- The paper shows that voice cloning systems maintain computational speaker similarity but struggle to capture accent-specific nuances.
- It employs embedding analysis and perceptual ratings to compare performance on standard versus heavily accented Mandarin speech.
- Findings indicate that while accent attenuation improves intelligibility, it compromises perceived speaker identity in the clones.
Acoustic and Perceptual Divergence in Voice Cloning of Standard and Accented Mandarin Speech
Introduction
This essay details the empirical investigation and findings from "Acoustic and perceptual differences between standard and accented Chinese speech and their voice clones" (2604.01562). The paper critically evaluates the preservation of accent-related attributes and perceived speaker identity in cloned Mandarin speech, contrasting standard accent and heavy regional accent conditions using both computational and perceptual methodologies. Three commercial voice cloning systems—ElevenLabs, MiniMax, and AnyVoice—serve as the testbed, and ECAPA-TDNN speaker embeddings offer computational grounding. The results elucidate boundaries of current voice cloning systems in preserving identity and intelligibility across accent variability and propose the necessity of disentangling speaker and accent preservation in evaluation paradigms.
Experimental Design
The experimental protocol integrates computational analyses of speaker similarity in embedding space with perceptual evaluation of speaker identity and intelligibility. The database includes standard Mandarin (AISHELL-3) and heavy-accent Mandarin (Mandarin Heavy Accent Speech Corpus) source material. Clones were synthesized using identical 20-second speaker enrollment intervals for all systems, with consistent preprocessing for both original and cloned tokens. Tokenization for embedding analysis utilizes a sliding 3-second window, with energy-based VAD to enforce speech frame quality.
Participants (N=67, following exclusion) were native Mandarin listeners, completing online perceptual tasks rating speaker similarity and intelligibility for original and cloned pairs. All data processing decisions emphasize consistency for robust comparison at the model and human perceptual level.
Embedding-based Analysis
The core computational component quantifies speaker similarity using cosine distances from ECAPA-TDNN embeddings, calculating mean original–clone distance (dOC) and clone-divergence (Δdiv) for both accent categories and three cloning systems.
Clones generated by AnyVoice and MiniMax exhibited negligible divergence from originals in embedding space, both for standard and accented speech, with clone-divergence means indistinguishable from the original–original baseline. ElevenLabs, in contrast, showed significant clone divergence for both accent conditions (estimates ≈0.21, Holm-adjusted p<10−4), but crucially, there was no significant difference in clone-divergence between standard and accented speakers for any system after correction for multiple comparisons.
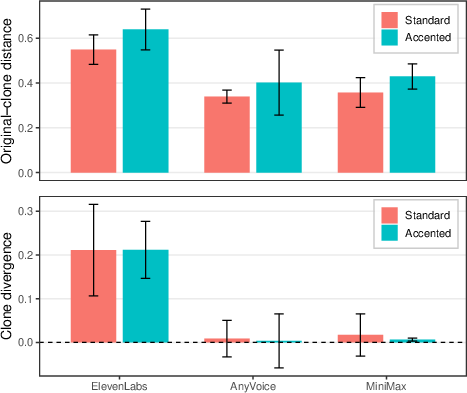
Figure 1: ECAPA-TDNN cosine distances (dOC and Δdiv) between original and cloned speech for standard and accented Mandarin, highlighting system variability and minimal accent-induced shift in embedding space.
This system-dependent but accent-invariant divergence at the embedding level demonstrates that commercial speaker representations may lack sensitivity to accent-induced phonetic structure when evaluating voice cloning fidelity, particularly in models optimized for speaker discrimination rather than accent discrimination.
Perceptual Evaluation
The perceptual study targeted two orthogonal dimensions: perceived speaker similarity (identity match) and intelligibility gains induced by cloning.
Speaker Similarity
Similarity ratings, rendered on a 5-point ordinal scale, were modeled using cumulative link mixed models. While AnyVoice and MiniMax had generally higher perceived similarity than ElevenLabs, across systems, clones of standard accent speech were consistently rated as more similar to their sources than clones of heavily accented speech. This effect was pronounced in AnyVoice and MiniMax (Δ on logit scale 1.2–1.3, Holm-adjusted p<0.02) and held in aggregate across systems.
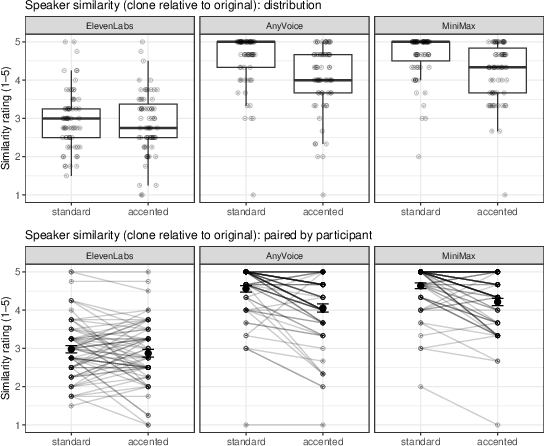
Figure 2: Listener-rated speaker similarity between clones and their respective originals; standard accents yield higher similarity than heavy accents, particularly in AnyVoice and MiniMax outputs.
This aligns with human listeners integrating accent information into identity judgments, resulting in increased perceived mismatch for cloned variants of accented speech—even when embedding-based measures do not reflect such a divergence.
Intelligibility
Intelligibility was indexed via within-listener gain scores, comparing clones directly to their respective originals. Statistically significant intelligibility improvement was observed for all clones (β^=2.02, z=8.48, p<2×10−16), with a larger intelligibility gain for heavily accented speech (interaction Δdiv0, Δdiv1), and no significant variation between systems.
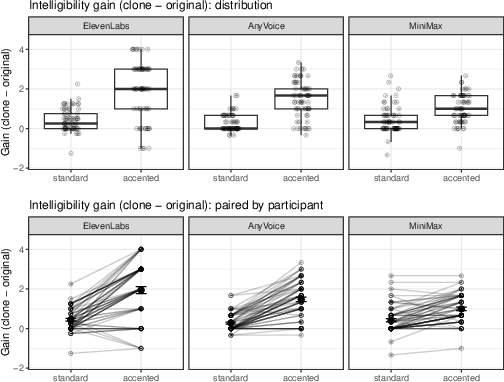
Figure 3: Listener-rated intelligibility gain for each clone relative to the matched original, demonstrating larger gains for heavy accent compared to standard speech.
This suggests that cloning systems, while often smoothing or regularizing phonetic attributes, disproportionately enhance comprehension for speech with heavy accent, plausibly by attenuating accent-related articulatory variation that impedes intelligibility.
Implications and Future Directions
The dissociation between embedding-derived speaker space and perceptual judgments highlights critical limitations of current evaluation practices:
- Accent preservation and speaker identity preservation must be treated as separable evaluation targets. Embedding models may not encode accent features salient to human listeners; over-reliance on such metrics risks overestimating speaker similarity when accent divergence is nontrivial.
- Intelligibility gains for accented speech indicate that voice cloning carries both accessibility benefits and identity risks: clones may increase comprehensibility yet yield less faithful perceived identity matches for accent-differentiated speakers.
- These findings necessitate the advancement of accent-sensitive embeddings or multidimensional evaluation frameworks capturing both speaker and accent fidelity.
- The testbed and protocols established in this study can guide large-scale, language-general assessments and benchmarking of future cloning architectures, especially as generative models are increasingly deployed in forensic and accessibility-sensitive contexts.
- Explicitly measuring and calibrating the degree of accent “attenuation” versus preservation represents a salient open problem in robust and ethical deployment of cloned voice technologies.
Conclusion
This work demonstrates that while contemporary commercial voice cloning systems preserve speaker identity with high computational fidelity, accent-related differences are more pronounced in perceptual than embedding-based judgements. Voice clones of heavily accented speech are judged as less similar to their sources, despite not exhibiting marked computational divergence, yet provide larger intelligibility gains, supporting a functional accent-attenuation model. These results underline the need for new evaluation paradigms considering the separability of accent and speaker identity, with direct implications for both practical deployment and theoretical modeling of speech generation systems.

