- The paper presents EXHIB, a novel benchmark that standardizes the evaluation of binary function similarity by categorizing low-, mid-, and high-level differences.
- The paper benchmarks nine models across five datasets, exposing significant performance drops especially in obfuscated and semantically diverse binaries.
- The paper highlights the need for dynamic analysis and improved representation learning to overcome the limitations of current static BFSD techniques.
EXHIB: A Benchmark for Realistic and Diverse Evaluation of Function Similarity in the Wild
Problem Motivation and Taxonomy of Binary Function Similarity
Binary Function Similarity Detection (BFSD) underpins critical tasks in software security, including vulnerability analysis, lineage tracking, malware classification, and patch provenance. However, prevailing approaches and their reported results are challenging to compare due to the lack of a standardized, comprehensive benchmark. Existing datasets are myopic—dominated by synthetically compiled code with limited diversity in compilers, optimization levels, architectures, and only superficial coverage of real-world binaries, obfuscations, and semantic variations. As elucidated in the paper, this undermines scientific reproducibility and gives a false impression of model robustness.
To address this, the authors construct a three-level taxonomy that delineates the root causes of function-level differences in binaries:
- Low-level differences: Induced by architecture, bitness, compiler versions, and optimization levels.
- Mid-level differences: Attributed to semantic-preserving obfuscations (e.g., control-flow flattening, instruction substitution).
- High-level differences: Arise from independently developed implementations with equivalent semantics yet diverging structure, control flow, and data abstraction.
This taxonomy reveals that previous evaluations overwhelmingly concentrate on low-level variation, significantly underestimating the difficulty of high-level and obfuscation-induced changes. The problem is visualized formally in the BFSD pipeline (Figure 1).
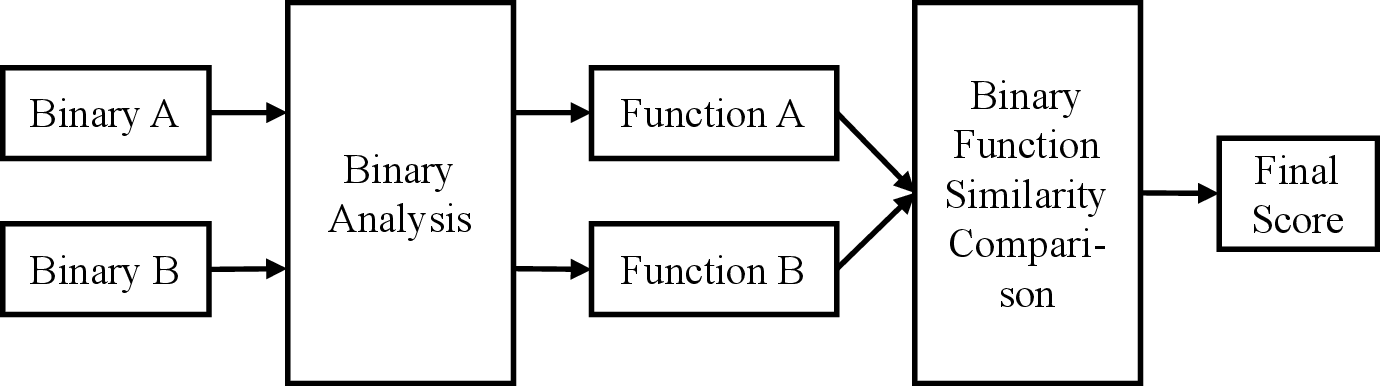
Figure 1: Definition of the BFSD problem—two binary functions are mapped, through analysis and representation, to a similarity score for downstream security tasks.
Benchmark Contributions: EXHIB Dataset Suite
The EXHIB benchmark comprises five datasets, each designed to systematically cover the diversity in the proposed taxonomy:
- Standard Dataset: Large-scale open-source projects (e.g., binutils, coreutils, ffmpeg) cross-compiled (multiple architectures, compiler versions, optimization flags) to probe low-level robustness.
- Firmware Dataset: Samples from multiple vendor SDKs and toolchains (e.g., Keil MDK-ARM, Simplicity Studio), reflecting real-world embedded systems which challenge models with complex architectural and toolchain-induced variance.
- Malware Dataset: Curated from public malware repositories, this dataset includes Linux and IoT malware samples subjected to compiler and optimization variation.
- Obfuscation Dataset: Binaries from diverse open-source sources subject to strong source- and IR-level obfuscations, including Obfuscator-LLVM, Hikari, and Tigress transformations.
- Semantic Dataset: Collected from programming contest submissions (AtCoder), featuring independent, correct implementations of the same functional specification, isolating high-level semantic variation.
Each dataset split, as well as the underlying task variables (architecture, bitness, compiler, obfuscation, semantics), is meticulously systematized.

Figure 2: Systematization of BFSD approaches, methods, and dataset coverage in the landscape.
This benchmark not only supports classical and modern machine learning solutions but also exposes limitations of current paradigms by including real firmware, advanced obfuscation, and semantically diverse programs.
Methodology and State-of-the-art Model Evaluation
Nine representative models across the main methodological axes are benchmarked: fuzzy hashing (FCatalog, FunctionSimSearch), graph-based (Gemini, HermesSim), NLP-based token/sequence/transformer (Asm2Vec, SAFE, Trex), and hybrids (Massarelli et al., Zeek). Uniform extraction and processing protocols are employed to remove confounding measurement variables.
Key results are as follows:
- On the Standard Dataset, several models report high AUC (HermesSim: 1.00, Gemini: 0.96-0.98) due to limited cross-compiler/arch difficulty.
- Firmware and Malware Datasets: Performance degrades, with AUC typically dropping 10-20% (HermesSim: 0.99-1.00; Gemini: 0.89-0.99), highlighting limited generalization to wild binaries and real toolchains.
- Obfuscation Dataset: Most models exhibit a further 5-10% AUC loss; HermesSim remains robust (AUC: 1.00), but other models (FunctionSimSearch, Asm2Vec) drop to intermediate performance.
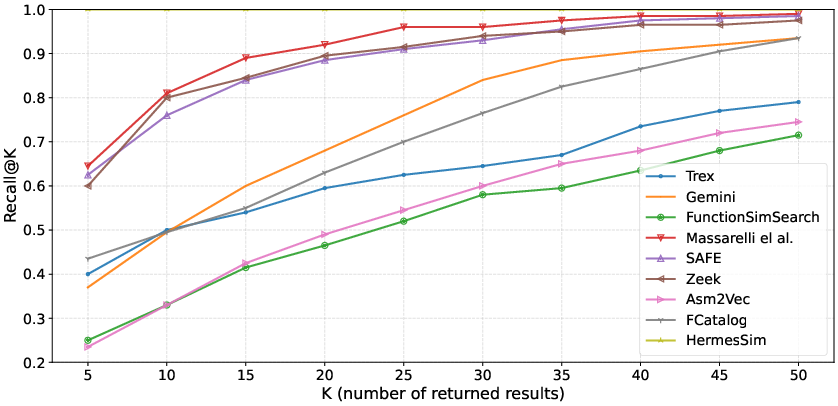
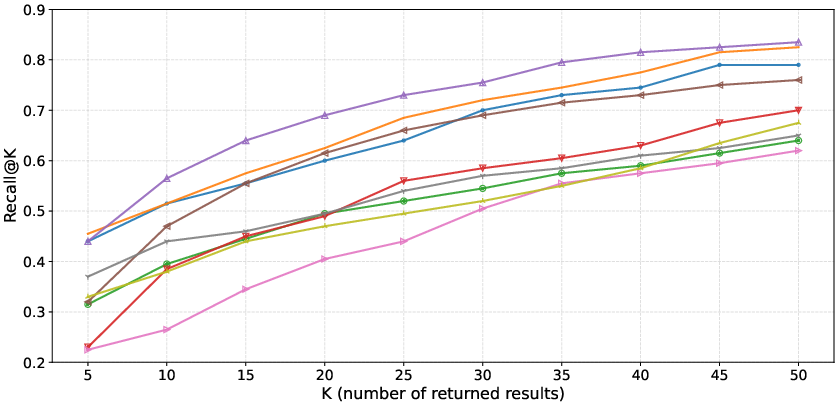
Figure 3: Recall as a function of K for the Obfuscation Dataset, demonstrating steep declines for models not incorporating structure and semantics.
- Semantic Dataset: All models exhibit strong performance collapse (HermesSim: 0.70, Trex: 0.82, SAFE: 0.86). The gap between positives and negatives narrows drastically (Figure 4), manifesting in low recall and MRR values. Notably, HermesSim, the best performer elsewhere, is outperformed by Trex and SAFE on high-level semantic variation—demonstrating that SOG/CFG-based approaches cannot capture functional equivalence under major implementation divergence.
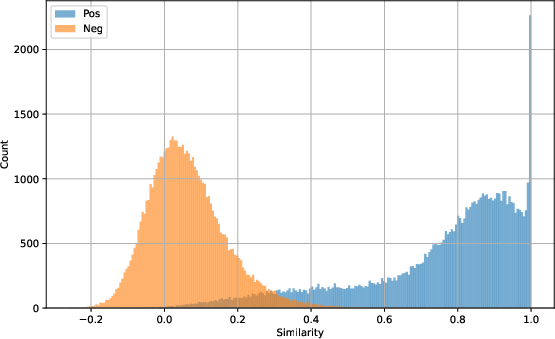
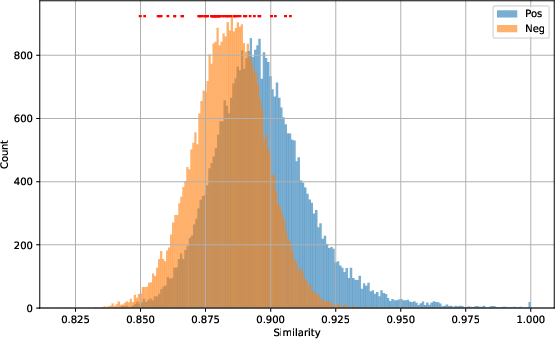
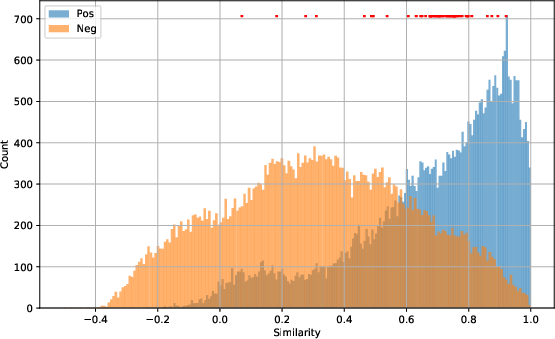
Figure 4: HermesSim's similarity distribution on the Standard Dataset (separated peaks for positives/negatives), contrasted with severe overlap on the Semantic Dataset, indicating reduced discriminative power under semantic change.
Analysis: Limitations and Implications
The main results highlight several critical findings:
- Robustness does not generalize across taxonomy levels. Claims of efficacy under cross-compilation or obfuscation settings do not transfer to the high-level semantic setting. This exposes the inadequacy of using low-level diversified datasets as a sole proxy for practical robustness in real-world binary analysis.
- Graph-based methods, specifically SOG and ACFG approaches, are the most performant on low-/mid-level transformations but falter in the presence of structural and implementation-level semantic diversity.
- Dynamic analysis (as found in Trex) enhances resilience to semantic gap, suggesting that static features are insufficient for true functional equivalence detection when source-level variance is substantial.
- Classical approaches (FCatalog, fuzzy hashing) remain computationally attractive but are no longer competitive on challenging tasks.
Theoretical implications include the need to rethink representation learning architectures for BFSD; static token/graph approaches have an upper bound on attainable performance under real semantic drift. Practically, this advises caution in tool deployment: models reputedly robust in academic benchmarks may underperform in wild binaries or adversarial scenarios.
Case Study: Semantic Misclassification
An in-depth case on the programming contest dataset reveals that SOG representations fail when two functions solving the same problem deploy disparate algorithms—HermesSim fails to recognize similarity where only dynamic, behavioral signatures reveal equivalency. Visualizations of SOGs for such function pairs (Figure 5) demonstrate structural divergence as the failure point of structure-centric models.
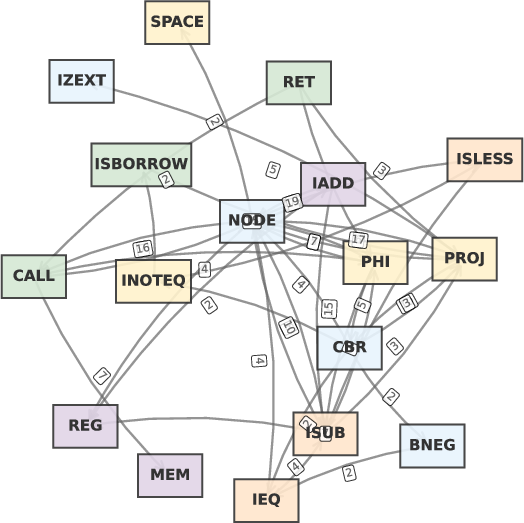
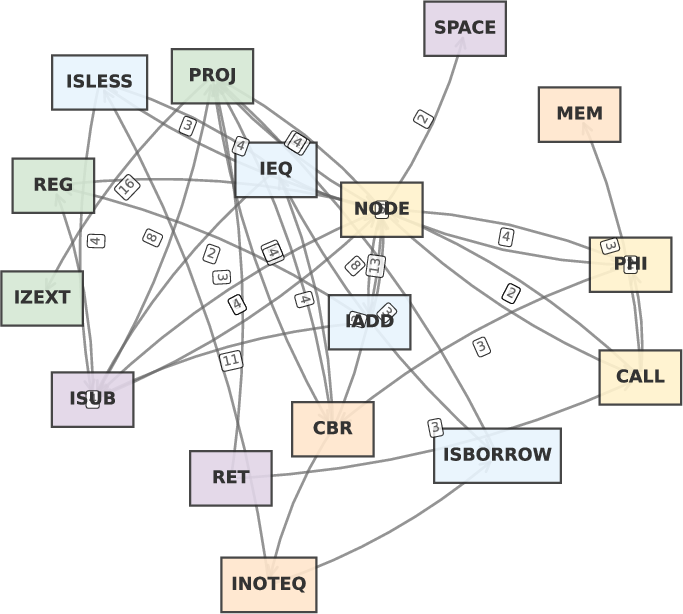
Figure 5: SOG representations for two semantically equivalent, structurally divergent functions—clearly non-matching despite equivalent behavior.
Future Directions
Advancing beyond EXHIB's contributions, several research thrusts are critical:
- Benchmark expansion: Incorporating binaries from additional languages, platforms, and emerging obfuscation techniques.
- Cross-format, cross-language function similarity detection: Evaluating and developing representations invariant to calling conventions, ABI, and language-specific idioms.
- Hybrid static-dynamic analysis at scale: Exploiting dynamic instrumentation as in Trex, but with better scalability and automation.
- Domain adaptation and adversarial robustness: Explicitly evaluating the impact of adversarial code generation on similarity detection to stress-test models.
Conclusion
EXHIB sets a new standard for benchmarking in binary function similarity evaluation, highlighting the disconnect between current benchmarks and real-world security requirements. The comprehensive taxonomy, datasets, and cross-paradigm evaluation reveal model vulnerabilities under semantic and obfuscation drift, refuting the presumption of universal robustness. The field must now address semantic abstraction and leverage dynamic properties, pursuing models and benchmarks that reflect realistic, future-proof function similarity scenarios.