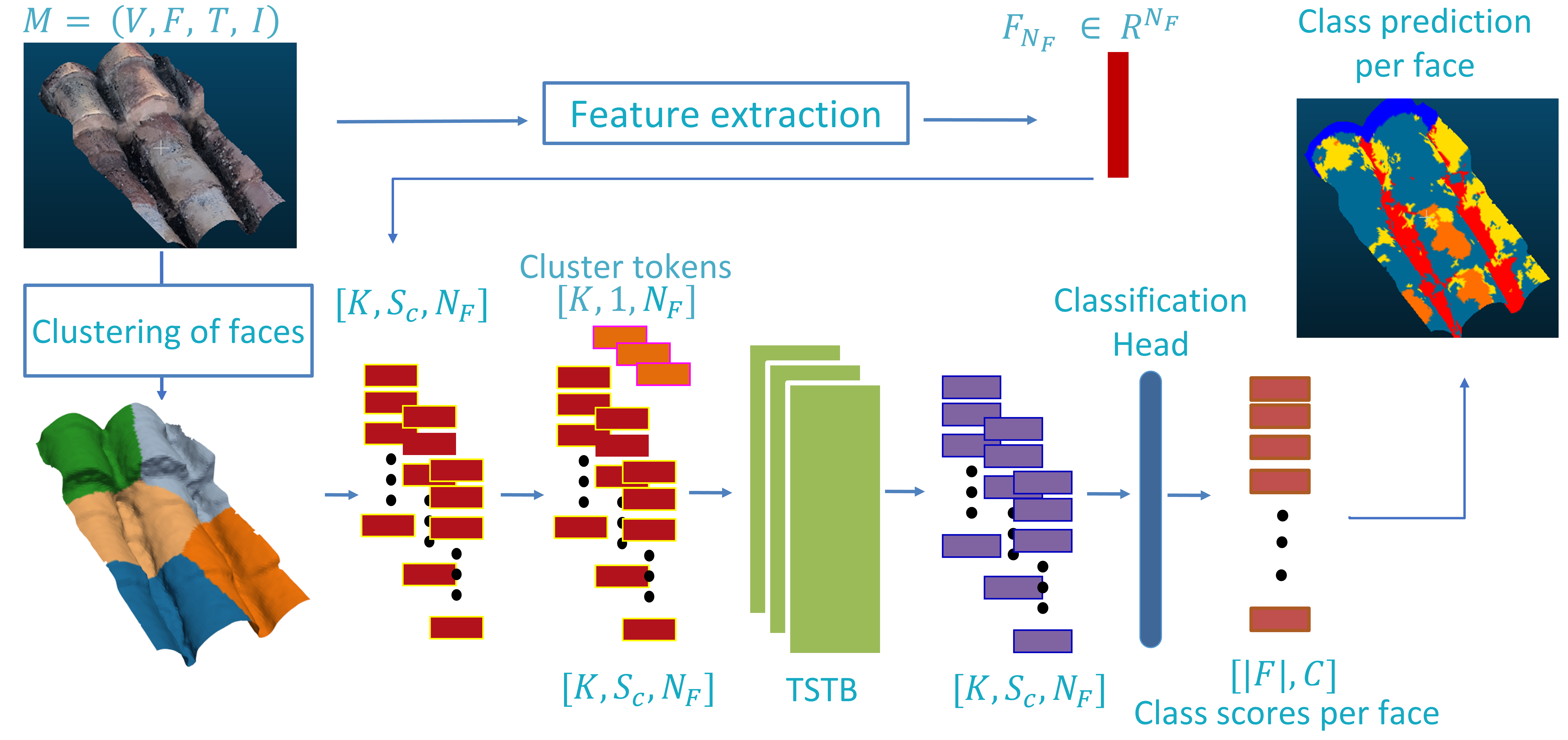
Figure 1: Overview of the network architecture, highlighting per-face feature extraction, face clustering, hierarchical transformer processing, and final class prediction.
Direct Per-Face Texture Embedding
A distinctive contribution is the texture branch, which, for each face, extracts raw pixel values from the texture map according to mesh UV mapping. A transformer encoder, operating on these per-face pixel sequences (with up to 128 pixels per face), aggregates spatial and spectral cues into a single learnable face-wise token for subsequent fusion with geometric features.
The TSTB module forms the backbone for contextual reasoning. Local self-attention operates independently within clusters, preserving local detail and fine-scale geometry-texture alignment. Modified cross-cluster self-attention is confined to cluster tokens (not all face tokens as in standard cross-attention), mitigating oversmoothing and enabling long-range context dissemination only through aggregated summaries.
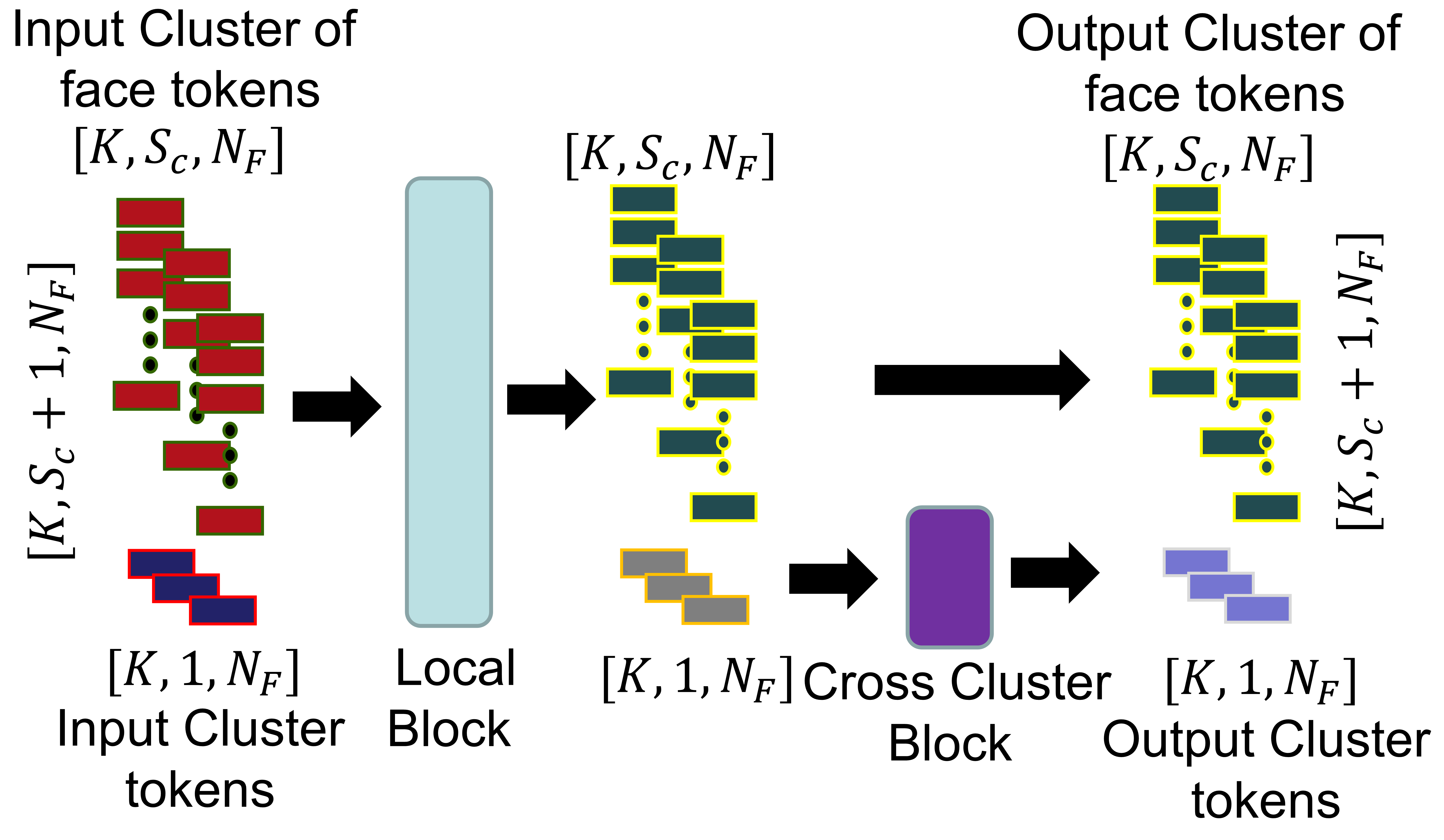
Figure 2: Architecture of a TSTB, highlighting the local intra-cluster and cross-cluster global self-attention sub-blocks and their tensorial flow.
Training Paradigm
Training minimizes categorical cross-entropy on triangle-wise labels with data augmentations (3D rotations, scaling, noise), AdamW optimization, and extensive ablations on embedding dimensionality, TSTB depth, and feature modality composition. Attention masks guarantee correct handling of variable cluster and pixel sequence sizes.
Experimental Evaluation
Datasets
- SUM: 19M faces, six semantic urban classes, high geometric and textural variability.
- CH: 5M faces, annotated roof damage types, highly imbalanced classes, challenging appearance variability.
Main Results
The proposed method achieves:
- SUM: 81.9% mF1, 94.3% OA.
- CH: 49.7% mF1, 72.8% OA.
These results denote substantial outperformance versus DiffusionNet (geometry-only) and NoMeFormer (statistical texture only), with especially strong gains in challenging long-tailed categories.
Ablation studies indicate:
- Increasing embedding size sharply boosts performance up to hardware constraints.
- Fusing geometry and transformer-extracted texture embeddings is critical; standalone usage yields weaker results.
- Replacement of cross-attention with self-attention (between cluster tokens only) reduces oversmoothing, providing notable F1 improvements, especially under severe class imbalance (CH).
Area-weighted evaluation confirms the method's leading status over KPConv (point-centric) and RF-MRF (mesh-centric), establishing the benefit of direct mesh-face textural modeling.
Qualitative Findings
Predictions from the proposed method are visually sharper and more consistent with annotation, better capturing fine structures and localized texture-induced class boundaries than baseline architectures. NoMeFormer frequently exhibits blurry, over-smoothed predictions.
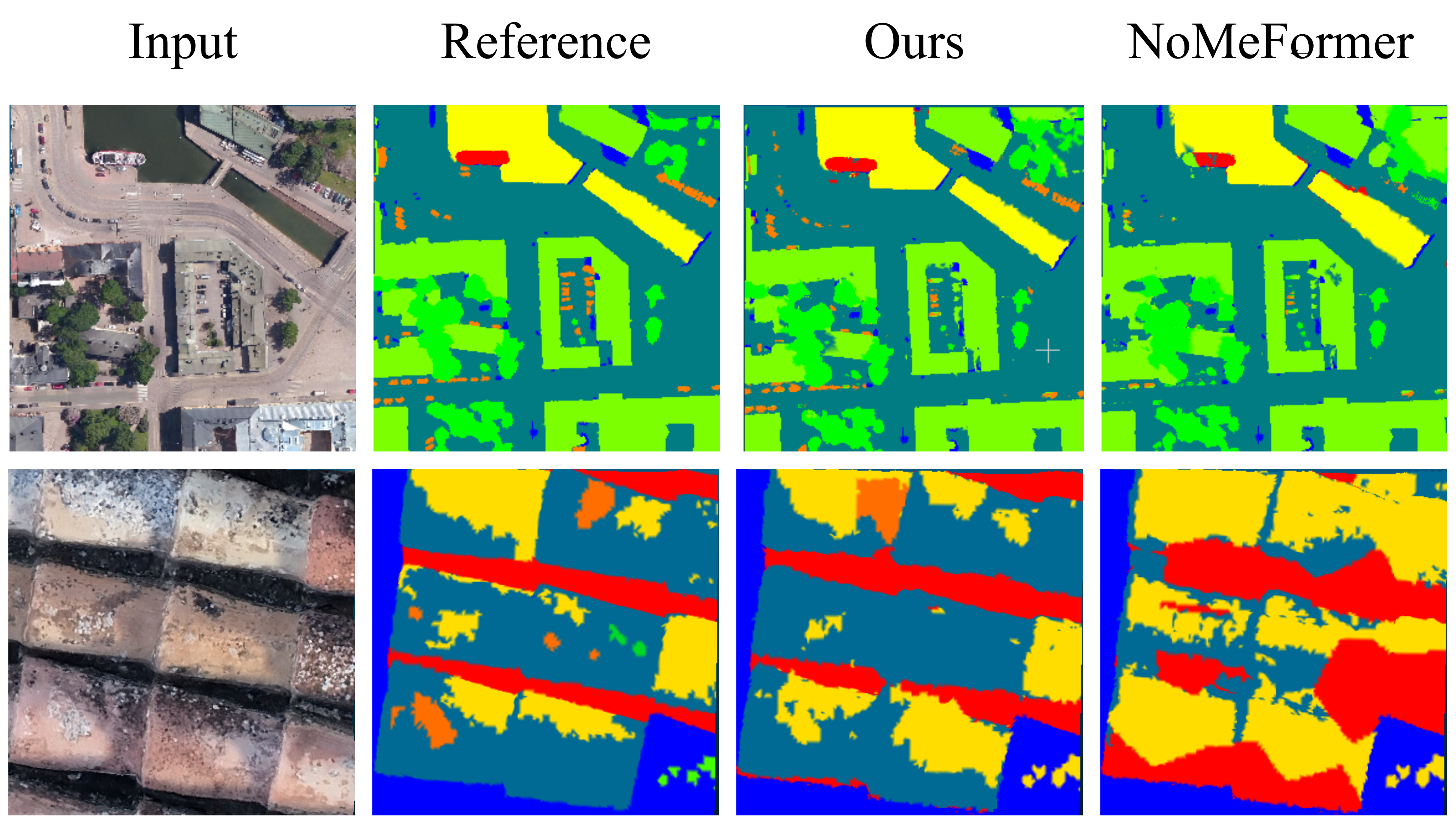
Figure 3: Qualitative segmentation results: Input, reference annotation, proposed method, NoMeFormer baseline. Top: SUM example; Bottom: CH example.
Theoretical and Practical Implications
Theoretical Advances
This architecture demonstrates the practical feasibility and clear benefits of integrating transformer-based per-face texture aggregation with geometric encoding, facilitating mesh-based semantic segmentation without reliance on manifoldness or lossy texture statistics. Introducing a two-level transformer hierarchy with cluster-token focused global reasoning provides a robust alternative to full cross-attention, reducing computational and overfitting liabilities.
Practical Impact
Applications benefiting from fast, accurate, and scalable 3D semantic segmentation—urban modeling, cultural heritage preservation, defect detection, robotics—can leverage this approach for high-resolution, multi-modal mesh datasets previously too irregular or memory-intensive for existing architectures. The method's ability to generalize to both large-scale and fine-grained domains widens its application prospects.
Future Directions
There remains an opportunity to:
- Introduce learnable or explicit positional encodings within per-face texture transformers.
- Optimize attention and clustering schemes for further scalability.
- Address severe class imbalance via targeted loss re-weighting or semi-supervised pre-training.
- Integrate multimodal extensions (multispectral/thermal) and more adaptive mesh partitioning.
- Advance toward end-to-end clustering and incorporate self-supervised pre-training for geometry-texture representations.
Conclusion
The presented method establishes a new state-of-the-art in semantic segmentation of non-manifold textured 3D meshes by fusing transformer-based texture and geometry encoding, hierarchical context propagation, and robust ablation validation. It outperforms all relevant baselines in both quantitative and qualitative aspects, offering new directions for mesh-centric learning in real-world, multimodal, and irregular 3D domains.