MiCA Learns More Knowledge Than LoRA and Full Fine-Tuning
Abstract: Minor Component Adaptation (MiCA) is a novel parameter-efficient fine-tuning method for LLMs that focuses on adapting underutilized subspaces of model representations. Unlike conventional methods such as Low-Rank Adaptation (LoRA), which target dominant subspaces, MiCA leverages Singular Value Decomposition to identify subspaces related to minor singular vectors associated with the least significant singular values and constrains the update of parameters during fine-tuning to those directions. This strategy leads to up to 5.9x improvement in knowledge acquisition under optimized training hyperparameters and a minimal parameter footprint of 6-60% compared to LoRA. These results suggest that constraining adaptation to minor singular directions provides a more efficient and stable mechanism for integrating new knowledge into pre-trained LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “MiCA Learns More Knowledge Than LoRA and Full Fine-Tuning”
Overview: What is this paper about?
This paper introduces MiCA (Minor Component Adaptation), a new way to fine‑tune LLMs so they learn new facts better while changing fewer parts of the model. MiCA focuses on the model’s “quiet” or underused directions and updates only those, instead of changing the “loud” or already busy directions. The authors show that MiCA often learns new information better than popular methods like LoRA and even full fine‑tuning, while using fewer extra parameters and keeping old skills intact.
Objectives: What questions are the authors asking?
The paper explores three simple questions:
- Which parts of a big LLM should we change when we want it to learn something new?
- If we only change the model’s “underused directions,” can the model absorb new knowledge better and forget less?
- Does this new approach (MiCA) beat LoRA and full fine‑tuning on real tests?
Methods: How does MiCA work, in everyday terms?
Think of a model as a giant control panel with many knobs that shape how it thinks. Some knobs are used a lot (they’re “loud” and already handle many skills). Other knobs barely do anything (they’re “quiet”). Most fine‑tuning methods turn some new knobs to change the model. But they don’t carefully choose which directions to change, so they might interfere with the model’s existing skills.
MiCA uses a math tool called Singular Value Decomposition (SVD) to find those “quiet directions.” Here’s a simple analogy:
- Imagine music equalizer sliders. The “loud” sliders are boosting the main parts of the sound you already hear clearly. The “quiet” sliders barely affect the sound.
- MiCA chooses a small number of these “quiet sliders” and tweaks only them. This way, it adds new tunes (new knowledge) without messing up the main melody (the model’s old abilities).
What MiCA changes:
- It adds two small matrices (think of them as tiny layers) on top of certain parts of the model (mainly in attention layers).
- One of these is set to point exactly along those “quiet directions” found by SVD and is kept frozen (unchanged).
- The other one learns how much to push along each chosen “quiet direction.”
- The original model weights stay frozen too.
Training setup in practice:
- The team trained models on new texts, like recent OpenAI blog posts and a German history book that weren’t part of the models’ original training.
- After training the base model on this new knowledge, they add back “instruction‑following” skills by combining it with a previously instruction‑tuned version. This lets the model follow instructions again without retraining that whole skill from scratch.
Why this helps:
- By updating only underused directions, MiCA avoids fighting with the model’s core abilities and reduces the chance of forgetting.
Results: What did they find, and why does it matter?
The authors tested MiCA against LoRA and full fine‑tuning on several tasks. Here are the key takeaways:
- New knowledge from recent blog posts (BLOGS dataset):
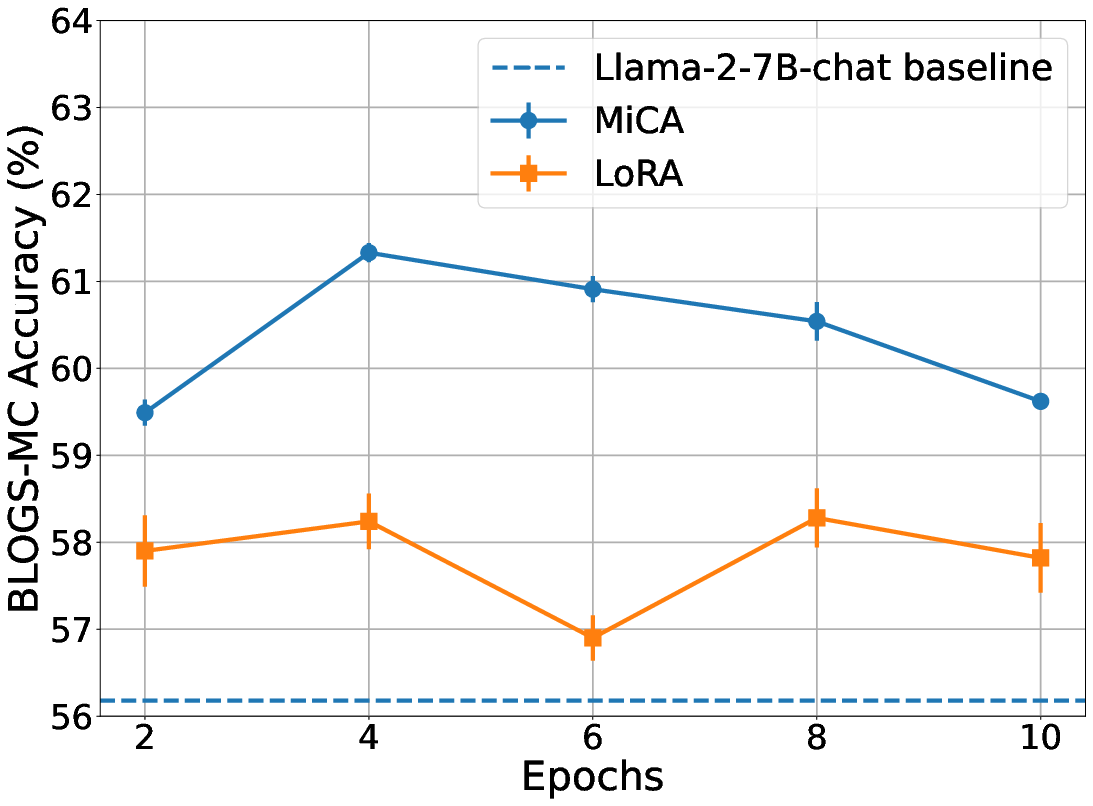
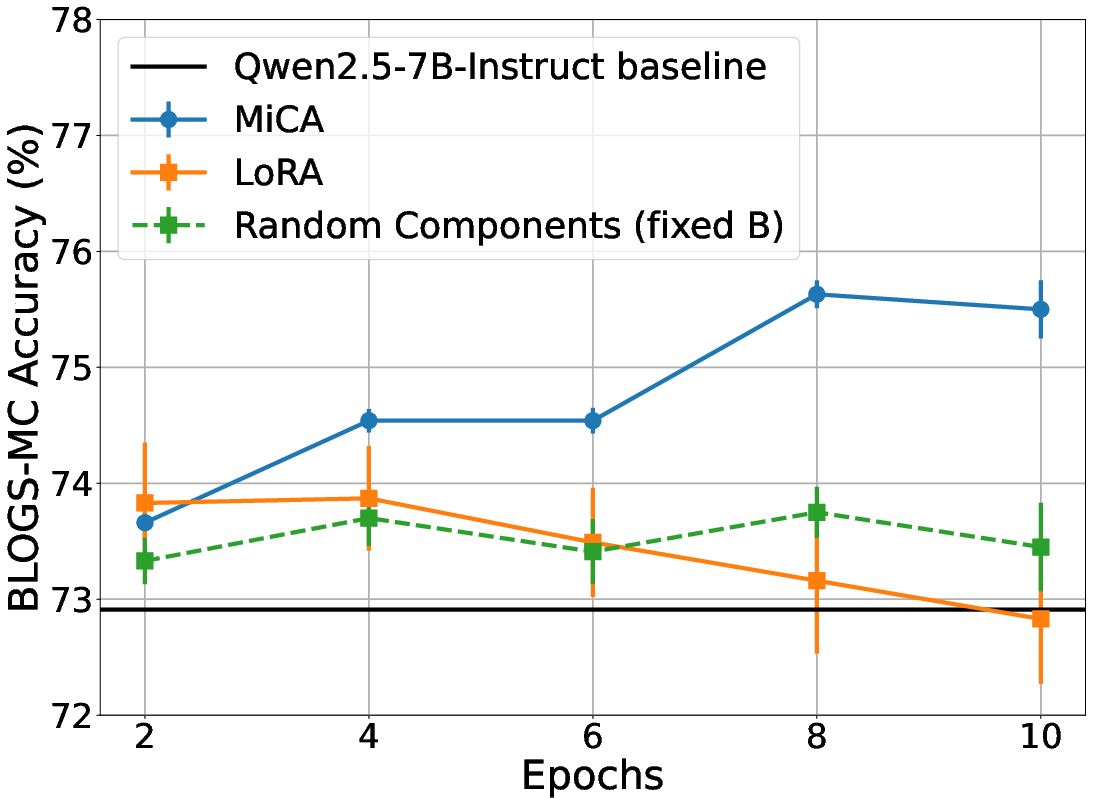
- Models fine‑tuned with MiCA answered more questions correctly about the new blog content than with LoRA or the original models.
- On Llama‑2‑7B, MiCA scored about 61.3% vs. LoRA’s 58.3% on the blog multiple‑choice test.
- On Qwen‑2.5‑7B, MiCA scored about 75.6% vs. LoRA’s 73.9%.
- MiCA used far fewer trainable parameters than LoRA (about 6% of LoRA’s count in one setup, and around 60% in another), meaning it’s more efficient.
- New knowledge from a long German history book:
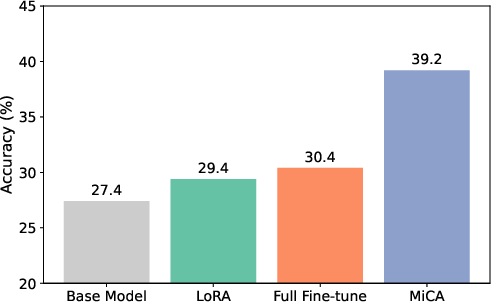
- MiCA reached about 39.2% accuracy on book‑based questions, beating LoRA (~29.4%) and even full fine‑tuning (~30.4%).
- The model kept its general abilities (measured by a benchmark called HellaSwag), suggesting little “catastrophic forgetting,” while full fine‑tuning showed more forgetting.
- Ablation study (testing the “why” behind MiCA):
- The team compared changing “major” (loud), “minor” (quiet), and random directions.
- Adapting minor directions (MiCA) worked best, beating both major and random choices.
- This supports the main idea: underused directions are a better place to add new knowledge.
Why this matters:
- MiCA learns new facts more effectively, keeps old skills, and uses fewer extra parameters than LoRA and full fine‑tuning. That’s a big win for practical, low‑compute updates to large models.
Implications: What could this change in the future?
- Better, safer updates: MiCA shows a promising way to add new information without wrecking what the model already knows.
- Cheaper and faster: Because MiCA uses fewer trainable parameters, it’s helpful for limited hardware, on‑device updates, or situations like federated learning where communication costs matter.
- Next steps: The authors note that MiCA focuses on knowledge injection more than instruction‑following. Future work could apply the same “minor directions” idea to the changes learned during instruction tuning, or combine MiCA with reinforcement learning to further reduce forgetting.
In short, MiCA’s big idea—teach the model in its underused directions—helps it learn more with less, and forget less along the way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper.
- Scaling behavior is untested beyond 7B models; effects on larger LLMs (13B/34B/70B+) and across architectures (e.g., Mistral, Llama-3, GPT-style) are unknown.
- Computational feasibility and cost of computing SVDs for very large layers are not characterized; need approximate/truncated SVD strategies and their impact on performance.
- Only left singular vectors (U) of W are used for B; effects of choosing right singular vectors (V), both U and V, or alternative constructions for rectangular matrices remain unexplored.
- Adapter injection points are limited to query/value projections; impact of MiCA in key/output projections, MLPs, embeddings, and layer norms is unstudied.
- Rank selection is manual and uniform; no adaptive, per-layer rank selection based on spectral decay or task signals is proposed or evaluated.
- No layer-wise analysis of singular spectra to guide where minor directions are informative vs noisy; a criterion for layer selection is missing.
- Fairness of comparisons is unclear: MiCA and LoRA were tuned with different learning rates/epochs/ranks; need matched compute budgets, matched parameter budgets, and fixed training schedules for rigorous comparisons.
- Baselines are limited (LoRA, full FT); results do not include other PEFT methods (e.g., IA³, AdaLoRA, LoRA-Drop, PiSSA, Prefix/Prompt tuning, QLoRA), limiting conclusions about relative effectiveness.
- Compatibility with quantization (e.g., 4-bit QLoRA) is untested; the quality of SVD on quantized weights and end-to-end performance under quantized inference remain open.
- The “base FT + instruction delta” composition assumption (near-linear locality) is not validated; alternative compositions (fine-tuning instruct checkpoints, different merging strategies) and their interactions with MiCA vs LoRA need study.
- Evidence for reduced catastrophic forgetting is limited: retention is assessed mainly via HellaSwag (in English) after German-domain training; a comprehensive, multilingual retention benchmark is needed.
- Knowledge acquisition is measured largely with synthetic multiple-choice questions generated from training content; generalization to held-out, open-ended, and long-form questions is not evaluated.
- Possible contamination and construction bias in synthetic evaluation (LLM-generated questions/answers) are not examined; a human-verified or out-of-sample test set would strengthen claims.
- Statistical significance is not established: small numbers of runs for some settings (e.g., HISTORY: n=2 for LoRA, n=4 for MiCA) and no formal significance tests.
- Training stability claims (e.g., “more stable mechanism”) lack direct metrics; need analyses of loss curvature, gradient alignment, representation drift, and forget/remember curves over time.
- Theoretical underpinning is mostly intuitive/analogical (MCA); no formal analysis of why minor components should be more “plastic,” nor of how gradients align with singular subspaces during fine-tuning.
- Sensitivity analyses are limited; robustness to learning rate, optimizer choice, regularization, rank r, and spectral thresholding is not systematically explored.
- Expressivity limits of fixing B (frozen U[:,-r:]) are unquantified; whether lightly training B with a spectral regularizer could improve results is untested.
- The ablation (minor vs major vs random) is shown for a single dataset/model; replication across tasks/models/ranks and across more diverse domains is needed.
- Interaction of MiCA with instruction tuning as a target task is acknowledged as a limitation; a concrete method (e.g., SVD on instruction deltas) and empirical evaluation are open.
- Sequential/continual learning across multiple domains (multi-step knowledge injection) and comparative forgetting vs LoRA over sequences remain unaddressed.
- Impact on reasoning, coding, and complex synthesis tasks is unclear; evaluations focus on factual MCQ and two general benchmarks.
- Runtime and deployment implications are not measured: inference latency/throughput with adapters, memory overhead of storing multiple MiCA adapters, and merging costs are unknown.
- Parameter and optimizer-state savings are claimed but not profiled end-to-end (GPU memory, activation/optimizer footprint, wall-clock efficiency).
- Layer- and head-level heterogeneity (e.g., which heads/layers benefit most from minor-component adaptation) is not analyzed.
- Potential interaction with RL-based alignment is proposed but untested; whether spectral constraints and KL-regularized RL are synergistic is an open question.
- Robustness and safety characteristics (calibration, toxicity, bias, adversarial vulnerability) are not evaluated post-adaptation.
- Effectiveness under domain shift and out-of-domain generalization (beyond the trained topic/language) is not measured.
- Data-efficiency across scales (few-shot vs medium vs large continued pretraining) is not systematically studied; only two regimes are shown.
- Practical reproducibility is incomplete: full code, seeds, and exhaustive hyperparameter search procedure/details are not provided within the paper.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage MiCA’s ability to adapt LLMs by updating only a fixed minor-singular subspace (training A while freezing B set to the bottom-r singular vectors), resulting in higher knowledge acquisition with fewer trainable parameters than LoRA and reduced risk of catastrophic forgetting.
- Enterprise domain specialization with minimal compute
- Sectors: software, customer support, legal, finance, healthcare, education
- What to do now: Compute per-layer SVD once on an open/base model; set B = bottom-r U vectors; train only A on private corpora (manuals, SOPs, policies, case law, regulatory bulletins); optionally compose with instruction deltas as described in the paper.
- Tools/workflows: Hugging Face PEFT integration (custom MiCA adapter), “SVD precompute” job, rank selection utility, adapter export/deploy pipeline.
- Assumptions/dependencies: Access to model weights (open/checkpointed models); one-time SVD cost is feasible; instruction-delta composition remains locally linear for the chosen base/instruct pair.
- Multi-tenant adapter serving (“MiCA adapter store”)
- Sectors: SaaS, enterprise platforms
- What to do now: Maintain a shared base model and swap small tenant-specific A matrices at inference; keep B fixed per model version to standardize deployment.
- Tools/workflows: Adapter registry (per-tenant A matrices), inference-time adapter hot-swapping, CI that validates no drift on global benchmarks.
- Assumptions/dependencies: Consistent base model across tenants; guardrails/acceptance tests for non-regression.
- On-device personalization with privacy preservation
- Sectors: mobile, edge/IoT, consumer productivity
- What to do now: Ship B with the app (derived from the base model), fine-tune A locally on user data (emails, notes, calendars) to personalize behavior without uploading data.
- Tools/workflows: On-device MiCA training task, small-footprint persistence of A, opt-in personal adapter management.
- Assumptions/dependencies: Enough local compute to train small A; storage limits permit A caching; open or licensed base model variants are available for device use.
- Federated learning with reduced communication
- Sectors: healthcare, finance, IoT, telecom
- What to do now: Server distributes fixed B (per-layer minor U vectors); clients train only A on local data; server aggregates A (e.g., FedAvg) for a global adapter or per-cluster adapters.
- Tools/workflows: FedAvg/FedOpt integration for A-only updates, privacy accounting, secure aggregation.
- Assumptions/dependencies: Consistent B across clients; averaging A is appropriate for the objective; regulatory/privacy controls in place.
- Continual knowledge refresh with low forgetting
- Sectors: news/media, legal, finance, enterprise knowledge bases
- What to do now: Schedule periodic MiCA updates as new content arrives (e.g., regulations, filings, policy updates); re-test general capabilities post-update.
- Tools/workflows: Rolling MiCA training pipelines, automated evaluation on domain tests (BLOGS-like MCQs) and general benchmarks, rollback via adapter versioning.
- Assumptions/dependencies: New knowledge is well-curated; long-term stability validated on representative benchmarks.
- Compliance- and safety-critical deployments with constrained drift
- Sectors: healthcare, aerospace, defense, critical infrastructure
- What to do now: Use MiCA to localize representational changes during domain adaptation; run stringent regression tests on safety suites (e.g., TruthfulQA, HellaSwag or domain-specific tests).
- Tools/workflows: “Spectral change budget” governance checks, adapter provenance logging, approval gates for deploying new A.
- Assumptions/dependencies: Safety/performance testing is required prior to deployment; minor-subspace updates align with safety constraints.
- Academic replication and benchmarking
- Sectors: academia, research labs
- What to do now: Package and share small A matrices to reproduce domain-specialization results; compare major vs. minor subspace adaptation in new tasks.
- Tools/workflows: Public adapter repos with task metadata, scripts for SVD + MiCA adapter training and evaluation.
- Assumptions/dependencies: Open weights and data licenses; standardized evaluation suites.
- Energy- and cost-efficient fine-tuning at scale
- Sectors: cloud providers, MLOps
- What to do now: Replace many LoRA trials with MiCA for knowledge injection tasks to cut GPU hours and optimizer state; prioritize MiCA for resource-limited pilots.
- Tools/workflows: Cost-per-point-of-accuracy dashboards, job templates for MiCA vs LoRA A/B.
- Assumptions/dependencies: Gains observed in 7B models generalize to target model sizes; tasks are knowledge-centric rather than instruction-heavy.
- Rapid A/B experimentation for domain knowledge
- Sectors: product R&D, applied research
- What to do now: Sweep ranks r and learning rates with small A-only updates; quickly assess domain uptake via MCQ-style evaluations.
- Tools/workflows: Lightweight hyperparameter sweeps, automatic rank tuning heuristics (e.g., spectrum tail mass).
- Assumptions/dependencies: Stable evaluation datasets; automated SVD caching.
- Open collaboration via “MiCA packs”
- Sectors: open-source community, education
- What to do now: Release domain adapters (A) for public models with clear data provenance (e.g., history books, specialized glossaries); enable community stacking/composition with instruction deltas.
- Tools/workflows: Adapter catalogs, metadata cards (data source, rank, eval scores).
- Assumptions/dependencies: Respect data/IP constraints; maintain alignment with base/instruct checkpoints.
Long-Term Applications
These opportunities require further research, scaling studies, or tooling maturity before broad deployment.
- Scaling MiCA to very large models with approximate SVD
- Sectors: cloud, hyperscalers, foundation model providers
- What could emerge: Randomized/streaming SVD services (“SVD-as-a-Service”), layer-wise spectrum caching, per-layer auto-rank selection.
- Assumptions/dependencies: Efficient, accurate approximate SVD for >70B models; robust numerical stability; standardized APIs.
- Cross-modal MiCA for vision, speech, and robotics
- Sectors: robotics, autonomous systems, multimodal AI
- What could emerge: Minor-component adapters for ViTs, ASR, and sensor fusion models to inject environment- or device-specific knowledge with minimal drift.
- Assumptions/dependencies: Empirical validation across modalities; identification of the most impactful injection points beyond Q/V projections.
- Spectral-constrained RL alignment pipelines
- Sectors: safety, alignment, enterprise AI
- What could emerge: Two-stage workflow—(1) MiCA knowledge injection, (2) KL-regularized RL (e.g., PPO)—to target behavior while containing representation drift.
- Assumptions/dependencies: Demonstrated synergy of spectral constraints and RL; tooling to enforce spectral constraints during policy updates.
- Dynamic adapter routing and composition
- Sectors: search, assistants, enterprise knowledge platforms
- What could emerge: Router that selects per-query domain A matrices (or blends them) at inference, akin to mixture-of-experts but with low overhead.
- Assumptions/dependencies: Efficient routing policies; adapter interference analysis; latency-aware composition strategies.
- Quantization- and sparsity-aware MiCA (e.g., QLoRA+MiCA)
- Sectors: edge computing, cost-optimized serving
- What could emerge: Training A over quantized bases; sparsity in A to further compress; end-to-end recipes for “tiny adapters on tiny models.”
- Assumptions/dependencies: Stable training under quantization; evaluation of combined effects on knowledge acquisition.
- Lifelong/streaming learning with adapter versioning
- Sectors: finance, legal, scientific knowledge bases
- What could emerge: Time-stamped adapter chains to reflect evolving corpora; policies to merge/swap A based on recency and performance.
- Assumptions/dependencies: Methods to manage and prune historical adapters; data drift detection; catastrophic forgetting safeguards.
- Security, auditability, and interpretability of spectral updates
- Sectors: policy, regulated industries
- What could emerge: “Adapter attestation” and audit trails; spectral diff tools to visualize and verify the locality of changes; compliance reporting.
- Assumptions/dependencies: Agreement on audit standards; tools to map spectral updates to functional behavior.
- AutoMiCA: automated rank and subspace selection
- Sectors: AutoML platforms, MLOps
- What could emerge: Meta-learned policies that choose rank per layer based on spectral tail mass, task gradients, or validation signals.
- Assumptions/dependencies: Sufficient telemetry across tasks; generalizable heuristics.
- Cross-lingual and low-resource domain transfer
- Sectors: global enterprises, public sector, NGOs
- What could emerge: Use MiCA to integrate new language/domain knowledge with minimized cross-language interference; adapters for minority-language corpora.
- Assumptions/dependencies: Empirical studies on multilingual LLMs; careful evaluation to avoid degrading other languages.
- Policy and sustainability programs for compute-efficient adaptation
- Sectors: public sector, standards bodies
- What could emerge: Guidelines promoting small-footprint adapters for government and nonprofit deployments; carbon reporting that credits parameter-efficient updates.
- Assumptions/dependencies: Measurement frameworks for energy and emissions; adoption by procurement and oversight bodies.
- Personal knowledge management across devices
- Sectors: consumer OS, productivity
- What could emerge: Encrypted, portable A matrices as the “personalization layer” synced across devices; per-app adapters with privacy controls.
- Assumptions/dependencies: Secure key management; user-consent and revocation mechanisms; robust on-device training UX.
- Knowledge marketplaces and licensing for “MiCA knowledge packs”
- Sectors: publishing, data providers, B2B AI
- What could emerge: Domain experts sell or license small adapters (A) encoding vetted knowledge (e.g., medical guidelines updates); standardized contracts and updates.
- Assumptions/dependencies: Legal/IP clarity on derivative weights; platform interoperability; QA standards.
Notes on Feasibility and Scope
- Proven scope today: Knowledge injection for 7B-scale open models, improved accuracy over LoRA in controlled MCQ evaluations, reduced parameter footprint (6–60% of LoRA), and evidence of reduced forgetting.
- Open questions: Scaling to larger models/layers (SVD cost), tasks that demand structural instruction following (MiCA may need instruction-delta composition or alternative spectral bases), and generalization across modalities and languages.
- Practical dependency: Access to model weights (closed models may not allow SVD), robust SVD pipelines or approximations for very large layers, and validation suites to monitor interference and safety.
Glossary
- Additive composition (of model weights): Combining model parameters by summing a fine-tuned base model with an instruction delta to restore instruction-following behavior. Example: "we additively compose the resulting model weights with the delta between the instruction-tuned model and its corresponding base model:"
- Adapter: A lightweight, trainable module (often low-rank) inserted into a model’s layers to enable efficient task adaptation without updating all weights. Example: "adapters were applied to the query and value projection matrices"
- Adapter rank: The dimensionality r of the low-rank adapter subspace that controls capacity and parameter count. Example: "The search space included adapter rank , learning rate, and number of training epochs."
- Catastrophic forgetting: The degradation of previously learned capabilities when a model is fine-tuned on new tasks or domains. Example: "reduce catastrophic forgetting."
- Continued Pre-Training (CPT): Further pre-training a model on domain-specific unlabeled text after initial pre-training to inject new knowledge. Example: "This appendix documents the implementation details for Continued Pre-Training (CPT) with parameter-efficient adapters (LoRA / MiCA-style variants)"
- Dominant subspaces: High-energy/high-variance representation directions typically captured by top singular vectors. Example: "Unlike conventional methods such as Low-Rank Adaptation (LoRA), which target dominant subspaces"
- Federated learning: A distributed training setting where models are updated across multiple devices or sites with limited communication and privacy constraints. Example: "on-device adaptation and federated learning settings"
- Instruction delta: The parameter difference between an instruction-tuned model and its base model, used to restore instruction-following behavior. Example: "denotes the instruction delta derived from the original instruction tuning."
- Instruction tuning: Fine-tuning a LLM to follow natural language instructions, often using human feedback or curated instruction datasets. Example: "instruction-tuning phases commonly used in LLMs"
- KL regularization: Adding a Kullback–Leibler divergence penalty during reinforcement learning to keep the adapted model close to a reference policy. Example: "Reinforcement learning with explicit KL regularization has been observed to produce more behaviorally targeted updates"
- Low-rank update: Modifying a weight matrix using a rank-r correction to reduce trainable parameters and constrain changes. Example: "the weight matrix is modified via a low-rank update:"
- Low-Rank Adaptation (LoRA): A parameter-efficient method that inserts trainable low-rank matrices into existing layers while keeping original weights frozen. Example: "Low-Rank Adaptation (LoRA), which introduces trainable low-rank matrices into existing layers of the model"
- Major- adaptation: Constraining updates to the top-r singular directions (dominant subspace). Example: "Major- adaptation: projection onto the top- singular vectors"
- Minor Component Adaptation (MiCA): A PeFT method that constrains updates to minor singular directions of pre-trained weights for stable, efficient knowledge integration. Example: "Minor Component Adaptation (MiCA) is a novel parameter-efficient fine-tuning method for LLMs"
- Minor Component Analysis (MCA): A technique focusing on eigenvectors associated with the smallest eigenvalues to capture subtle, less-expressed structure. Example: "MiCA bears similarity to Minor Component Analysis (MCA)"
- Minor singular directions: Directions in parameter space associated with small singular values, hypothesized to be more plastic for domain adaptation. Example: "constraining adaptation to minor singular directions provides a more efficient and stable mechanism"
- Orthonormal subspace: A subspace spanned by orthonormal vectors, often used to constrain updates to a fixed, well-posed set of directions. Example: "fixed low-dimensional orthonormal subspace"
- Orthogonal matrix: A square matrix whose columns (and rows) are orthonormal, preserving inner products and norms. Example: " is an orthogonal matrix whose columns are the left singular vectors,"
- Parameter-efficient fine-tuning (PeFT): Strategies that adapt models by training a small subset of parameters while keeping most weights fixed. Example: "Parameter-efficient fine-tuning (PeFT) methods have emerged as a viable alternative"
- Parameter footprint: The proportion or count of parameters that are trained or added during adaptation, reflecting resource usage. Example: "a minimal parameter footprint of 6-60\% compared to LoRA."
- Principal Component Analysis (PCA): A method extracting dominant eigenvectors corresponding to the largest eigenvalues to capture maximal variance. Example: "a lesser-known counterpart to Principal Component Analysis (PCA)."
- Projection matrices (query/value): Linear layers in transformer attention that project hidden states into query and value spaces. Example: "adapters were applied to the query and value projection matrices"
- Singular value decomposition (SVD): A matrix factorization W = UΣVᵀ into orthogonal singular vectors and nonnegative singular values. Example: "MiCA leverages Singular Value Decomposition to identify subspaces"
- Singular values: Nonnegative scalars in Σ indicating the strength of corresponding singular directions. Example: " is a diagonal matrix containing the singular values ."
- Singular vectors: The orthogonal directions (columns of U and V in SVD) defining principal axes of a matrix’s action. Example: "minor singular vectors associated with the least significant singular values"
- Spectral structure: The distribution and organization of a matrix’s singular values and vectors (or eigenvalues/vectors), revealing dominant versus minor directions. Example: "does not explicitly account for the spectral structure of the pre-trained weight matrix."
- Spectrally grounded mechanism: An adaptation approach explicitly guided by spectral information (e.g., SVD) to select update directions. Example: "introducing a spectrally grounded mechanism for parameter-efficient specialization."
Collections
Sign up for free to add this paper to one or more collections.