- The paper presents a dynamic multi-stage MoE fusion mechanism that adapts to sample heterogeneity in multi-modal brain network analysis.
- It employs modality-specific pretraining and gating to integrate structural and functional connectivity for robust representation learning.
- Empirical evaluations on gender classification and MDD diagnosis demonstrate improved accuracy and robustness across metrics.
Multi-Stage Dynamic Fusion for Sample-Adaptive Multi-Modal Brain Network Analysis
Introduction
The paper "M3D-BFS: a Multi-stage Dynamic Fusion Strategy for Sample-Adaptive Multi-Modal Brain Network Analysis" (2604.01667) addresses the limitations of static fusion in existing multi-modal brain network methods, which process all input samples with identical computational pathways, thereby disregarding sample heterogeneity. The study introduces M3D-BFS, a mixture-of-experts (MoE) based multi-stage framework designed to achieve sample-adaptive fusion by dynamically selecting modality-specific and fused representations at the node level for each sample. The approach is evaluated on gender classification and major depressive disorder (MDD) diagnosis tasks, yielding substantive improvements over both static and dynamic baselines.
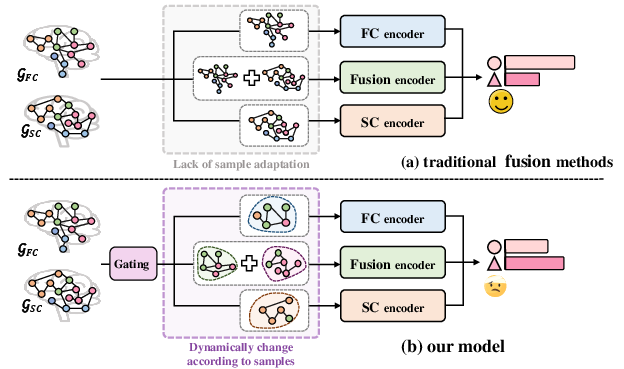
Figure 1: The M3D-BFS pipeline adaptively alters expert selection according to each input sample’s characteristics.
Motivation and Problem Setting
Multi-modal fusion is essential for comprehensive brain network analysis, leveraging complementary information provided by structural connectivity (SC, typically derived from dMRI) and functional connectivity (FC, typically from fMRI). However, the inherent variability in regional brain connectivity and the heterogeneity across subjects are neglected in most static graph fusion methods. This limits the ability of such frameworks to model variations at the sample or node level, resulting in suboptimal task performance in diverse clinical and demographic contexts.
Dynamic fusion paradigms, well-established in NLP and CV, have not been previously adapted effectively to graph-structured brain networks. The proposed M3D-BFS bridges this gap by using gating mechanisms and multi-expert ensembles to enable sample- and region-adaptive fusion.
Methodological Framework
Architecture and Fusion Strategy
M3D-BFS operates in three phases (Figure 2):
- Uni-modal Encoder Pretraining: Independent SC/FC graph convolutional encoders are pretrained for modality-specific representation learning, addressing modality laziness and facilitating stronger marginal encoders.
- Single Expert Pretraining: Each expert MLP for SC, FC, and Fusion is pretrained in isolation, using cross-entropy, contrastive, and knowledge distillation losses for robust alignment and regularization.
- MoE Finetuning: The core MoE blocks are fine-tuned with sample-adaptive gating, using the pretrained expert weights as initialization. Only the gates and experts are updated, with other network components frozen.
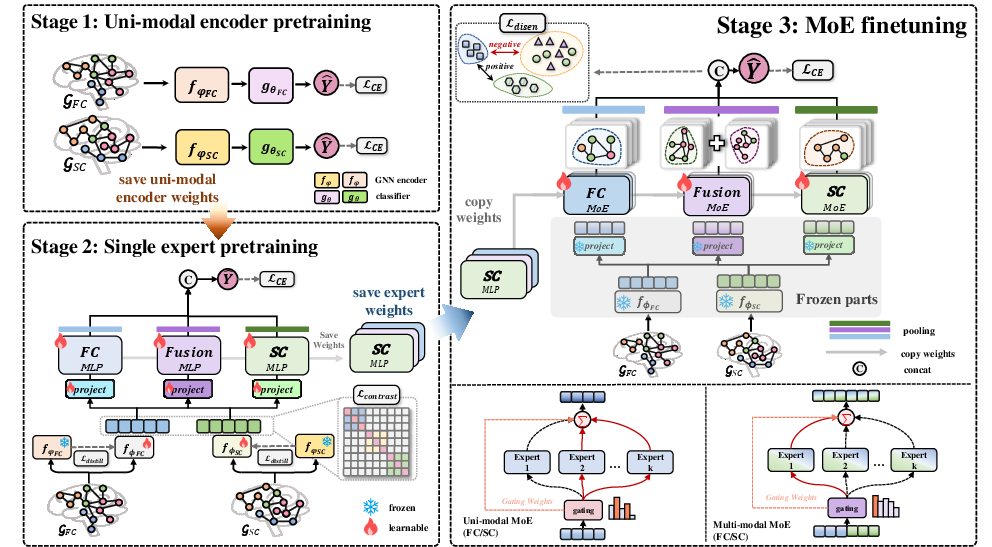
Figure 2: Overview of M3D-BFS: Three-stage training integrates unimodal and multimodal representations via dynamic MoE fusion blocks and disentanglement objectives.
During inference, the gating network routes representations for each node (brain region) to modality-specific or fusion experts on a per-sample basis, in a manner dependent on the input SC/FC graphs.
Losses and Regularization
- Distillation loss ensures that the multimodal encoders preserve information from unimodal pathways.
- Contrastive alignment (InfoNCE-based) maximally aligns paired SC and FC representations.
- MoE balancing loss (combining importance and load penalties) prevents expert collapse, forcing diverse expert utilization across samples and regions.
- Disentanglement loss encourages orthogonality among SC, FC, and fused embeddings, enhancing the informativeness of the final joint representations for downstream prediction.
Multi-Modal Brain Network Construction
The framework uses SC graphs constructed from dMRI tractography (AAL parcellation, fiber counts as edge weights, resulting in thresholded adjacency and node feature matrices) and FC graphs obtained from fMRI correlation matrices computed similarly.
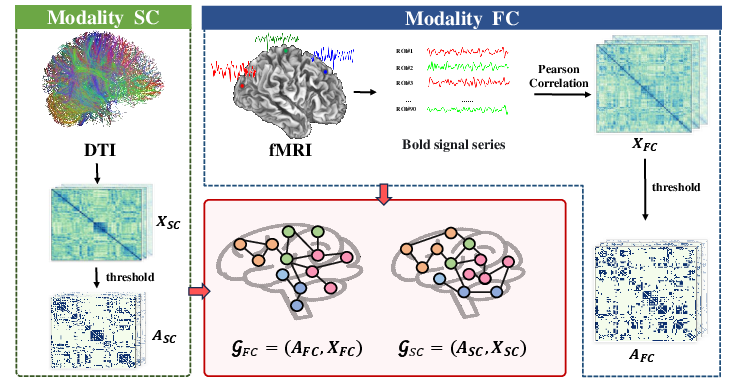
Figure 3: Construction process for multi-modal brain networks, resulting in SC and FC graphs with region-wise features.
Empirical Evaluation
Experimental Design
Experiments use two datasets:
Evaluation metrics include accuracy, sensitivity, specificity, F1, and AUC. Baselines comprise unimodal GCNs and transformers (BrainNPT), static fusion methods (SVM, Random Forest), representation-level and graph-level fusion (MMGNN, AL-NEGAT, Cross-GNN), and transformer-based fusion models (RH-BrainFS, NeuroPath).
Numerical Results
M3D-BFS yields the strongest numerical performance across all metrics on both datasets, e.g., 81.21% accuracy (HCP, +2.28% over Cross-GNN) and 80.85% accuracy (MDD, +2.73% over the next-best method). The improvement is consistent across sensitivity, specificity, and AUC, indicating robust generalization and clinical reliability.
Ablation and Sensitivity Analysis
Ablation demonstrates that each training stage and regularization component is critical for optimal accuracy and stability, with the multi-modal disentanglement loss further enhancing representation quality. Hyperparameter sweeps confirm architectural robustness, with little degradation for varying expert counts or regularization weights.
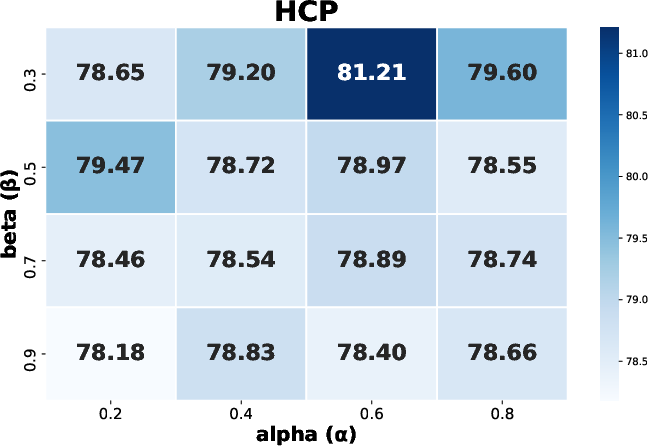
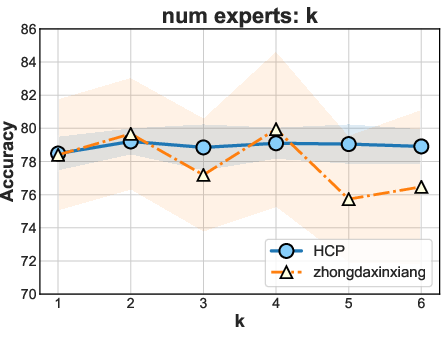
Figure 4: Sensitivity analysis indicating stable accuracy performance under hyperparameter perturbations and expert number variation.
Expert Utilization Visualization
Fusion block visualizations indicate that MoEs learn non-collapsed, balanced modality utilization without a dominant expert or degeneracy, in contrast to collapsed baselines. The per-node expert selection aligns with observed sample heterogeneity in brain networks.
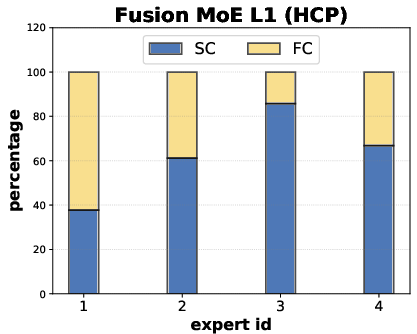
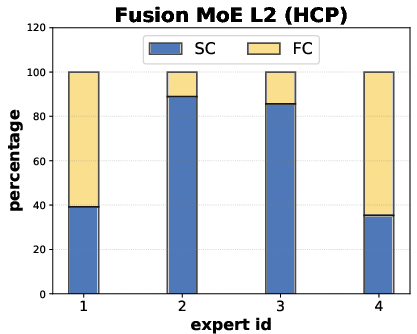
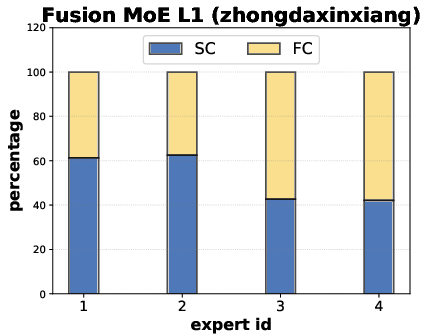
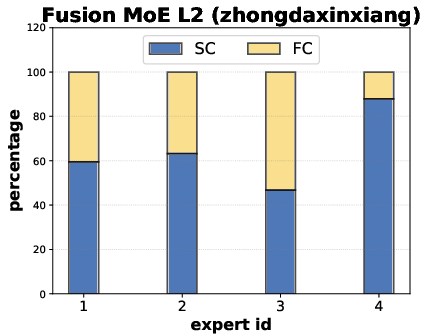
Figure 5: Fusion MoE blocks show balanced expert selection between SC and FC modalities across layers and samples.
Discussion and Theoretical Implications
This study establishes the efficacy of adaptive MoE fusion for brain network analysis. By integrating multiple stages of pretraining and constraint-driven optimization, M3D-BFS mitigates classic issues in multi-modal learning such as modality laziness, expert collapse, and insufficient label signal for disentangled embedding learning. Practically, the sample-specific routing of brain region features can better accommodate inter-subject variability—an essential property for translational neuroscientific and psychiatric applications. Theoretically, this framework unifies recent advances in dynamic fusion, contrastive alignment, and balanced expert training for multi-modal graphs.
Future Directions
Potential research avenues include:
- Extension to settings with more than two modalities or unequal graph structure across modalities.
- Adapting to tasks involving distributional shifts or demographic confounding.
- Exploration of dynamic fusion with more complex expert architectures and gating topologies.
Conclusion
M3D-BFS introduces a formal and scalable mechanism for dynamic, sample-adaptive fusion in multi-modal brain network analysis, overcoming the limitations of static fusion architectures. Its strong quantitative performance and ablation clarity underscore its utility as a foundation for next-generation clinical brain network modeling and neuroinformatics research.