- The paper demonstrates that Claude 3.7 Sonnet achieves the highest accuracy (≈0.91) with zero output mismatches for receipt-item categorisation.
- It employs a two-phase experimental design comparing zero-shot and few-shot prompting, highlighting the benefits of rule-based engineering for cost-effective classification.
- Refined rule-based prompts result in improved strict (≈93%) and lenient (≈96%) accuracy while controlling token costs compared to example-augmented strategies.
Systematic Evaluation of LLMs for Receipt-Item Categorisation on AWS Bedrock
Introduction
This paper presents a structured, cost-driven evaluation of instruction-tuned LLMs available in AWS Bedrock for receipt-item categorisation. The analysis encompasses four production-ready models: Claude 3.7 Sonnet, Claude 4 Sonnet, Mixtral 8x7B Instruct, and Mistral 7B Instruct, with evaluation focused on accuracy, stability, runtime, and token-level cost for real-world expense-item classification. The work further investigates the comparative efficacy of zero-shot and few-shot prompting in this domain.
Methodology
The study comprises a two-phase experimental design. In Phase 1, all four models are benchmarked using an identically curated dataset of 389 Australian receipt items, mapping input blocks to a canonical category taxonomy. Evaluation followed a schema-first, black-box approach, enforcing identical prompts across all models (modulo provider formatting constraints) and focusing on array-level consistency to reduce hallucinations and constraint violations.
In Phase 2, prompt refinements were introduced solely for the Claude 3.7 Sonnet model—the strongest Phase 1 performer—testing the effects of (1) category set updates, (2) rule-based disambiguation heuristics, and (3) embedding of few-shot examples. Strict and lenient label matching schemes were used to reflect label ambiguity. All model invocations occurred via local scripts using the unified AWS Bedrock InvokeModel API to ensure reproducibility and fine-grained cost analysis.
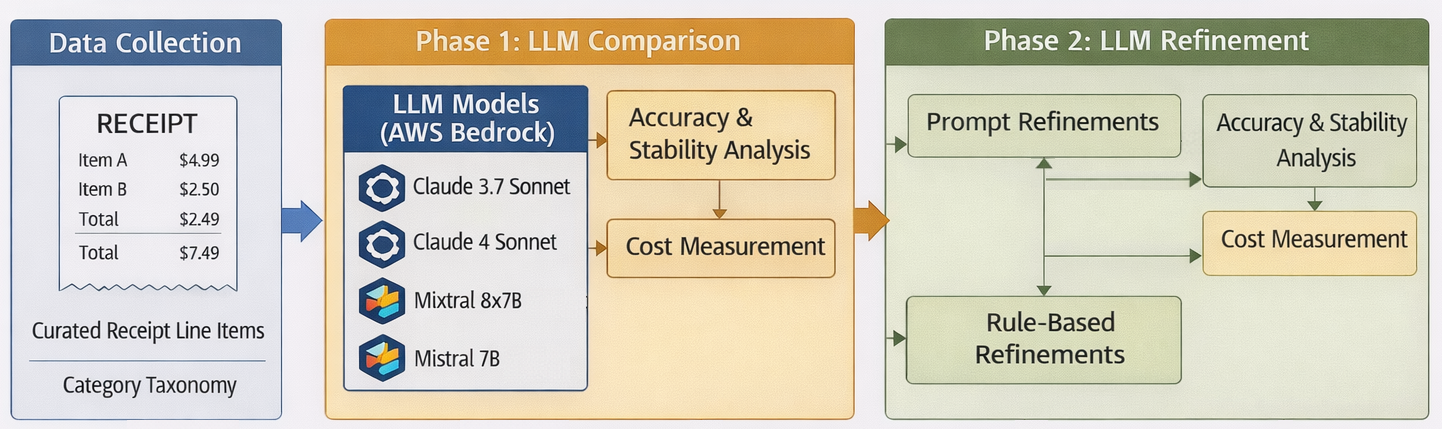
Figure 1: Overview of the Phase 1 and Phase 2 experimental methodology and workflow.
Comparative Model Results
Phase 1: Model Family Comparison
Claude 3.7 Sonnet delivers the strongest results across all accuracy and reliability metrics, with 0.90–0.91 overall accuracy, 0.91 precision, 0.90 recall, and 0% array-length mismatches, outperforming both Claude 4 Sonnet and the open-weight Mixtral and Mistral models (Accuracy: 0.60–0.70; Mismatch rates: up to 9.3%). While Mixtral and Mistral exhibit lower mean runtimes (Mixtral: 431 ms), their outputs are more frequently malformed, displaying hallucinations and boundary violations more often than Claude models, especially in low-support or ambiguously defined categories.
Token analysis (Claude models only) demonstrates operational costs of ∼0.004 USD/inference (250 inferences/USD), with output stability across prompt variants. The Claude models are marginally slower (1265 ms for Claude 3.7 vs. 431 ms for Mixtral 8x7B) but provide robust, schema-conformant output structures.
Phase 2: Prompting Strategy Refinement
Refined prompting significantly enhances classification performance. Incorporating stricter category boundaries and rule-based disambiguation (Variant 3, zero-shot) increases overall strict accuracy to 93% and lenient accuracy to 95.6%, while boosting balanced accuracy ~6–8 points over the Phase 1 baseline. Few-shot prompting (Variant 4) increases token costs and latency (∼2.5x baseline), yet does not yield further accuracy benefits, indicating that explicit heuristics are more effective for this task than example-based augmentation. Category-specific analysis shows error reductions at boundary cases (e.g., refrigerated vs. pantry items), and only marginal changes in ambiguous domains (e.g., drinks).
Token usage is the primary cost driver; Variant 3 nearly doubles the average per-call cost compared to the baseline yet remains within reasonable production bounds.
Results and Claims
- Claude 3.7 Sonnet offers the highest accuracy, zero hallucinated/malformed outputs, and predictable inference cost compared to both proprietary (Claude 4) and open-weight (Mixtral, Mistral) alternatives.
- Zero-shot prompting with schema-first/rule-based engineering produces superior cost–accuracy trade-offs compared to few-shot prompting, which incurs additional computational overhead without yielding further classification gains.
- Updated, fine-grained categories and explicit prompt rules yield strict F1 ≈ 0.93 and lenient F1 ≈ 0.96 on the curated dataset (389 items, 27 categories).
- Open-weight models compromise output stability, with frequent label array mismatches and reduced parseability, even at faster average runtimes.
Implications, Limitations, and Future Directions
This analysis provides strong, actionable guidance for production LLM selection via AWS Bedrock for fine-grained financial document categorisation. It demonstrates that, given current API ergonomics and provider models, closed-source LLMs (specifically Claude 3.7 Sonnet) are more robust and cost-predictable for strict schema adherence under practical constraints. Zero-shot approaches augmented with precise rules are adequate for high-Benchmark accuracy, negating the need for expensive example-driven approaches in contexts with clear labels.
The study’s limitations include dataset bias and absence of diverse receipt/vendor representations. Expansion to broader domains, cross-lingual setups, or OCR-error tolerance was not addressed and remains open for subsequent research.
Looking forward, continued improvements in prompt-constraint adherence of open-weight models could yield cost-efficient, robust alternatives. Further exploration of dynamic prompting (e.g., context-dependent rule-switching) or automated prompt tuning could also extend the practical applicability of these findings. Investigation into semi-supervised and active learning pipelines with human-in-the-loop revision for ambiguous or low-support categories is warranted.
Conclusion
Claude 3.7 Sonnet, when deployed with schema-first, rules-based zero-shot prompting and an updated, domain-specific category taxonomy, provides the optimal cost–accuracy solution for AWS Bedrock production receipt-item categorisation. Open-weight models lag in reliability and structural compliance. Prompt refinement, particularly rule-driven ambiguity minimisation, is more effective than few-shot augmentation in this text classification setting. These findings establish a robust template for deploying LLM-based classification pipelines in transactional financial document analysis.

