- The paper introduces a latent similarity mining method using diffusion models to capture domain-invariant vascular structures and improve segmentation metrics.
- It employs an iterative co-optimization loop between image generation and segmentation, effectively reducing domain discrepancies and enhancing performance.
- The approach achieves state-of-the-art results on FP to OCTA adaptation by preserving fine vascular details and significantly boosting DSC and AUC scores.
Latent Similarity Mining and Iterative Co-Optimization for Cross-Domain Retinal Vessel Segmentation
Introduction
Retinal vessel segmentation is critical for automated retinal pathology diagnosis and screening. However, segmenters such as CNN-based architectures exhibit marked performance degradation under substantial cross-domain shifts, particularly when the source and target domains differ in acquisition modality (e.g., Fundus Photography [FP] vs. Optical Coherence Tomography Angiography [OCTA]). This domain shift is characterized by substantial intensity distribution changes and distinctive appearance discrepancies while preserving local vascular semantic structures. Unsupervised domain adaptation (UDA) methods, ranging from pseudo-labeling to adversarial approaches, typically exhibit limited efficacy in this context due to either overreliance on initial label quality or insensitivity to fine-grained vascular morphology.
"Cross-Domain Vessel Segmentation via Latent Similarity Mining and Iterative Co-Optimization" (2604.01553) addresses these challenges by introducing a novel framework that leverages domain-invariant latent structural representations enabled by diffusion models, combined with an iterative co-optimization loop between image generation and segmentation. The method demonstrates robust generalization capacity on challenging clinical datasets with large modality gaps.
Methodology
The proposed approach comprises three components: 1) diffusion model-based generative pre-training, 2) latent similarity mining via deterministic DDIM inversion, and 3) iterative co-optimization between the conditional generator and segmentation network.
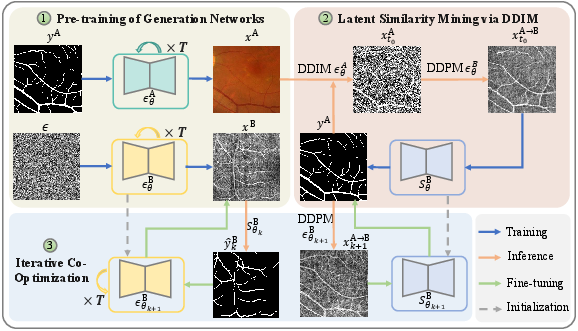
Figure 1: An overview of the cross-domain vessel segmentation framework, illustrating joint latent mining, image generation, and segmentation feedback.
Diffusion Model Pre-Training and Latent Representation
A conditional Denoising Diffusion Probabilistic Model (DDPM) is pre-trained on the source domain to capture vascular structure distributions, leveraging labeled FP images. An unconditional DDPM is also trained on unlabeled OCTA target images. Using DDIM-based deterministic inversion, source images are projected into semantic latent representations preserving vascular geometry under the guidance of source labels. These latent codes, being domain-agnostic, function as structure-preserving prototypes for synthesis in the target domain.
Cross-Domain Synthesis via Latent Similarity Mining
Latent vascular codes from the source domain undergo a reverse denoising process in the target domain's generative model, producing pseudo-OCTA samples that retain source-style vessel annotations. This process enables the transfer of annotated vascular structure across domains, providing target-style images paired with high-fidelity vascular masks.
Iterative Co-Optimization
Initial pseudo-OCTA images and associated vessel annotations train a target-domain segmentation network. Iterative co-optimization alternates between segmentation and generation: the improved segmenter produces refined masks for real target images, further supervising the conditional generator, which subsequently synthesizes higher-fidelity target-style vascular images to re-train the segmentation network. This cycle progressively reduces domain discrepancies and enhances performance.
Experimental Results
The framework was evaluated using FP (FIVES) as the labeled source and OCTA (OCTA-500, ROSE) as the unlabeled target. The primary metrics were DSC, AUC, ACC, and Average Hausdorff Distance (AHD).
Quantitative Outcomes
The final system achieved state-of-the-art results across both datasets, significantly outperforming competing UDA methods:
- On OCTA-500, the DSC improved from 6.56% (in-domain UNet) and 69.02% (initial iteration) to 78.33% after co-optimization, with analogous gains in AUC and reduced AHD.
- On ROSE, the DSC increased to 75.28%, exceeding previous methods by up to 8.4% absolute DSC, with concurrent gains in AUC and reduced false-positive rates.
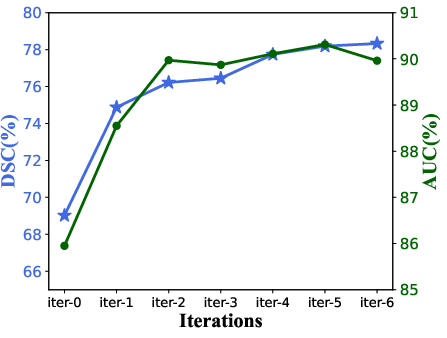
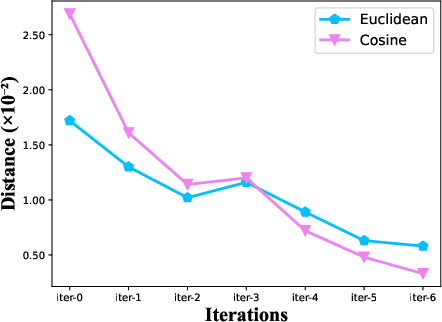
Figure 2: Evolution of DSC and AUC over iterative optimization rounds, illustrating consistent performance gains and convergence.
The iterative loop provided substantial improvements, especially during early iterations, highlighting the impact of generator–segmenter feedback. Latent similarity mining reduced cross-domain Euclidean and cosine distances in image intensity distributions by 83.3% and 94.7%, respectively, demonstrating highly effective domain alignment even before iteration.
Qualitative Analysis
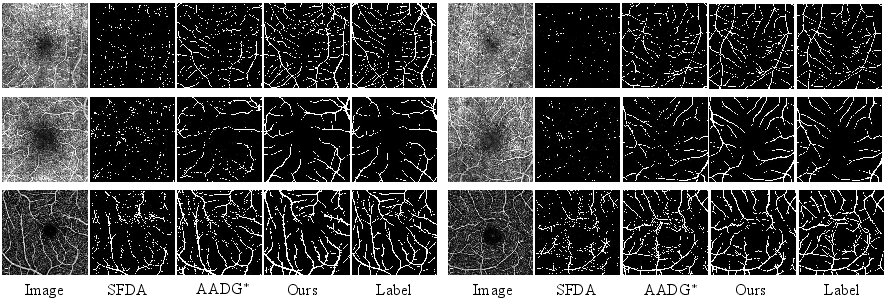
Figure 3: Qualitative comparison of segmentation results for OCTA-500 and ROSE, showcasing fine structure preservation and domain alignment for both main and capillary vessels.
The method consistently preserved fine vascular connectivity and achieved sharper vessel boundary predictions, while alternative UDA approaches suffered from broken or diffuse segmentation contours, reflecting superior structural alignment.
Theoretical and Practical Implications
This work demonstrates that leveraging deterministic diffusion-based latent representations, rather than explicit pixel-space domain adaptation, allows fine-grained, domain-agnostic semantic transfer. The co-optimization protocol mitigates modality gaps and enables effective utilization of unlabeled data, overcoming pitfalls of classical pseudo-labeling and GAN-based approaches. Notably, the method avoids reliance on initial segmentation quality, reinforcing robustness in the presence of strong domain bias.
Practically, this approach can be extended to additional cross-modality or multi-domain biomedical imaging tasks that require domain-robust segmentation, especially where labeled data is scarce in the target domain and morphological structure invariance can be exploited.
Future Directions
The current framework could be generalized to handle multiple source/target domains, hierarchical anatomical structures, or extended to fully end-to-end training by integrating latent code alignment objectives. Further, exploration into more expressive backbone architectures or integration with transformers and multi-resolution fusion modules could enhance cross-domain generalization. Scaling to larger and more diverse datasets would also solidify its clinical robustness.
Conclusion
This work introduces a principled methodology for unsupervised cross-domain vessel segmentation that exploits latent structural similarity via diffusion model inversion and optimizes generation–segmentation interaction through a cyclic, iterative process. The resulting system achieves superior segmentation robustness under severe domain shifts, preserving fine vascular morphology and outperforming state-of-the-art UDA methods. Extensions of this paradigm offer promising prospects for robust, generative domain adaptation in multi-modal medical imaging and other structurally-rich domains.